CARGAS DE TRABALHO
o Snowflake para Data Engineering
Construa pipelines de dados avançados, em lote e em streaming, em SQL ou Python.




Simplifique os complexos requisitos de engenharia de dados
Construa pipelines de dados em lote e em streaming em uma única plataforma, utilizando todo o potencial dos pipelines declarativos e de atualizações incrementais econômicas.
Elimine pipelines desnecessários com o Data Sharing
Acesse dados ativos, prontos para uso, diretamente de milhares de conjuntos de dados e aplicativos por meio do Snowflake Marketplace, sem a necessidade de criar pipelines.
Crie códigos na linguagem de sua preferência em um mecanismo otimizado
Programe em Python, SQL, entre outras linguagens. Em seguida, execute o código com a computação multicluster do Snowflake. Sem precisar ter uma infraestrutura separada.
Como funciona
Transmita dados com latência inferior a 10 segundos
Geralmente mantidos separados, os sistemas de streaming e de lote são complexos de gerenciar e caros de dimensionar. No entanto, o Snowflake simplifica esse processo, ao lidar tanto com a ingestão quanto com a transformação de dados em lote e em streaming em um único sistema.
Com o Snowpipe Streaming, transmita dados de conjuntos de linhas quase em tempo real, com latência baixa (de dígito único), ou faça a ingestão automática de arquivos com o Snowpipe. As duas opções sem servidor oferecem melhor escalabilidade e eficiência de custos.

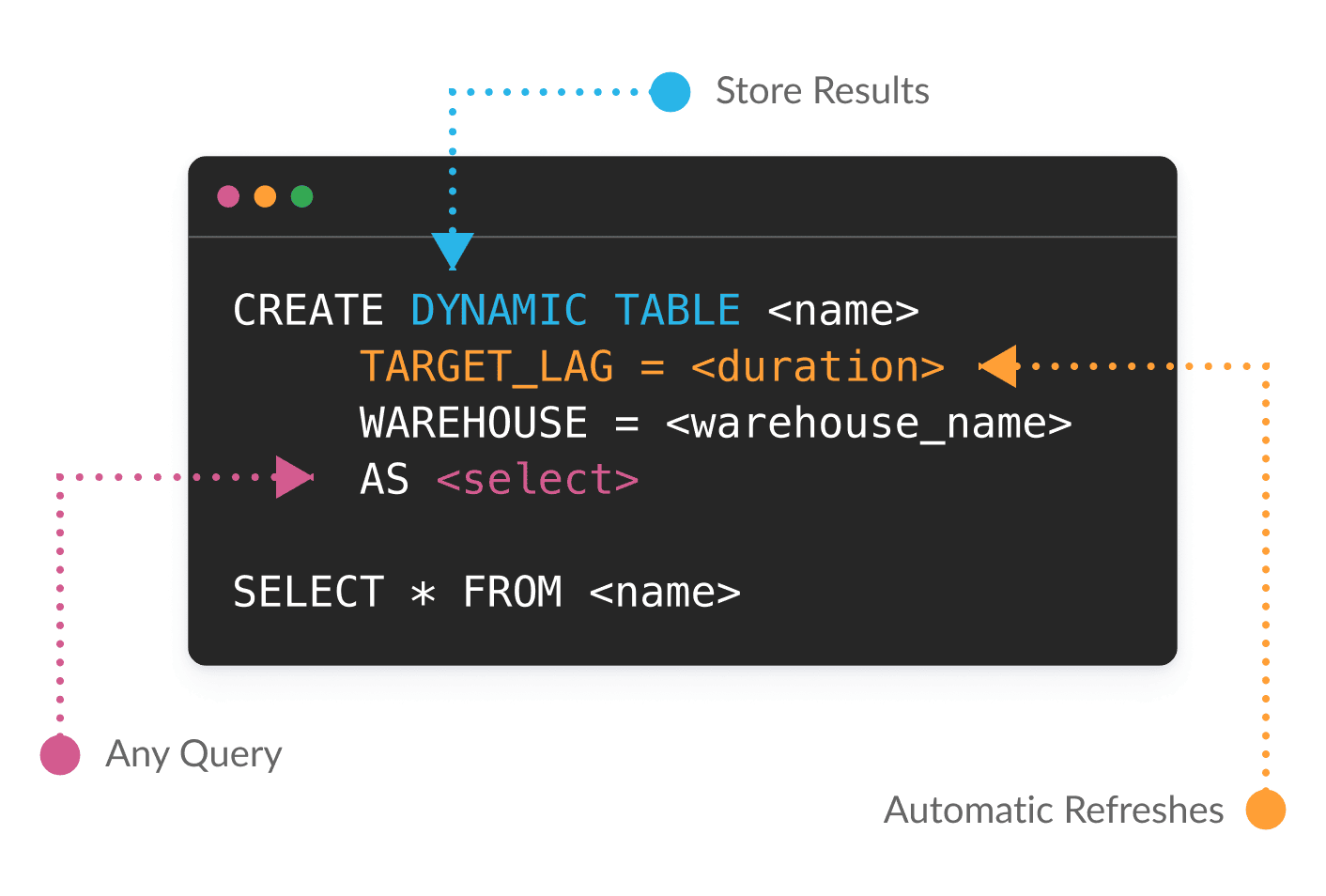
Ajuste a latência com uma única alteração de parâmetro
Com Dynamic Tables (em versão preliminar pública), é possível usar SQL ou Python para definir as transformações de dados de forma declarativa. O Snowflake gerencia as dependências e materializa os resultados automaticamente, com base em suas metas de atualização. Com o objetivo de tornar os grandes volumes de dados e os pipelines complexos mais simples e econômicos, as Dynamic Tables operam somente nos dados que foram alterados desde a última atualização.
À medida que as necessidades de negócios mudam, é possível adaptar facilmente, transformando um pipeline em lote em um pipeline de streaming com uma única alteração no parâmetro de latência.
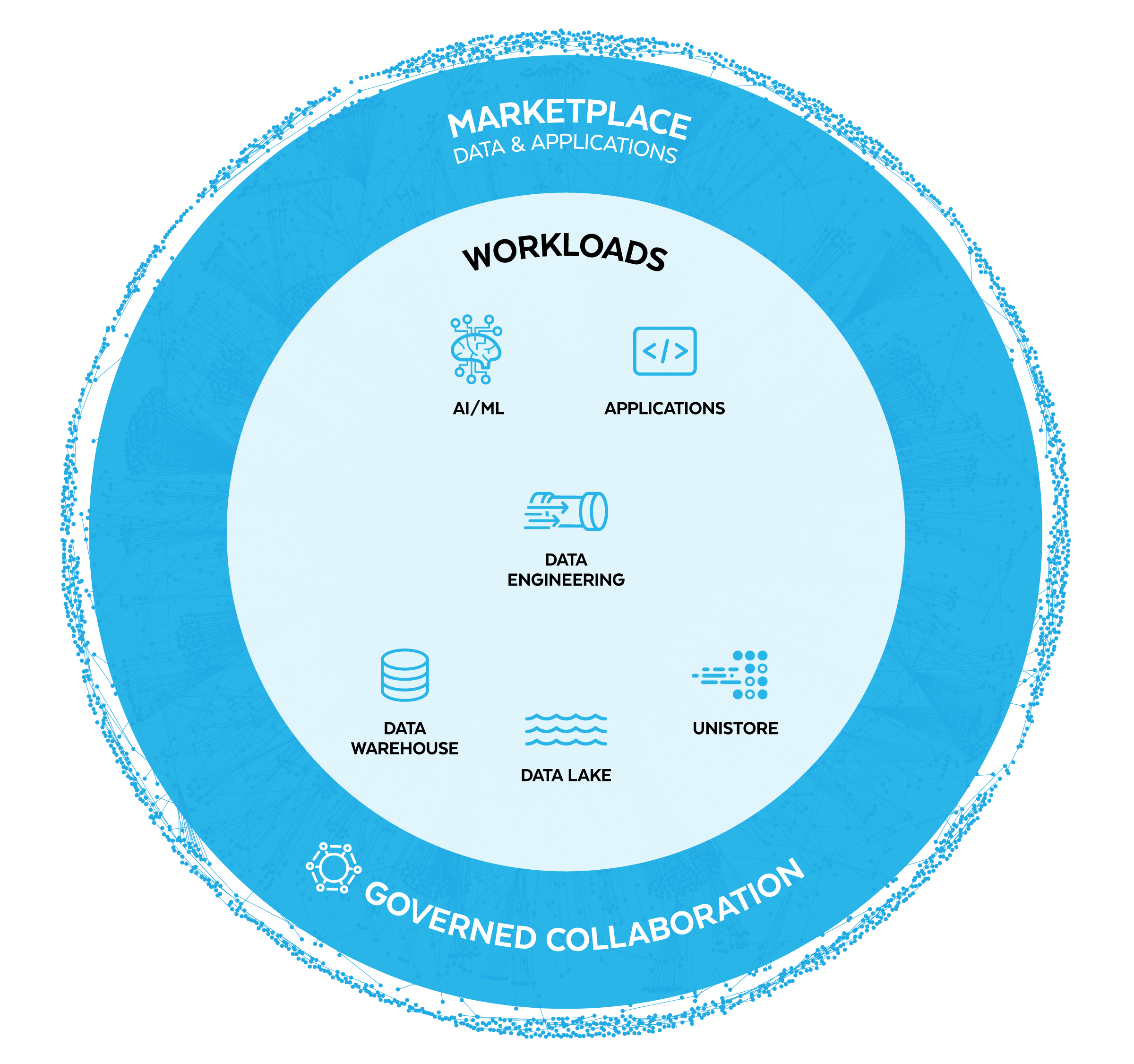
Reforce a engenharia de dados para análises, IA/ML e aplicativos
Leve suas cargas de trabalho até os dados para simplificar a arquitetura do pipeline e eliminar a necessidade de uma infraestrutura separada.
Aplique o seu código aos dados para atender a diversas necessidades de negócios, desde a aceleração da análise de dados até a criação de aplicativos para utilizar todo o poder da IA generativa e dos LLMs. Graças ao Snowpark, esse código pode estar em qualquer linguagem que você preferir, seja SQL, Python, Java ou Scala.

Obtenha um desempenho 3,5 vezes mais rápido e 34% de economia de custos, sem comprometer a governança
Crie código em Python, Java ou Scala usando o conjunto de bibliotecas do Snowpark, como a API DataFrame, e ambientes de execução, incluindo UDFs e procedimentos armazenados. Em seguida, implemente e processe seu código com segurança onde seus dados estão, tudo com governança consistente no Snowflake.
Em média, com o Snowpark, os clientes observam um desempenho 3,5 vezes mais rápido e uma economia de 34% em relação a soluções gerenciadas Spark.1
Crie menos pipelines de dados com compartilhamento de dados simples
Com o Data Cloud, você terá uma vasta rede de dados e aplicativos ao seu alcance.
Acesse e distribua facilmente dados e aplicativos com acesso direto a conjuntos de dados em tempo real do Snowflake Marketplace, o que reduz os custos e a carga associados aos pipelines tradicionais de extração, transformação e carregamento (extract, transform and load, ETL) e às integrações baseadas em API. Ou simplesmente use conectores nativos para trazer os dados.
NOSSOS CLIENTES
Empresas líderes usam o Snowflakepara Data Engineering





Comocomeçar
Todos os recursos de engenharia de dados de que você precisa para criar pipelines com o Snowflake.

Guias rápidos
Comece a trabalhar rapidamente com os tutoriais do Snowflake para engenharia de dados.

Laboratório prático virtual
Participe de um laboratório virtual prático conduzido por instrutor para aprender a criar pipelines de dados com o Snowflake.

Comunidade Snowflake
Conheça e aprenda com uma rede global de profissionais de dados no fórum da comunidade e nos grupos de usuários da Snowflake.
Comece seus 30 diasde avaliação gratuita
Teste o Snowflake sem custo por 30 dias e conheça o Data Cloud, que ajuda a eliminar a complexidade, o custo e as restrições de outras soluções.
1Fonte de dados: resultados de clientes do Snowpark.