





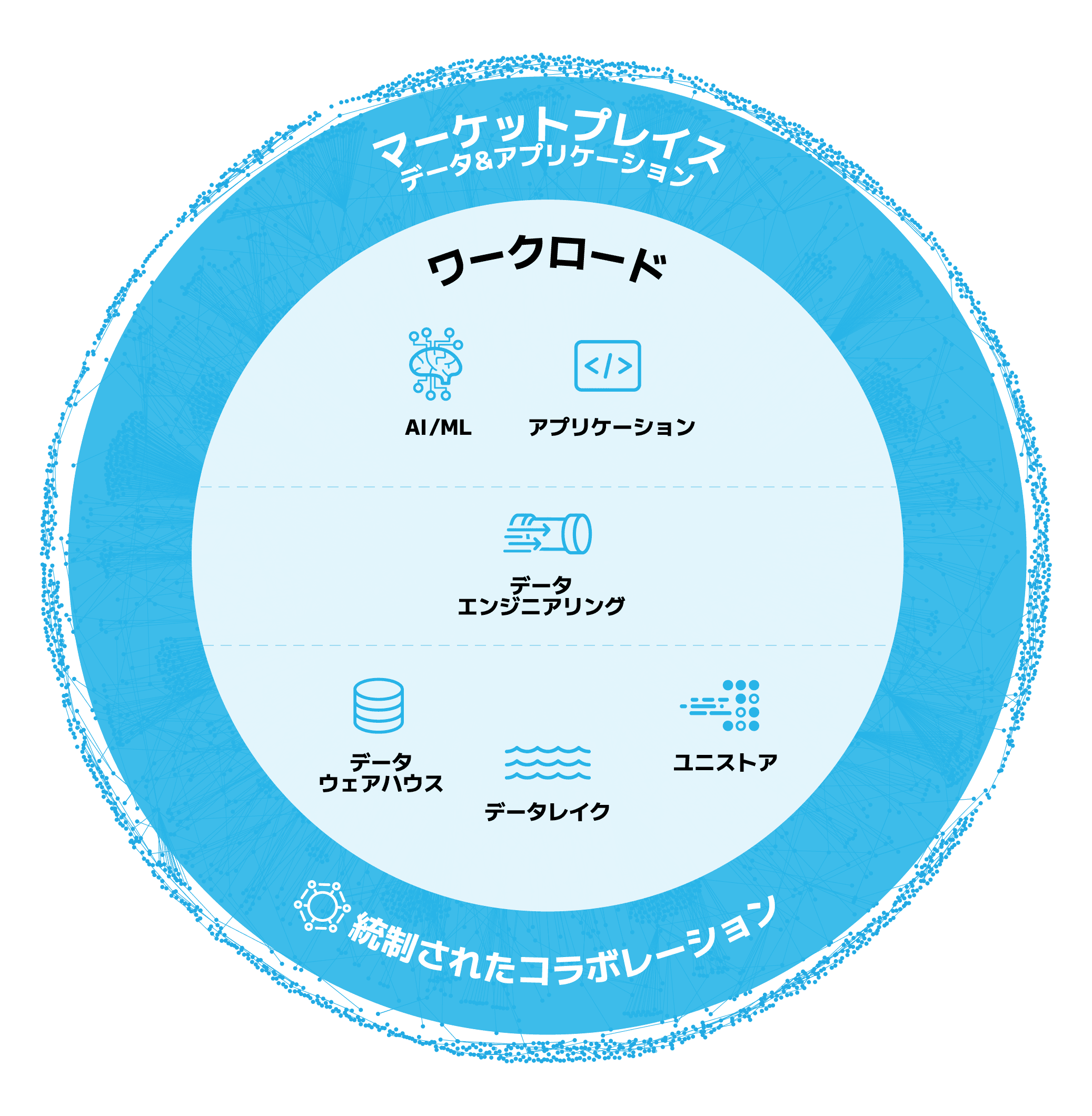
ワークロード
データエンジニアリングのための Snowflake
SQLやPythonで、ストリーミングとバッチの強力なデータパイプラインを構築できます。AI/ML、アプリ、アナリティクスのためのデータエンジニアリングの強化により、ガバナンスと制御を犠牲にすることなく4.6倍のパフォーマンス高速化を実現しています。

複雑なデータエンジニアリング要件を簡素化
宣言型パイプラインとコスト効率の高い増分リフレッシュを活用して、シングルプラットフォーム上でストリーミングとバッチのデータパイプラインを構築できます。
データシェアリングで不要なパイプラインを排除
Snowflakeマーケットプレイスにある数千ものデータセットやアプリから直接、すぐに使えるライブデータにアクセスできます。パイプラインを構築する必要はありません。
最適化された単一エンジンで任意の言語を使用してコーディング
PythonやSQLなどでプログラミングを行い、Snowflakeのマルチクラスターコンピュートで実行できます。別のインフラストラクチャを用意する必要はありません。
メカニズム
10秒未満のレイテンシーでデータをストリーミング
ストリーミングとバッチのシステムは切り離されていることが多く、一般的に管理が複雑で拡張にはコストがかかります。対してSnowflakeでは、ストリーミングとバッチのデータ取り込みと変換を単一のシステムで扱えるため、すべてが常にシンプルです。
Snowpipe Streamingを使用すれば、10秒未満のレイテンシーでほぼリアルタイムに行セットデータをストリーミングできます。また、Snowpipeを使用してファイルを自動で取り込むことも可能です。いずれの方法もサーバーレスであるため、スケーラビリティとコスト効率が改善します。
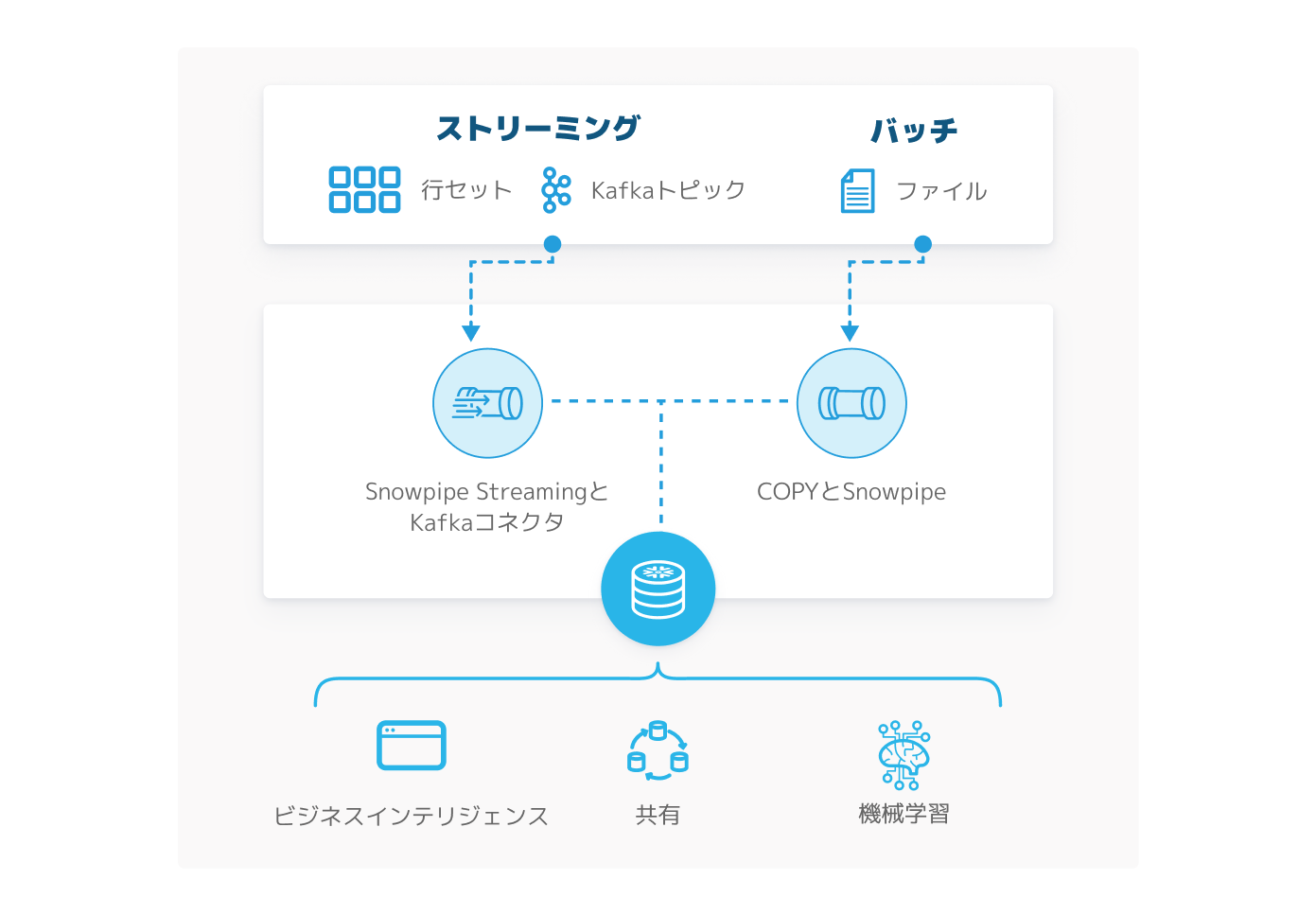
単一のパラメータ変更でレイテンシー調整が可能
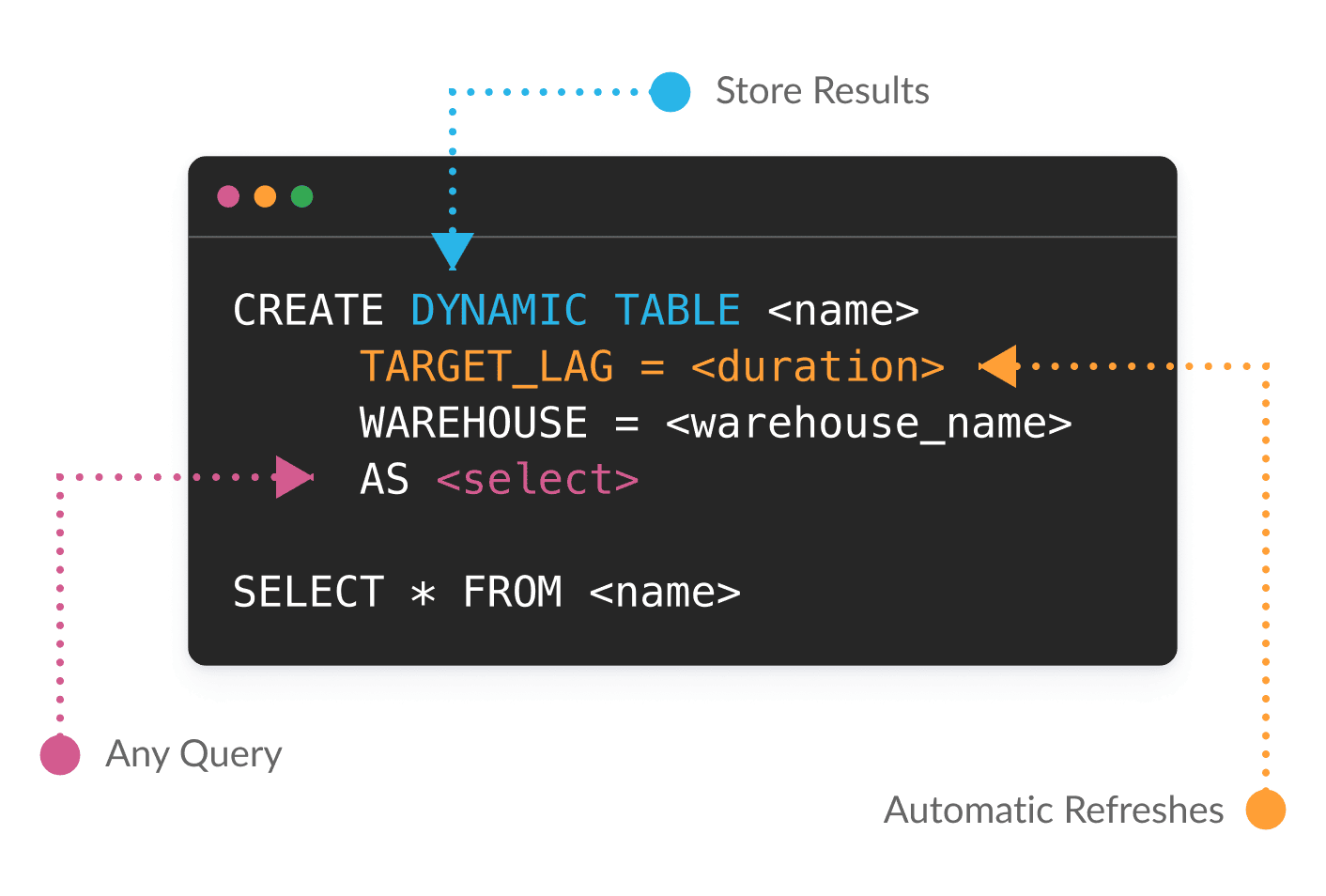
ダイナミックテーブルを使用することで、SQLまたはPythonを使用してデータ変換を宣言的に定義できます。Snowflakeが依存関係を管理し、鮮度の目標に基づいて結果を自動的にマテリアライズします。ダイナミックテーブルの対象となるのは、前回のリフレッシュ以降に変更されたデータのみです。そのため、大量のデータと複雑なパイプラインがシンプルになり、コスト効率が上昇します。
ビジネスニーズが変化しても、単一のレイテンシーパラメータを変更してバッチパイプラインをストリーミングパイプラインに切り替えるだけで容易に適応できます。
アナリティクス、AI/ML、アプリケーションのためのデータエンジニアリングを強化
データのある場所でワークロードを実行することにより、パイプラインのアーキテクチャが合理化します。別のインフラストラクチャを用意する必要はありません。
データのある場所でのコーディングが可能になることで、さまざまなビジネスニーズが活性化し、アナリティクスの加速、生成AIやLLMのパワーを解放するアプリの構築などが実現します。コーディングは、Snowparkのライブラリとランタイムを使用して、Python、Java、Scalaを始めとする任意の言語で行えます。

ガバナンスを犠牲にすることなく4.6倍のパフォーマンス高速化と35%のコスト削減を実現
Pythonやその他のプログラミングコードをSnowflake内のデータの近くで実行して、データパイプラインを構築できます。処理は、Snowflakeの伸縮性のあるコンピュートエンジン内に構築された多言語ランタイムで自動的にプッシュダウンされます。
少数のデータパイプラインでデータエンジニアリングを迅速に開始
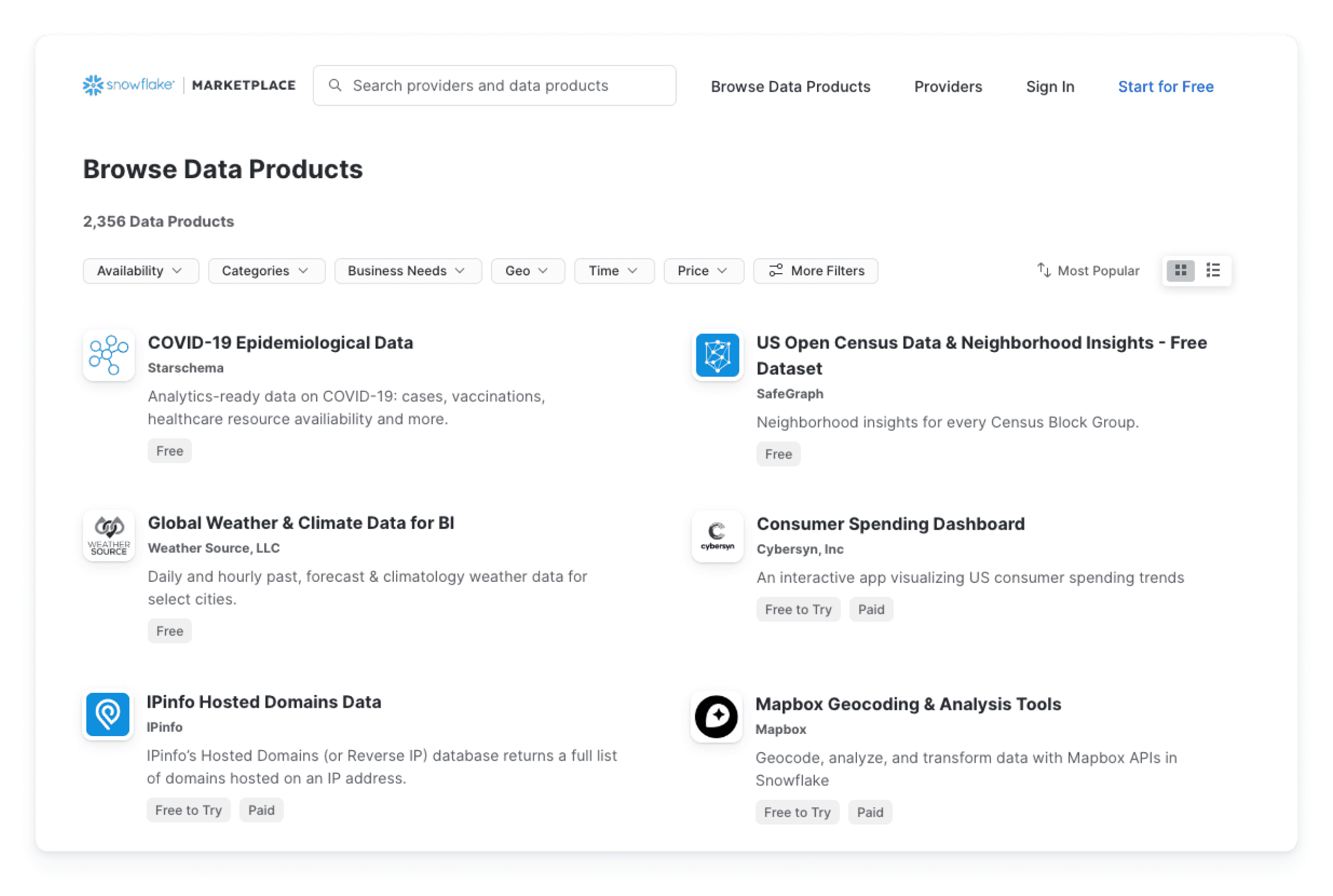
AIデータクラウドには、いつでもアクセスできる膨大なデータとアプリケーションのネットワークがあります。
Snowflakeマーケットプレイスからライブデータセットに直接アクセスして、データとアプリケーションの利用と配布を簡単に行えます。これにより、従来的な抽出、変換、ロード(ETL)のパイプラインとAPIベースの統合に関連するコストと負荷が軽減されます。また、Snowflakeネイティブコネクタを使用すれば、追加のライセンスコストなしにスムーズにデータを取り込めます。
組み込みのDevOps機能で実稼働までの道のりを合理化
プロジェクトの設定やパイプラインをGitから直接インポートして展開をトリガーできます。自動化された変更管理(作成、変更、実行)により、実稼働環境でのデータベースの一貫性が維持されます。PythonのAPIを使用してプログラムでSnowflakeリソースを管理でき*、Snowflake CLIを使用してCI/CDパイプライン内のタスク(GitHub Actionsなど)を自動化できます。これにより、Snowflake上で直接、または使用している既存のDevOpsツールを通じて、より優れたコラボレーションとバージョン管理、シームレスな統合が実現します。さらに、Snowflake Trailによって簡単に可観測性を確保できます。
*パブリックプレビュー中
Snowflakeのお客様
データエンジニアリングにSnowflakeを活用しているリーダー企業







まずはここから
Snowflakeでのパイプライン構築に必要なデータエンジニアリングのリソースをすべてご紹介します。

クイックスタート
Snowflakeのチュートリアルを利用して、データエンジニアリングを迅速にスタートできます。

バーチャルハンズオンラボ
インストラクターによるバーチャルハンズオンラボにぜひご参加ください。Snowflakeを使用したデータパイプラインの構築方法を習得できます。

Snowflakeコミュニティ
SnowflakeのコミュニティフォーラムやSnowflakeユーザーグループを通じて、世界中のデータプラクティショナーと出会い、さまざまな学びを得られます。
30日間の無料トライアルを開始する
Snowflakeの30日間無料トライアルで、他のソリューションに内在する複雑さ、コスト、制約の課題を解決するデータクラウドを体験できます。
1データソース:Snowpark導入成果レポート