Snowflakeで複数のデータモデリングアプローチに対応

注:本記事は(2022年4月25日)に公開された(Support Multiple Data Modeling Approaches with Snowflake)を翻訳して公開したものです。
注:この投稿は2019年に公開されたものを現行の製品、特徴、機能を反映するよう更新しています。
Snowflakeに入社して以来、データウェアハウスモデリングアプローチのアプローチとしてSnowflakeに最も適しているのは何か、と聞かれることがよくあります。そこで誇らしく思うのは、Snowflakeは複数のデータモデリングアプローチを等しくサポートしているという点です。
お客様の中には、データVaultという特定のモデリングアプローチを使用して既存のデータウェアハウスを構築した上で、その後Snowflakeへの移行を決断したという方もいます。
よくあるのが次のようなパターンの会話です。
顧客「データVaultはSnowflakeで使えますか?」
私「使えますよ。お客様はどういった点に不安を感じたのですか?」
顧客「いや、Snowflakeという社名ですから、Snowflakeタイプのスキーマにしか対応していないかもしれないと思ったのです。」
私「ああ、なるほどそういうことだったのですね。でも社名はデータウェアハウスの設計とはまったく関係ないのです。実際、SnowflakeではデータVaultを含むすべてのタイプのリレーショナル設計に対応しています。」
データVaultモデリングとは?
ビジネスインテリジェンスのデータVaultシステムまたは単にデータVault(DV)モデリングという言葉を聞いたことのない方のために説明すると、データVaultとは、アジャイルで柔軟性と拡張性に優れたエンタープライズデータウェアハウス(EDW)をモデリングするためのメソッドおよびアプローチを提供するものです。
Dan Linstedtによる公式な定義は、
「DVは、詳細指向の履歴追跡であり、ビジネスの1つ以上の機能領域をサポートする正規化されたテーブルセットと一意にリンクされているもの」となっています。
これは、第3正規形(3NF)とスタースキーマの間にある最良の組み合わせを網羅するハイブリッドアプローチです。柔軟性と拡張性に優れ、一貫性があり、企業のニーズに適応できる設計となっています。DVは、今日のエンタープライズデータウェアハウスのニーズを満たすように特別に設計されたデータモデルです。
重要なのは、DVは、データウェアハウジングスペースに使用された他のメインストリームデータモデリングアプローチのアジリティ、柔軟性、拡張性の問題に対処するよう特別に開発されたという点です。詳細で不揮発性で、監査可能なエンタープライズデータの履歴レポジトリとして構築されました。
その核となるのは、3つの主要タイプのテーブルのみで構成される反復可能なモデリング手法です。
- ハブ:ビジネスオブジェクトを表すビジネスキーの一意のリスト
- リンク:ビジネスプロセスの作業ユニットを表す関連性/トランザクションの一意のリスト
- サテライト:ハブとリンクの記述データ(履歴付きのタイプ2)
ハブはビジネスオブジェクト識別子(ビジネスキー)のレポジトリであり、ビジネスオブジェクト自体がビジネス能力の中心であるため、ハブはビジネス主導型となります。
ソースシステムは、ビジネスプロセスの自動化エンジンと考えることができます。これにより、ビジネスオブジェクトの関係とデータの状態(オン、オフ、アクティブ、非アクティブ、バランスなど)が追跡されます。複数のソースシステムを持つ企業の場合、これらのビジネスオブジェクトとその記述データは、ビジネスキーによるセマンティック統合によって簡単に追跡できます。このテクニックを「パッシブ統合」と呼びます。
リンクは多対多の構造になるように設計されており、リエンジニアリングせずに(つまり、データをリロードすることなく)、カーディナリティやビジネスルールの変更を柔軟に吸収できます。
サテライトでは、必要な間隔で履歴を記録するための適応性に加えて、ソースシステムに対する疑う余地のない監査可能性とトレーサビリティを得ることができます。
以下は、データVault 2.0モデルの簡単な例をご紹介します。

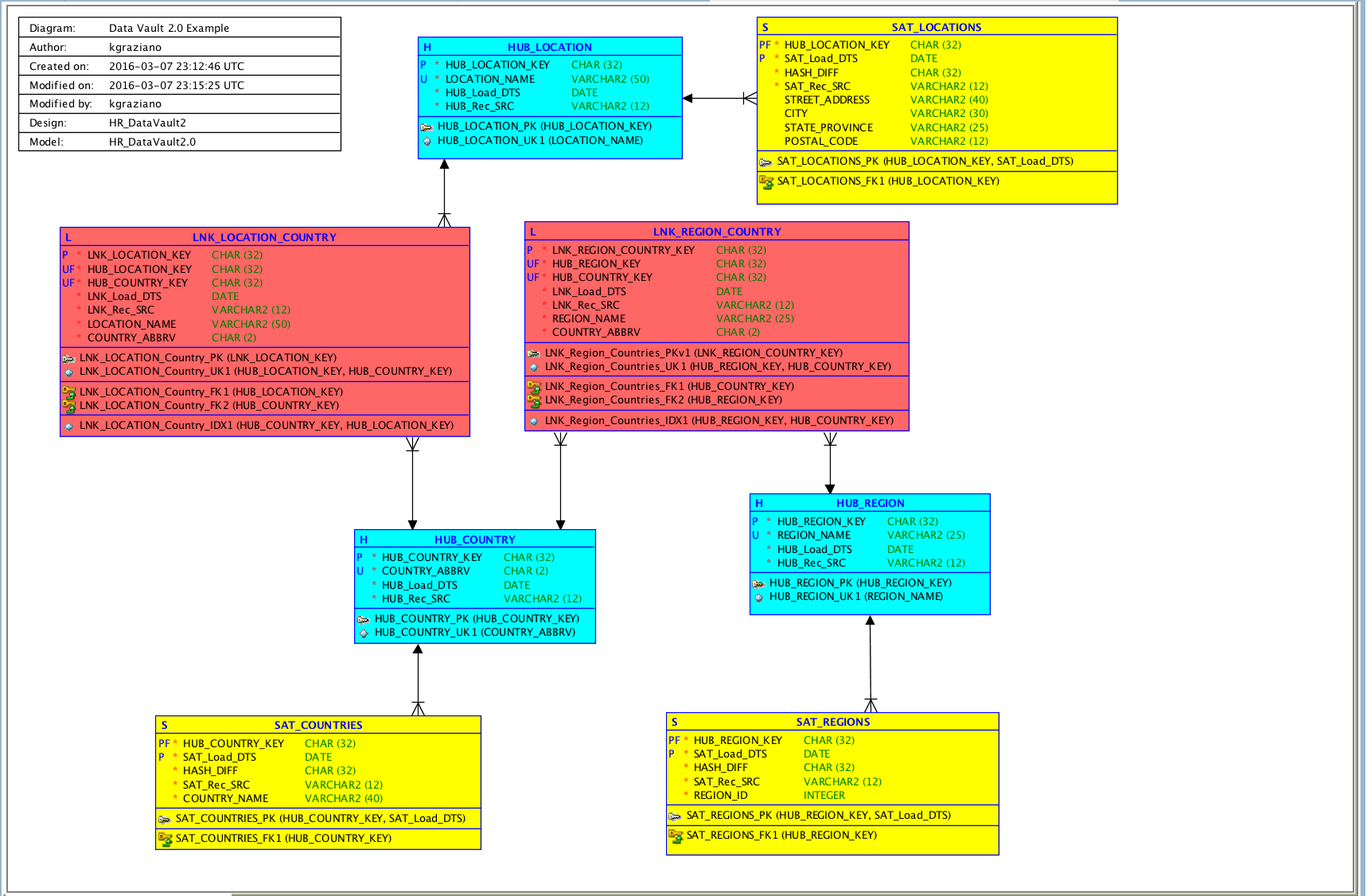{kind=link}
データVaultで使用するSnowflake機能
Snowflakeは、使用量ベースの価格設定によるANSI SQL RDBMSで、現在市場にあるすべてのリレーショナルソリューションのようなテーブルとビューに対応しています。データモデリングの観点から見ると、データVault(DV)はデータウェアハウスのテーブルを設計するための特定の方法とパターンであるため、Snowflakeで問題なく実装することができます。
実際、SnowflakeのMPPコンピュートクラスタ、最適化されたカラム型ストレージ形式、アダプティブデータウェアハウステクノロジーの組み合わせを使用すれば、従来のデータウェアハウスソリューションよりも少ない労力でより優れたDVのロードとクエリを実現できると思います。Snowflakeではパーティショニング、配布キーの事前計画、優れた性能を実現するためのインデックスの構築は不要です。これらはすべて、安全なクラウドベースのメタデータストアを使用し、データアクセスパターンとリソースの可用性に基づいて、高度なフィードバックループでクエリを監視、調整するSnowflakeのダイナミッククエリの最適化機能の一部として処理されます。
Snowflakeのお客様はクエリ性能の向上を実感しています(場合によっては100倍の改善が実現します)。このことから、BIツールに公開する情報マート(つまりレポーティング)層の仮想化にSnowflakeはうってつけだと言えるでしょう。
データVault 2.0
DV 2.0仕様の実装をご検討中の方もいらっしゃると思いますが、これもSnowflakeでご使用いただけます。MD5ハッシュ関数が組み込まれているため、MD5ベースのキーを実装し、DV2.0 HASH_DIFF概念を使用して変更データのキャプチャを行えます。
DV 2.0のハッシュ関数の使用をサポートしているだけでなく、データVault Logarithmic の特定時点(PIT)の読み込み時にSnowflakeのマルチテーブルインサート(MTI)も使用できます。この機能によって、複数のPITテーブルをデータVaultの1つの結合クエリから並行して読み込むことができます。
DVリソース
DVについての詳細は、次のような専門のウェブサイトや関連書籍を参考にしてください。
- 「Introduction to Agile Data Engineering」Kent Graziano(筆者)著
- 「The Data Vault Guru」Patrick Cuba著
- Intro to DV – 筆者の個人ブログにある無料のホワイトペーパー
- Free DV intro videos - 考案者、Dan Linstedt提供
- 「Building a Scalable Data Warehouse with DV 2.0」Dan Linstedt著
- Dan Linstedtのブログ
今回の投稿で、SnowflakeでのDVに関する皆さんの疑問にお答えできたと思います(DVはSnowflakeで使用可能です)。Snowflakeの利用を開始する際には、最大400ドル分の無料使用が可能なオンデマンドオファーを是非ご利用ください。
Snowflakeのブログ、Twitter、LinkedInアカウントで、Snowflakeのすべてのアクションとアクティビティの最新情報をご覧いただけます。
追加のリソース
著者
