Snowflake pandas APIの導入:Snowflakeで分散型pandasを大規模に実行
Pythonの人気は急速に高まり、機械学習、アプリケーション開発、パイプラインなどで開発言語として人気が高まっています。Snowflakeは、Python開発者向けにクラス最高のプラットフォームを提供することに深くコミットしています。このコミットメントに沿って、Snowflake pandas APIのパブリックプレビューサポートを発表します。これにより、分散型のpandasをSnowflakeで大規模にシームレスに実行できるようになります。
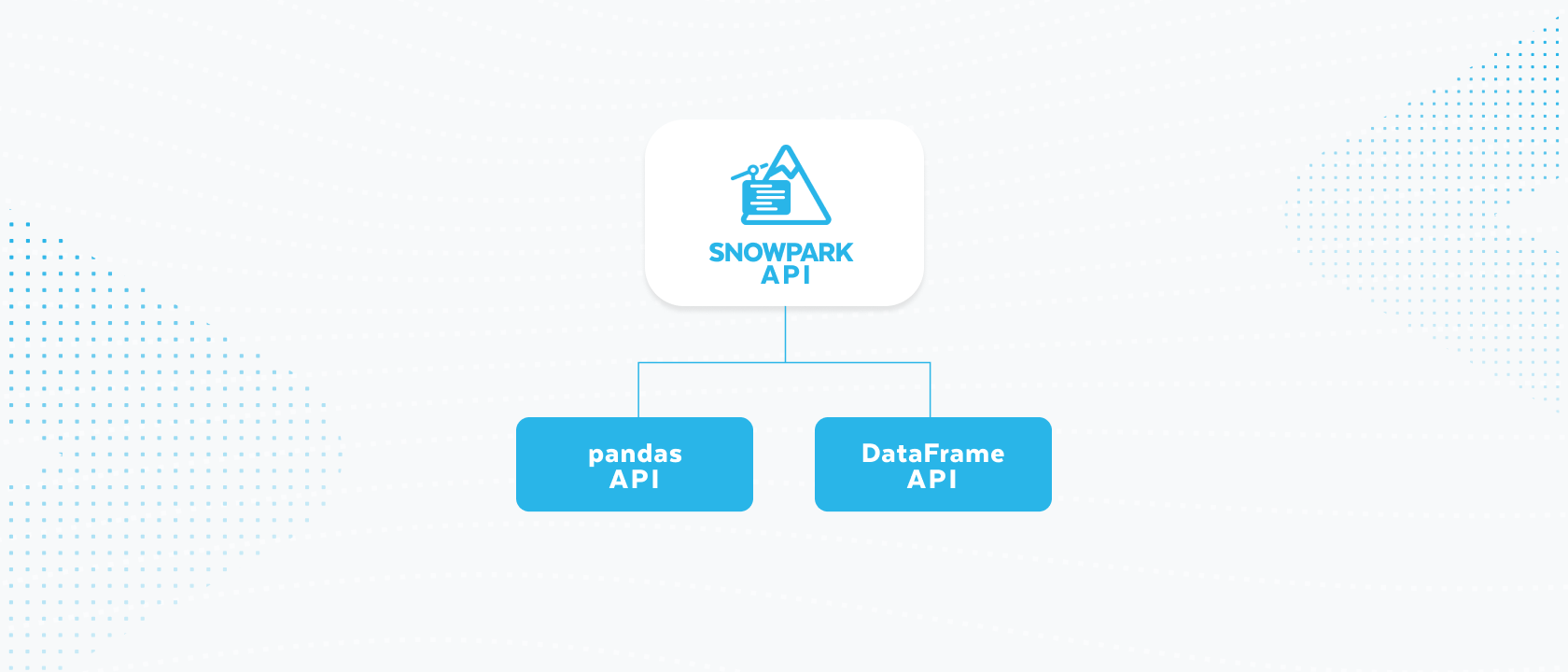
Snowflakeのお客様はすでに、Snowparkを通じてPythonの力を活用しています。Snowparkは、Snowflakeのデータと並行してPythonなどのプログラミング言語を実行するライブラリとコード実行環境のセットです。Snowparkの既存のDataFrame APIを使用すると、ユーザーは、Sparkの規約によく似た、遅延評価されたデータに対するリレーショナル操作のための堅牢なフレームワークにアクセスできます。2024年4月、Snowflakeのお客様は、データエンジニアリングとデータサイエンスにおけるさまざまな大規模データ処理タスクのために、Snowparkで1日平均約5,500万件のクエリを実行しました。Snowparkが拡張され、最小限のコード変更でpandas互換のAPIレイヤーが提供されたため、ユーザーはSnowflakeの性能、規模、ガバナンスを生かし、使い慣れたものと同じパンダネイティブのエクスペリエンスを得ることができます。
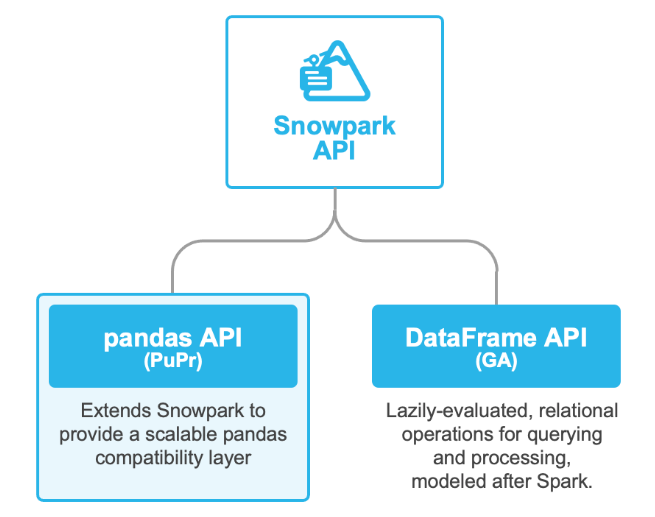
分散型pandas APIを導入する理由
pandasは、数え切れないほどのSnowflakeユーザーを含む世界中の何百万ものユーザーにとって頼りになるデータ処理ライブラリです。しかし、pandasは、現在のような大規模なデータを処理するために構築されたものではありません。pandasコードを実行するには、すべてのデータを単一のメモリ内プロセスに転送してロードする必要があります。中規模から大規模のデータセットでは扱いにくくなり、単一のノードで処理しきれなくなったデータセットでは完全に機能しなくなります。現在、組織がこのような大量のデータを処理しており、Snowpark pandasでは、同じpandasコードを実行でき、すべてのpandas処理がSnowflakeで分散して実行されるようになっています。データがSnowflakeから出ることはなく、pandasワークフローはSnowflakeの伸縮性のあるエンジンを使用してはるかに効率的に処理できます。これにより、Snowflakeの力をあらゆる場所のpandas開発者に提供します。
Snowflake pandas APIのメリット
- 迅速かつシームレスな開発:Snowpark pandasは、従来のpandasのシングルノードメモリの制約を克服します。開発者は、メモリ不足エラーに遭遇したり、pandasコードを他のフレームワーク(Spark、Snowpark DataFrames API、SQLなど)に書き換えたりすることなく、プロトタイプから本番環境へスムーズに移行し、開発サイクルを加速できます。
- Python開発者とのミーティング:Snowflake pandas APIは、pandasを使いやすく普及させたのと同じpandas APIシグネチャとデータフレームセマンティクスを保持します。新しい構文の学習や大量のコードの書き換えが不要。
- セキュリティとガバナンス:データがSnowflakeの安全なプラットフォームから出ることはありません。Snowflake pandas APIは、データが存在する場所にコンピューティングをプッシュダウンし、データへのアクセス方法をデータ組織内で統一することで、監査とガバナンスを容易にします。
- 追加のコンピュートインフラストラクチャーの管理と調整が不要:このソリューションは、SnowflakeコンピュートエンジンとSnowflake内の既存のクエリ最適化技術を活用しています。エンドユーザーは追加のコンピュートインフラストラクチャーをスピンアップ、管理、調整する必要はありません。
ぜひお試しください。このクイックスタートに従って、2分足らずで開始できます。
Snowflake pandas APIの仕組み
Snowpark pandasは、オープンソースのModin APIをフロントエンドクライアントレイヤーとして活用し、正確なpandas APIシグネチャを維持し、pandasを普及させ、使いやすくしたデータフレームセマンティクスを維持します。しかし、実際にはSnowpark pandasの動作は異なります。内部では、メモリ内のpandasデータフレームとやり取りする代わりに、DataFrame操作が透過的にSQLクエリに変換され、プッシュダウンされ、Snowflakeの堅牢で強力なコンピュートエンジンのメリットを享受します。つまり、pandas構文を使用し続けながら、Snowflakeのスケーラビリティと高度に最適化されたデータインフラストラクチャのメリットを享受し、pandasコードを分散して実行することができます。
さらに、カスタムPythonロジックをユーザー定義関数(UDF)として組み込むことや、Snowflakeにプリインストールされている一般的なオープンソースパッケージを柔軟に活用することもできます。これにより、pandasの汎用的なapply()関数を利用し、ビルトインPython関数、ラムダ関数、カスタムユーザー定義関数など、適用するデータの種類を問わず、DataFrameまたはSeriesの軸に沿って簡単にデータを処理できます。
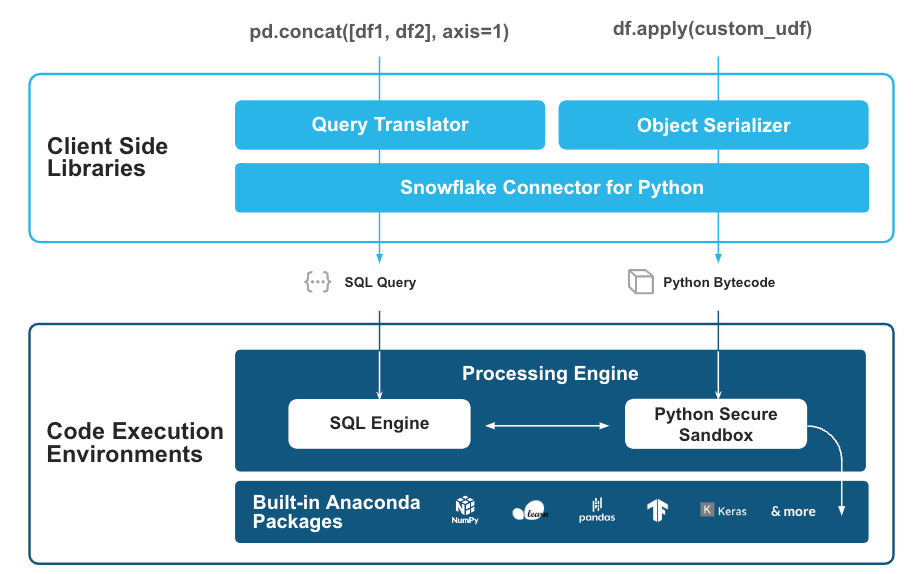
ネイティブのpandas操作は、SQLクエリとして実行されるようトランスパリングおよびプッシュダウンされます。
カスタムPythonコードがシリアル化され、プッシュダウンされた後、サンドボックス化された安全なPython環境で実行
このブログの執筆時点で、Snowflake pandas APIは一般的なpandas API機能を網羅しており、サポートを拡大する取り組みが続けられています。さらに、下流のサードパーティOSSライブラリなどと統合することも検討しています。ぜひお試しください。[email protected]までメールでフィードバックをお寄せください。
開始に必要なリソース
Authors
