Cortex Analyst:AIによるセルフサービスアナリティクスへの道筋

本日は、Snowflake Cortex Analystのパブリックプレビューを発表します。MetaのLlamaおよびMistralモデルを使用して構築されたCortex Analystは、Snowflakeの構造化データと対話するための会話インターフェイスを提供するフルマネージド型のサービスです。ビジネスユーザー向けの直感的なセルフサービスアナリティクスアプリケーションの開発を合理化し、業界トップクラスの精度を実現します。
これまで、ビジネスユーザーはデータの質問に答えるために主にBIダッシュボードとレポートを利用してきました。しかし、これらのリソースは多くの場合、必要な柔軟性に欠けるため、ユーザーはデータアナリストに更新や回答を求めなければならず、数日かかる場合があります。Cortex Analystは、テキストからSQLへの変換の精度が高い自然言語インターフェイスを提供することで、このサイクルを打破します。Cortexを利用することで、組織は直感的な会話アプリケーションの開発を合理化できます。これにより、ビジネスユーザーは自然言語を使用して質問をし、ほぼリアルタイムでより正確な回答を得ることができます。
テキストからSQLへの変換精度を高めるために、Cortex Analystは最先端のLLMを利用したエージェント型AIセットアップを使用します。便利なREST APIとして利用できるCortex Analystは、あらゆるアプリケーションにシームレスに統合できます。これにより開発者は、ビジネスユーザーが結果を操作する方法と場所をカスタマイズしながら、ロールベースのアクセス制御(RBAC)などのSnowflakeの統合セキュリティ機能とガバナンス機能のメリットを享受し、貴重なデータを保護できます。
Bayerのデータ投資の価値を高めるCortex Analyst
Bayerは、医薬品と生物医学のイノベーションをリードする企業で、Cortex Analystを使用して企業データのセルフサービスアナリティクスを強化しています。これまで、チームはダッシュボードを使用してエンタープライズデータプラットフォームにアクセスしていましたが、多くの場合、増加するユーザーの質問に対応する柔軟性が不足していました。
現在では、チャットインターフェイスとしてStreamlit in Snowflake、クエリ生成サービスとしてCortex Analystを使用することで、自然言語でのセルフサービス分析により既存のビジネスインテリジェンスを強化できます。最初のフェーズでは、セールスVPからの次のような価値の高いエグゼクティブ向けの質問に答えることに焦点を当てました。「直近1か月間の製品Xの市場シェアは?」その後、ビジネスユニットアナリストをサポートするよう拡張し、詳細な行レベルのデータを提供してより深い分析を行えるようになりました。Bayerのジャーニーの詳細については、こちらをご覧ください。
What if internal functional users could ask specific questions directly on their enterprise data and get responses back with basic visualizations? The core of this capability is high-quality responses to a natural language query on structured data, used in an operationally sustainable way. This is exactly what Snowflake Cortex Analyst enables for us. What I’m most excited about is we’re just getting started, and we’re looking forward to unlocking more value with Snowflake Cortex AI.”
Mukesh Dubey
現在の「AI for BI」ソリューションはアナリティクスへのアクセスの民主化を目指しているが、正確性に難色を示している
大規模言語モデル(LLM)は、自然言語の理解とコードの生成の両方が可能なため、SQLの知識がなくてもアナリティクスにアクセスできるようにすることで、アナリティクスの民主化に関心を集めています。しかし、近年の進歩にもかかわらず、LLMは正確なSQLと信頼性の高い応答を生成するために必要な実世界のデータベースとスキーマを理解するのに苦労しています。生スキーマのテキストからSQLへの変換にLLMのみを利用する業界ソリューションは精度が低く、多くの場合、デモから本番環境への移行に失敗します。
Forresterの最新レポートで概説されているように、シンプルな単一テーブルクエリの正確で実行可能なコードの生成に成功したという逸話は、最良のケースで70%、最悪の場合、複数のテーブルや複雑な結合で約20%の成功率を示しています。ビジネスユーザーのデータに関する質問に答えるサービスであれば、正確さが最も重要です。自然言語ベースのソリューションを確実に採用するために、ビジネスチームは、提供される結果が一貫して実用的な事実を反映していることを信頼する必要があります。信頼をもたらす正確な結果がなければ、他の特徴量は重要ではありません。
Cortex Analystは、4つの原則に則って信頼性の高い、高精度を齎している
さまざまなユースケースでSQLコード生成の精度を高めるには、高度なLLMを利用する必要があります。Snowflakeでは、どのようなアプリケーションにも組み込むことができる信頼性の高い製品を構築するために、以下の重要な原則を掲げて取り組んでいます。
キャプチャのセマンティクス:未加工のスキーマにはセマンティック情報がないため、LLMがビジネスユーザーの意図に基づいてデータに関する疑問に正確に答えることは困難です。人間のアナリストと同様に、システムは質問の意図をユーザーの語彙や特定の専門用語を含めて理解する必要があります。高精度を提供するためには、セマンティックデータモデルを使用してこの情報を取得する必要があります。
問題スペースを含める:マーケティング分析や販売分析などのユースケースに特化したセマンティックデータモデルを作成することが重要です。データベーススキーマ全体をターゲットとするのではなく、SQLの生成精度を包含する範囲内で大幅に高めることができます。類似するテーブルや列が多すぎると、LLMが混乱し、精度が低下します。
回答できない質問を拒否し、代替案を提案する:私たちのシステムは、賢いアナリストのように、利用可能なデータがあれば、曖昧な質問や答えられない質問を能動的に特定して拒否します。誤った結果を生成する代わりに、自信を持って回答できる代替クエリを提案し、ユーザーの信頼を維持します。
テクノロジーと共に進化:最先端のLLMでさえ、複雑なスキーマに対して正しいSQLを生成するのは困難です。結合を有効にすることは難しくありませんが、ポスト結合を過小評価することなく正確な結果を提供し、Chasmトラップやファントラップなどのトリッキーなスキーマ形状を処理することは、現在のAIモデルにとって困難です。スキーマをシンプルにすることで、生成されるSQLの信頼性と精度を大幅に高めることができます。
Snowflakeは精度を重視しているため、現行の製品範囲は上記の戦略に意図的に焦点を当て、お客様の評価とベンチマークテストで90%以上の精度を確実に観測しています。徐々に高度なユースケースに対応できるよう、より多くの機能を導入しながら、信頼のおける精度を維持していく予定です。
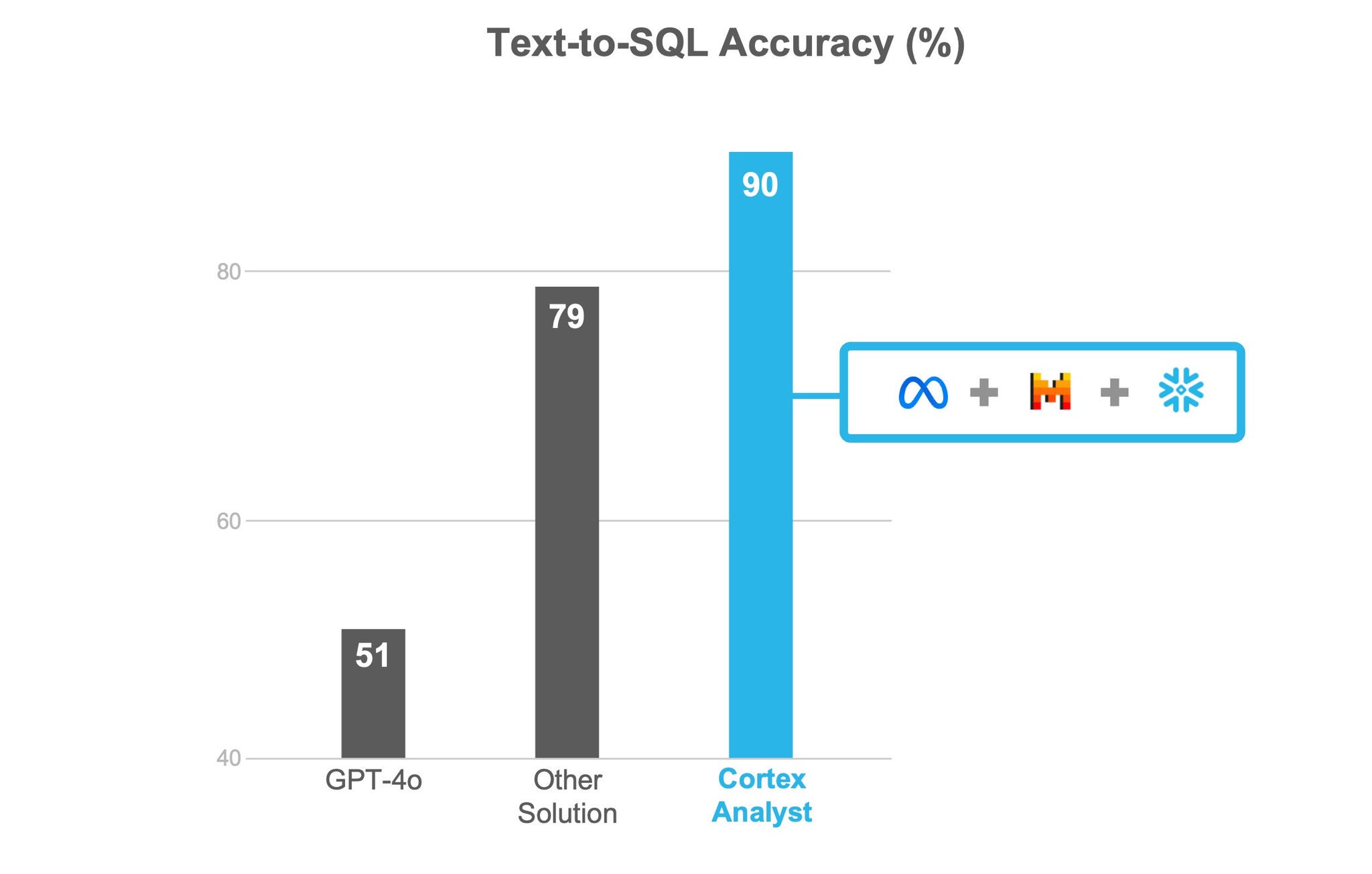
上記のベンチマークは、実際のユースケースを表す社内評価セットに基づいています。その結果、Cortex Analystは、最先端のLLM(SoTA)からのシングルショットSQL生成より一貫して精度が2倍近く高く、市場の他のテキストからSQLへの変換ソリューションより精度が約14%高いということが分かりました。ベンチマークの詳細と結果を掘り下げる、今後のエンジニアリングブログ記事にご期待ください。
Cortex Analystが会話型セルフサービスアナリティクスの導入を促進し、TCOを削減
実稼働グレードのソリューションを構築するには、テキストからSQLへの正確な応答を生成するサービスが必要です。ほとんどのチームにとって、そのようなサービスを開発するのは骨の折れる作業であり、多くの場合、デモの段階を過ぎると何か月も作業が進まないことになります。精度、レイテンシー、コストのバランスを取るのは難しく、多くの場合、最適なソリューションとは言えません。Cortex Analystは、これらすべての複雑さを処理するフルマネージド型の高度なエージェント型AIシステムを提供し、テキストからSQLへの高精度の応答を生成することで、このプロセスを簡略化します。
Cortex Analystは、任意のアプリケーションに統合できる便利なREST APIを提供しており、開発者は、ビジネスユーザーが結果を見たり操作したりする方法と場所を柔軟に調整できます。APIを使用することで、開発者は以下のような時間のかかる負担から解放されます。
モデルの評価とファインチューニング:モデルごとに異なる強みがあり、LLMを取り巻く状況は急速に進化し続けています。適切なモデルを選択するのは、長い時間と継続的な作業です。
複雑なソリューションアーキテクチャの構築と維持:一貫した信頼性の高い精度を提供するために、このサービスでは、マルチエージェントインタラクション、複数のコンポーネントとの統合、さらには複雑な検索拡張生成(RAG)アーキテクチャのメンテナンスが必要になる場合があります。
GPUキャパシティプランニング:実稼働環境でインサイトに命を吹き込むには、アプリケーションが予期せぬユーザー需要に対応する必要があります。GPUリソースの管理とスケーリングは、開発者がサポートする必要のある、増え続けるピースの1つです。
Cortex Analystを使用することで、総保有コスト(TCO)と信頼性の高いセルフサービスアナリティクスの提供までの時間を大幅に短縮できます。生成されたSQLクエリはSnowflakeのスケーラブルなエンジンで実行されるため、スタック全体の統合されたコストガバナンスコントロールに加えて、クエリ実行中にトップクラスのパフォーマンスが得られます。
Cortexアナリストがデータセキュリティとガバナンスを優先
データプライバシーとデータガバナンスは企業にとって最も重要なものです。組織がデータアナリティクスにLLMを使用することを検討すると、データプライバシー、アクセス制御、内部データにアクセスするLLMに関する懸念が生じます。Snowflakeのプライバシー第一の基盤とエンタープライズグレードのセキュリティ機能により、高度なデータプライバシーとガバナンスを活用しながら、最新のAIの進化を利用して重要なユースケースを模索し、実行することができます。
- Cortex Analystは顧客データのトレーニングは行っていません。 顧客データを使用して、顧客ベース全体で利用できるようにモデルをトレーニングしたり微調整したりすることはありません。さらに、推論のために、Cortex AnalystはセマンティックモデルYAMLファイルで提供されるメタデータ(テーブル名、列名、値型、説明など)をSQLクエリ生成に使用します。次に、このSQLクエリをSnowflake仮想ウェアハウスで実行し、最終出力を生成します。
- 顧客データがSnowflakeのガバナンスの境界を離れることはありません。デフォルトでは、Cortex Analyst機能はMistralとMetaの最先端のSnowflakeホストLLMを搭載しています。これにより、メタデータやプロンプトなどのデータがSnowflakeのガバナンスの境界を離れることはありません。Azure OpenAIモデルの使用を許可すると、メタデータとユーザーの質問のみがSnowflakeのガバナンス境界の外側に移動します。
- ネイティブのSnowflakeプライバシーおよびガバナンス機能と完全に統合されています。Cortex Analystは、管理者によって設定されたすべてのRBACポリシーを遵守し、生成されたSQLクエリが実行されたときに適切なアクセス制御が遵守されるようにします。この統合により、データの強固なセキュリティとガバナンスが可能になります。
Cortex Analystの仕組み
ユーザーのデータに関する質問に答えるには、複数のLLMエージェント間のインタラクションを含む包括的なワークフローが必要です。すべてのステップにガードレールを設け、幻覚を防止し、正確で信頼できる回答を提供します。
大まかに言うと、Cortex Analystは以下の手順に従って自然言語の質問から回答へと進みます。
リクエスト。エンドユーザー用クライアントアプリケーションは、ユーザーの質問と関連セマンティックモデルYAMLを含むリクエストをCortex Analyst REST APIに送信します。
質問の理解とエンリッチメント。ユーザーの質問の意図を分析し、回答が得られるかどうかを判断します。
質問が曖昧で自信をもって回答できない場合、類似した自信をもって回答できる質問のリストが返されます。これにより、ユーザーは立ち往生するのを防ぎ、データに関する疑問に対して信頼性の高い回答を受け続けられるようになります。
質問が回答可能に分類された場合、提供されたYAMLファイルに取り込まれたセマンティクスで強化される。ファイルには、測定とディメンション列の名前、デフォルトの集計、同義語、説明、サンプル値などの情報が含まれます。
SQLの生成とエラー訂正。最適な応答を提供するために、エンリッチされたコンテキストは、それぞれ異なるLLMを使用する複数のSQL生成エージェントに渡されます。さまざまなタスクを得意とするLLMはさまざまです。時間関連のコンセプトを得意とするLLMもあれば、マルチレベルの集計をより効果的に処理できるLLMもあります。複数のLLMを使用することで、クエリ生成の精度と堅牢性が向上します。次に、エラー修正エージェントが、SQLコンパイラなどのSnowflakeコアサービスを使用して、生成されたSQLの構文エラーと意味エラーをチェックします。エラーが見つかった場合、エージェントは修正ループを実行して修正します。また、幻覚に対処し、モデルがセマンティックデータモデルの外側のエンティティを発明したり、存在しないSQL関数を使用したりする可能性があるインスタンスを修正します。
- 応答。最後のステップとして 生成されたSQLクエリはすべて シンセサイザーエージェントに転送されますSynthesizer Agentは、前のエージェントが行った作業を利用して、目の前の質問に最も正確に答える最終的なSQLクエリを生成します。SQLクエリとユーザーの質問の解釈がAPI応答に含まれます。返されたSQLクエリはクライアントアプリケーションのバックグラウンドで実行でき、最終結果はエンドユーザーに表示されます。
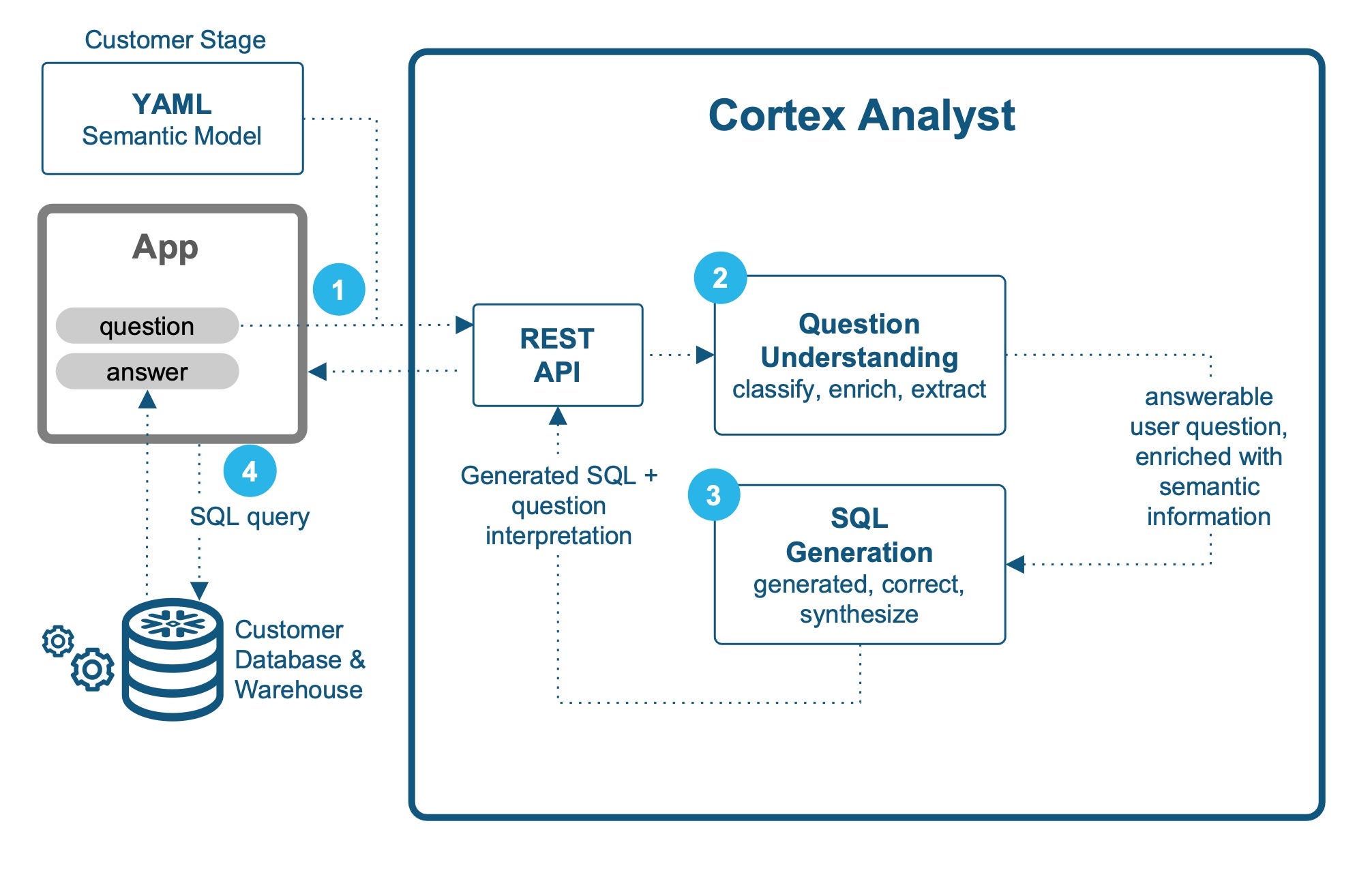
このエージェント型AIシステムで使用されるさまざまなエージェント、LLM、ツールの詳細については、舞台裏ブログを参照してください。
Cortex Analystの今後
将来的なイテレーションにより、精度や信頼性を損なうことなく、より高度なユースケースに対応できるよう製品範囲が拡大するでしょう。明確な焦点を絞り、体系的に拡大することにより、ビジネスユーザーが自信を持って「自分のデータに話しかける」ことができる製品の提供を目指します。次の四半期には、以下のようなエキサイティングな機能アップデートを予定しています。
- Cortex Searchとの統合によるリテラル/サンプル値の自動検索
- 高精度の結合をサポート
- マルチターンの会話に対応し、よりインタラクティブな体験を提供する
- セマンティックモデルの作成、イテレーション、管理、フィードバックループを容易にするSnowsight UI
Cortex Analystを始める
このクイックスタートガイドを使用して、Cortex Analystを活用した初めてのチャットアプリを構築しましょう。
機能の詳細と、より正確な結果を得るためのベストプラクティスについては、Cortex Analystのドキュメントを参照してください。

著者


