コンテナランタイムの導入:柔軟でスケーラブルなトレーニングとSnowflakeノートブックからのGPU推論の実現

予測機械学習は、引き続きデータドリブンな意思決定の要です。しかし、組織がさまざまな形式のデータを蓄積し、モデリング技術が進歩するにつれ、データサイエンティストとMLエンジニアのタスクはますます複雑化しています。多くの場合、実際のモデル開発よりも、インフラストラクチャーの管理、パッケージ管理のハードルの解消、スケーラビリティ問題への対応に多くの労力が費やされます。
本日、Snowflakeは、すべてのAWS商用リージョンでパブリックプレビュー中の新しいContainer Runtime for Snowflake Notebookにより、Snowflake MLの機能を拡張できることを嬉しく思います。このフルマネージド型のコンテナベースのランタイムには、最も一般的なPythonライブラリとフレームワークがあらかじめ設定されており、PyPiやHuggingFaceなどのオープンソースハブから柔軟に拡張できます。コンテナランタイムには、データロードとモデルトレーニングを自動的に並列化するAPIが含まれています。これにより、ランタイム外でOSSライブラリを使用して同じワークロードを実行する場合と比較して、実行速度が3~7倍に向上し、MLワークフローを効率的に拡張することが容易になります。Snowflake Notebook on Container Runtimeを使用することで、データサイエンティストとMLエンジニアはインフラストラクチャーとスケーラビリティーにかける時間が大幅に短縮され、MLモデルの開発と最適化、迅速なビジネスインパクトに注力できるようになります。
Snowflakeでコスト効率、拡張性、柔軟性に優れたMLモデルを構築
すでに多くの企業がコンテナランタイムを使用して、GPUに簡単にアクセスできる高度なMLユースケースをコスト効率良く構築しています。顧客には、CHG Healthcare、Keysight Technologies、Aviosが含まれます。
CHG Healthcareは、45年以上の業界専門知識を持つヘルスケア人材派遣企業で、AI/MLを使用して130の医療分野の70万人の医療従事者に人材派遣ソリューションを提供しています。CHGは、Snowflake MLでエンドツーエンドのMLモデルを構築、生産しています。
“コンテナランタイムでSnowflake NotebookのGPUを使用することは、機械学習のニーズに対して最もコスト効率の高いソリューションであることがわかりました。Snowflakeの並列処理をSnowflake MLの任意のオープンソースライブラリで活用できることを高く評価し、ワークフローに柔軟性と効率性の向上をもたらしました” - CHG Healthcare, Data Scientist, Andrew Christensen氏
Keysight Technologiesは、電子設計およびテストソリューションのリーディングプロバイダーです。13の業界において全世界で55億ドル以上の収益と33,000社以上の顧客を抱え、イノベーションに関する3800件以上の特許を保有しています。Keysightは、コンテナランタイムを使用してSnowflake MLでスケーラブルな販売および予測モデルを構築します。
“コンテナランタイムでSnowflake Notebookを試したところ、その体験は目覚ましいものだったと言える。CPUとGPUの両方での分散処理、最適化されたデータロード、モデルレジストリとのシームレスな統合によってサポートされる柔軟なコンテナインフラストラクチャにより、ワークフローの効率が向上しました”- Keysight Technologies、ITグローバルアプリケーション向けアナリティクス&オートメーション担当, Krisna Moleyar氏
4,000万人以上の会員と1,500社のパートナーを擁するトラベルアワードのリーダーであるAviosは、Snowflake Notebook on Container Runtimeを使用して、ビジネスに必要な柔軟性を備えた詳細な分析とデータ分析タスクを実行しています。
“コンテナランタイムのSnowflake Notebookは、柔軟性とスピードに優れていて、とても楽しく使っています。タイムアウトや変数の忘れを気にすることなくコードを実行できるようになりました。PyPIの統合を可能にすることで、Pythonのパッケージをより幅広く使用できるというメリットも得られ、分析やデータサイエンスのタスクをより柔軟に行えるようになります” - Avios, Data Scientist, Olivia Brooker氏
MLインフラストラクチャ管理の簡素化
Container Runtimeは、パッケージ管理やインフラストラクチャーのプロビジョニングの煩わしさをわずか数クリックで解消します。
Snowflake Notebook用のコンピュートプールを選択するシンプルなノートブック構成。データサイエンティストは、モデルトレーニングなどのリソースを大量に使用するタスクの規模と複雑さに応じて、事前定義されたリソースプールセット(CPUまたはGPU)から選択できます。
ML開発をサポートする最新の一般的なライブラリとフレームワーク(PyTorch、XGBoost、LightGTM、Scikit-learnその他)がプリインストールされている、ランタイムCPUとGPU固有のイメージのセット。データサイエンティストはSnowflake Notebookを立ち上げるだけで、すぐに作業に取りかかることができます。
pipを介してオープンソースパッケージにアクセスし、Hugging Faceなどのハブからあらゆるモデルを取り込むことができます(例はこちらを参照)。

ML開発のスケーリング
コンテナランタイムは、データサイエンティストがより迅速にイテレーションを行い、インフラストラクチャーの管理ではなく価値の創出に集中するために役立ちます。最適化されたデータロードと分散モデルトレーニングにより、セルフサービスインフラストラクチャーに簡単にアクセスできます。これにより、非常に大きなデータやモデルのトレーニングを行ったり、MLワークフローを高速化したりできます。
データロード用のSnowflake ML APIは、SnowflakeテーブルをpandasまたはPyTorchデータフレームとして効率的にマテリアライズします。データは、複数のCPUまたはGPUで並列化することにより、効率的に並列に取り込まれ、データフレームとしてノートブックに表示されます。
PyTorchの分散データ並列アプローチなど、より複雑なモデルトレーニングフレームワークを扱う場合、Snowflakeの新しいShardedDataConnector APIは、ソーステーブルの取り込みと、各並列プロセスで使用できるようにシャーディングするタスクを簡素化します。しかも、効率とスピードは同じです。
from snowflake.ml.data.data_connector import DataConnector
# Retrieve data from a Snowflake table
table_name = 'LARGE_DATASET'
snowpark_df = session.table(table_name)
# Materialize it into a pandas dataframe using DataConnector. Snowflake leverages a distributed compute cluster to load in the data in parallel
pandas_df = DataConnector.from_dataframe(snowpark_df).to_pandas()ユーザーは、scikit-learn、XGBoost、LightGBM、Pytorch、Tensorflowなどの任意のオープンソースフレームワークを使用して、このマテリアライズドデータの特徴量エンジニアリングとモデルトレーニングを行うことができます。
# OSS XGBoost
import xgboost as xgb
X = pandas_df.drop('LABEL', axis=1)
y = pandas_df['LABEL']
# Train on GPUs using the materialized pandas dataframe
model = xgb.XGBRegressor(n_estimators=1000, tree_method="gpu_hist")
model.fit(X, y)
モデルトレーニング用のSnowflake ML APIは、XGBoost、LightGBM、PyTorchが提供する使い慣れたオープンソースインターフェイスを拡張します。ユーザーは、既存のトレーニングノートブックをインポートするだけで、セキュリティ、規模、コスト面でコンテナランタイムで実行できるようになります。
さらに、同じオープンソースAPIに簡単に拡張できるため、ユーザーは基盤となるインフラストラクチャーをオーケストレーションすることなく、複数のCPUまたはGPUへの分散トレーニングを活用できます。データサイエンティストがトレーニングを強化し、数百GB以上のデータセットで効率的にモデルをトレーニングできるようになりました。
from snowflake.ml.modeling.distributors.xgboost import XGBEstimator, XGBScalingConfig
input_cols = ["FEATURE1", "FEATURE2", "FEATURE3", "FEATURE4", "FEATURE5", "FEATURE6", "FEATURE7"]
label_col = 'TARGET'
# Snowflake will distribute the training across multiple GPUs
scaling_config = XGBScalingConfig(use_gpu=True)
estimator = XGBEstimator(n_estimators=10, scaling_config=scaling_config)
model = estimator.fit(data, input_cols=input_cols, label_col=label_col)
モデルを容易に管理、展開、提供
データ処理とMLワークフローが複雑化する中、下流のアプリケーションに展開されるモデルの再現性と監査性を確保するためには、強力なエンドツーエンドの系統が不可欠です。Snowflakeモデルレジストリと自動MLリネージ(プライベートプレビュー中)とのシームレスな統合により、データサイエンティストはノートブックの実験環境から、展開および消費フェーズを通じて管理および追跡されるフルマネージド型のエンティティにモデルを簡単に昇格させることができます。
# Log the trained model to the Snowflake Model Registry
model_ref = registry.log_model (
model,
model_name="ChurnClassifier",
version_name="v1",
sample_input_data=train_data.limit(1).to_pandas(),
)
モデルがログに記録されると、そのモデルがバッチ分析ワークロードとして、またはエンドポイントを介したアプリケーションからのレコードごとの推論呼び出しとして、推論に使用できるかどうかが自動的に処理されます。モデルレジストリに記録されたモデルは、次のように柔軟なオプションで推論に直接使用できます。
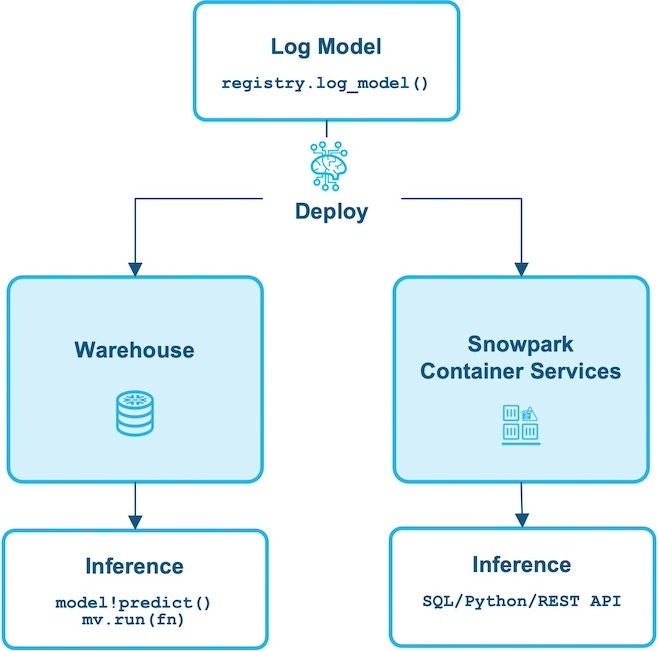
従来サポートされていたPythonまたはSQLからのウェアハウスベースの推論(およびSnowflake Condaパッケージを使用するCPUモデルの優れたオプション)に加え、モデルレジストリは、シンプルで強力なcreate_service()APIを使用して、AWSの商用リージョンでパブリックプレビュー中のSnowflakeコンテナサービスでモデルを提供することをサポートするようになりました。コンテナベースのモデルサービスの主なメリットは次のとおりです。
GPUでジョブを高速化:ユーザーは、GPUを搭載した分散コンピュートプール上で大規模なMLモデルを実行できるため、コンテナランタイムでトレーニングされたあらゆるモデルを、外部ソースから取り込んだモデルとともにSnowflakeで使用できます。利用可能なインスタンスノードとGPUで複数のプロセスを使用する分散推論が自動的に処理され、ユーザーはリソース利用の最適化について心配する必要はありません。
Pythonライブラリを使用:モデルは、ウェアハウスでサポートされていないパッケージにpipパッケージの依存関係を使用できます。
複雑なコンテナイメージの作成と管理が不要:Snowflakeは、最適化されたモデル固有の推論サーバーコンテナイメージの作成を自動化し、サービスを展開します。ユーザーはコンテナイメージの管理や設定を行う必要はありません。
柔軟な推論オプション:モデルサービスは、Python SDK、SQL、およびアプリケーションからのREST APIエンドポイントから直接呼び出すことができます。
詳細と例については、当社のドキュメントを参照してください。
Snowflake MLですぐに使えるユースケース
ML用の新しいコンテナランタイムにより、データサイエンティストがSnowflake MLで直接、本番稼働可能な複雑なパイプラインを構築できるようになります。既存のワークフローやツールとの相互運用性を確保するために、データの移動や追加のMLインフラストラクチャーの設定は必要ありません。Snowflake ML APIの一部として高度に最適化されたデータと分散ワークフローがサポートされているため、複雑なML技術を実行する大規模データにMLワークロードを簡単に適用することもできます。
Snowflakeとコンテナランタイムによって実現される高度なMLユースケースには以下が含まれます 。
画像異常検知:この例では、製造企業が産業検査ワークフローの異常検知を構築しようとしています。彼らの目標は、異常画像を特定できるコンピュータービジョンモデルをトレーニングすることで、部品の欠陥を検出することです。そのためには、100万枚以上の画像でトレーニングしたコンピュータービジョンモデルを構築する必要があります。BUILDでのこのユースケースの動作を確認し、このクイックスタートに従ってください。
レコメンデーションエンジン:この例では、あるグローバルなキッチンカー会社が、高精度でローカルなメニュー提案を生成するために、何百台ものキッチンカーを動かすレコメンデーションエンジンを構築しようとしています。PyTorchベースのレコメンデーションアルゴリズムを使用して、それを実行するためのモデルをトレーニングおよび展開する方法をデモンストレーションします。詳しくはこちらのクイックスタートをご覧ください。
埋め込みを大規模に生成:RAGワークフローを基盤とする社内ナレッジディスカバリープラットフォームを構築、運用するには、テキストデータから大規模な埋め込みを生成する必要があります。Cortex埋め込み機能を使用してこれを行う方法をご紹介します。これは、高品質の埋め込みを生成するためのフルマネージド型のエクスペリエンスです。カスタム埋め込みが必要なユースケースでは、このクイックスタートと「コンテナランタイム」オプションを使用できます。
コンテナランタイムを使い始める
コンテナランタイムは現在、すべてのAWS商用リージョンでパブリックプレビュー中です(無料トライアルを除く)。ノートブックの作成と簡単なMLモデルの構築について説明したコンテナランタイムクイックスタートの紹介をお試しください。Snowflakeのモデル開発にGPUを活用する方法については、以下のより高度なクイックスタートをご覧ください。GPUを使用したXGBoostモデルのトレーニング(関連動画デモあり)
コンテナランタイムの詳細やSnowflake Notebookからの使用方法については、以下を参照してください。ドキュメント:コンテナランタイムでのSnowflake Notebook(ML)
著者

