Snowflake Arctic: il miglior LLM per l’enterprise AI. Intelligente, efficiente e realmente aperto

In passato, la creazione di un’enterprise intelligence di classe superiore tramite i LLM avrebbe avuto un consumo di risorse e costi proibitivi, spesso nell’ordine di decine, se non centinaia, di milioni di dollari. Chi fa ricerca nel campo dei LLM lotta da anni con le limitazioni che impediscono un addestramento e un’inferenza efficienti. I membri del team di ricerca sull’AI di Snowflake sono stati tra i primi a realizzare sistemi open source, e quindi più accessibili e convenienti per la community, come ZeRO e DeepSpeed, PagedAttention/vLLM e LLM360 che hanno notevolmente ridotto il costo dell’addestramento e dell’inferenza dei LLM.
E oggi il team Snowflake AI Research è entusiasta di presentare Snowflake Arctic, un LLM enterprise best‑in‑class che apre nuovi orizzonti all’apertura e all’addestramento a costi contenuti. Arctic offre intelligenza efficiente ed è realmente aperto.
- Intelligenza efficiente: Arctic eccelle nei benchmark per task come generazione di SQL, programmazione ed esecuzione di istruzioni, anche rispetto a modelli open source addestrati con budget per le risorse di calcolo significativamente più elevati. In effetti stabilisce un nuovo standard per l’addestramento a costi contenuti, per consentire ai clienti Snowflake di creare modelli personalizzati di elevata qualità per le loro esigenze aziendali a basso costo.
- Realmente aperto: la licenza Apache 2.0 offre accesso senza limitazioni a pesi e codice. Stiamo inoltre rendendo open source tutte le nostre data recipe e i risultati delle nostre ricerche.
Snowflake Arctic è disponibile da subito su Hugging Face, NVIDIA API Catalog e Replicate o tramite il tuo model garden o catalogo preferito, inclusi Snowflake Cortex, Amazon Web Services (AWS), Microsoft Azure, Lamini, Perplexity e Together nei prossimi giorni.
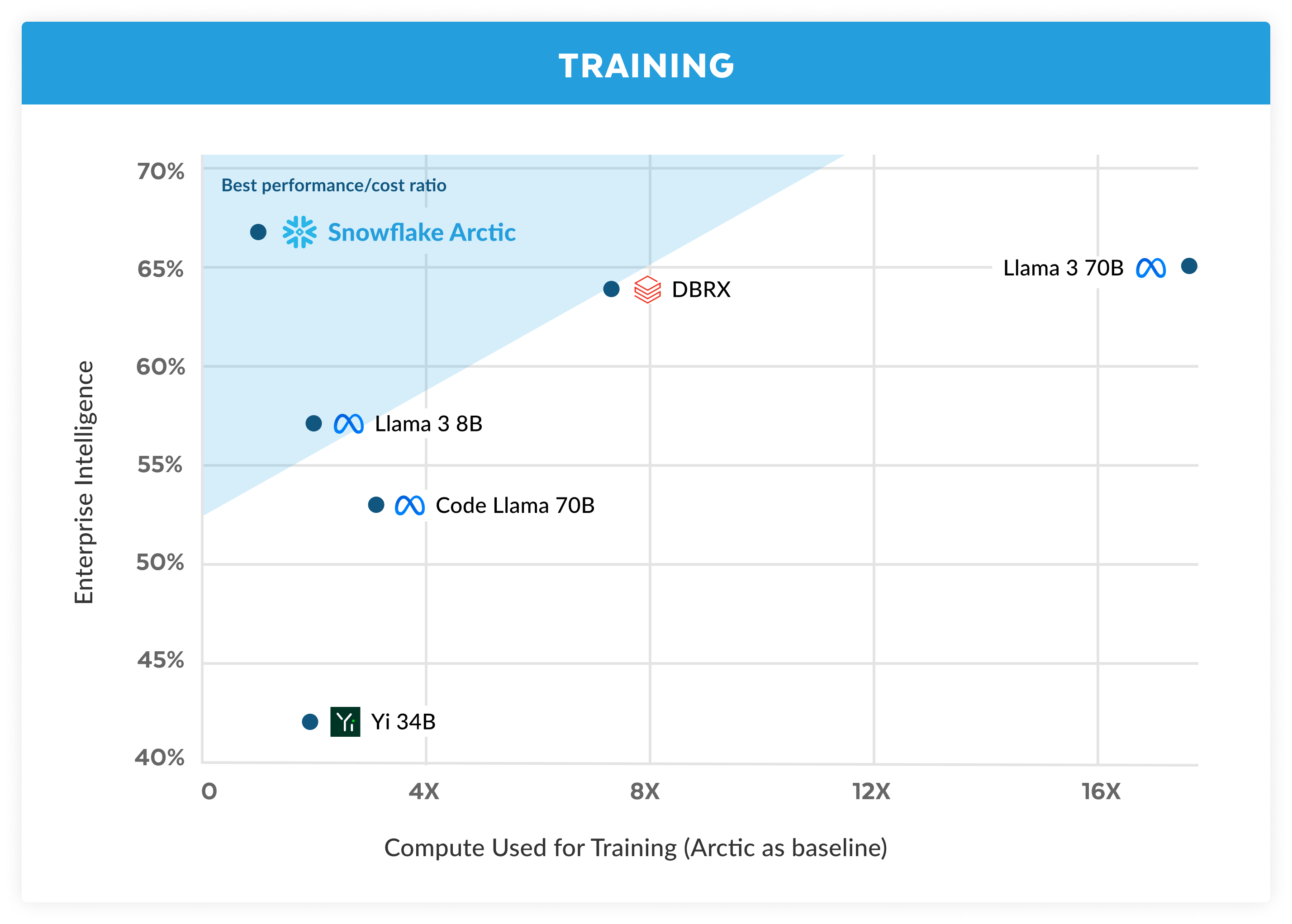
Enterprise intelligence superiore con costi di addestramento incredibilmente bassi
In Snowflake, vediamo uno schema coerente nelle esigenze di intelligenza artificiale e nei casi d’uso dei nostri clienti enterprise. Le imprese vogliono usare i LLM per creare copiloti conversazionali per i dati SQL, copiloti di programmazione e chatbot RAG. Dal punto di vista delle metriche, questo significa creare LLM eccellenti per SQL, codice, capacità di eseguire istruzioni complesse e di produrre risposte fondate. Abbiamo raccolto queste capacità in una singola metrica che chiamiamo enterprise intelligence stilando la media di Programmazione (HumanEval+ e MBPP+), Generazione di SQL (Spider) ed Esecuzione di istruzioni (IFEval).
Rispetto agli altri LLM open source, Arctic offre un’enterprise intelligence superiore, e lo fa utilizzando un budget per le risorse di calcolo dedicate al training di modelli sotto i 2 milioni di dollari (meno di 3000 settimane GPU). Questo significa che Arctic è più potente di altri modelli open source addestrati con un budget per le risorse di calcolo simile. Cosa ancora più importante, offre un’eccellente enterprise intelligence anche se confrontato con i modelli addestrati con budget per le risorse di calcolo decisamente maggiori. L’elevata efficienza di addestramento di Arctic significa inoltre che i clienti Snowflake e la community AI in generale possono addestrare modelli personalizzati a costi molto più bassi.
Come illustrato nella figura 1, Arctic è alla pari o addirittura superiore sia a LLAMA 3 8B che a LLAMA 2 70B per le metriche enterprise e utilizza meno della metà del budget per le risorse di calcolo dedicate al training. Allo stesso modo, nonostante utilizzi un budget per le risorse di calcolo 17 volte inferiore, Arctic offre prestazioni alla pari di Llama 3 70B in metriche enterprise come Programmazione (HumanEval+ e MBPP+), Generazione di SQL (Spider) ed Esecuzione di istruzioni (IFEval), riuscendo comunque a offrire prestazioni nel complesso molto competitive. Ad esempio, malgrado utilizzi una capacità di calcolo 7 volte inferiore rispetto a DBRX, resta competitivo in termini di comprensione del linguaggio e ragionamento (una raccolta di 11 metriche) e offre prestazioni superiori nella matematica (GSM8K). I risultati ottenuti per i singoli benchmark sono disponibili nella sezione Metriche.
Efficienza di addestramento
Per ottenere questo livello di efficienza di addestramento, Arctic utilizza un’architettura transformer ibrida Dense‑MoE unica che combina un modello transformer denso 10B di parametri con un MLP MoE da 128x3,66B residuo per un totale di 480 miliardi di parametri e 17 miliardi di parametri attivi selezionati mediante gating top‑2. È stato progettato e addestrato utilizzando i seguenti tre insight e innovazioni chiave:
1) Molti esperti ma concentrati, con una scelta più ampia: alla fine del 2021, il team DeepSpeed ha dimostrato che è possibile applicare l’architettura MoE ai grandi modelli linguistici autoregressivi per migliorare in modo significativo la qualità del modello senza aumentare il costo della capacità di calcolo.
Sulla base di questo, durante la progettazione di Arctic abbiamo notato che il miglioramento della qualità del modello dipendeva principalmente dal numero di esperti, dal numero totale di parametri del modello MoE e dal numero di possibili combinazioni di tali esperti.
Abbiamo così deciso di progettare Arctic con 480 miliardi di parametri distribuiti su 128 esperti dettagliati e di utilizzare il meccanismo di gating top‑2 per scegliere tra 17 miliardi di parametri attivi. I recenti modelli MoE hanno invece un numero significativamente inferiore di esperti come illustrato nella tabella 2. Arctic utilizza in modo intuitivo un elevato numero di parametri totali e molti esperti per aumentare la capacità del modello di offrire un’intelligenza di livello superiore, mentre sceglie in modo attento tra molteplici esperti e utilizza un numero moderato di parametri attivi per un addestramento e un’inferenza efficienti.
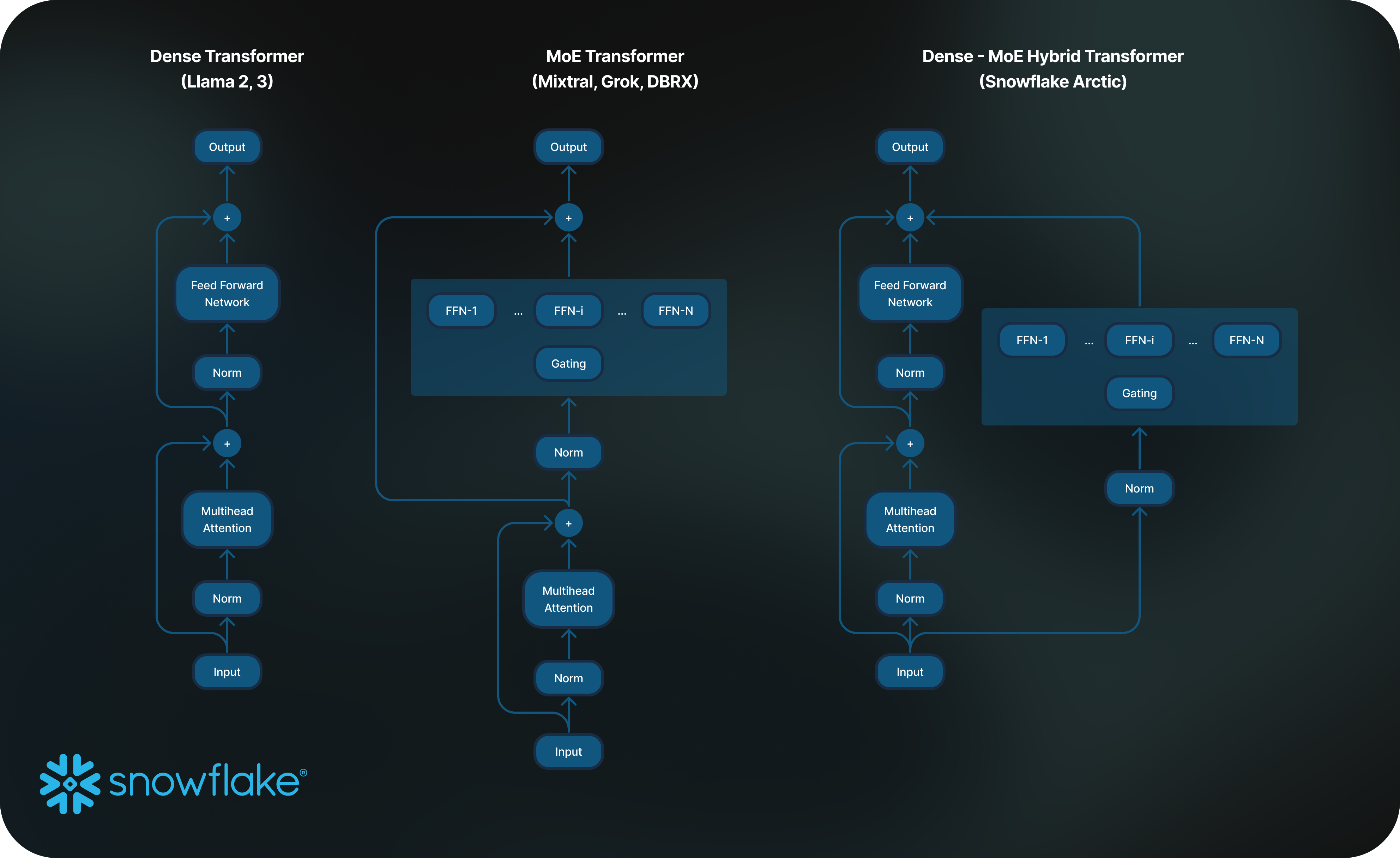
2) Architettura e coprogettazione del sistema: l’addestramento dell’architettura MoE vanilla con un numero elevato di esperti è molto inefficiente anche con l’hardware di addestramento AI più potente, a causa dell’elevato overhead della comunicazione all‑to‑all tra gli esperti. È tuttavia possibile nascondere questo overhead se alla comunicazione può sovrapporsi l’elaborazione.
Abbiamo inoltre visto che la combinazione di un transformer denso con un componente MoE residuo (figura 2) nell’architettura Arctic consente al nostro sistema di addestramento di ottenere una buona efficienza attraverso la sovrapposizione di comunicazione ed elaborazione, nascondendo una grossa parte dell’overhead di comunicazione.
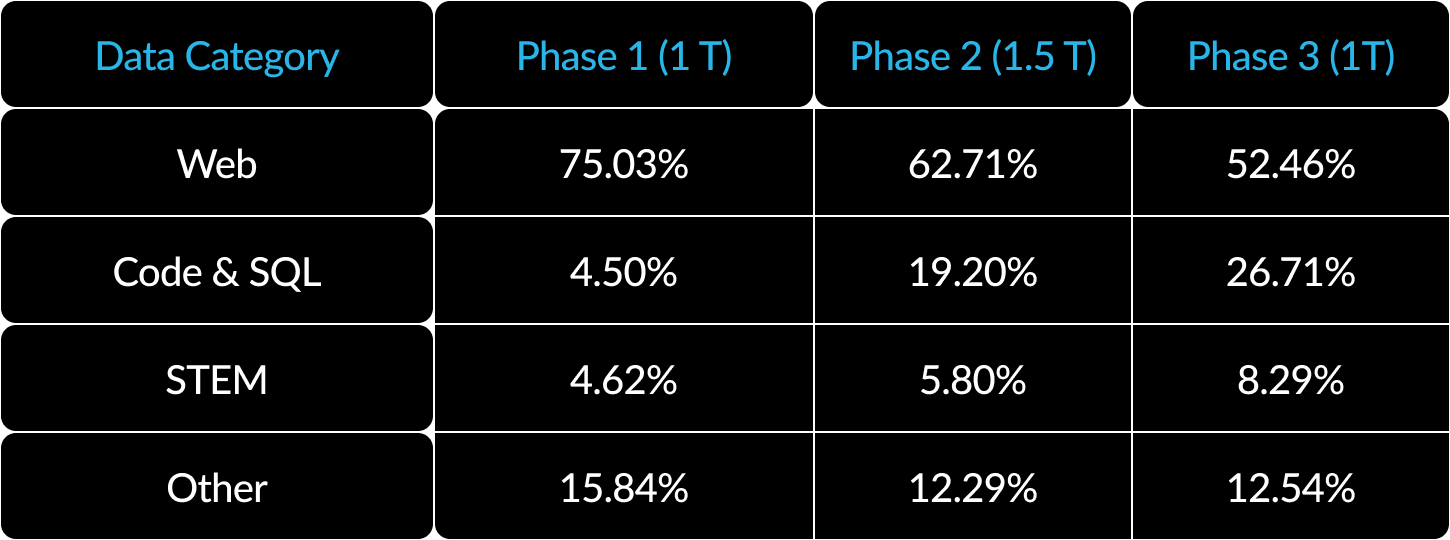
3) Curriculum di dati per metriche enterprise: per ottenere risultati eccellenti nelle metriche enterprise come la generazione di codice e SQL serve un curriculum di dati molto diverso rispetto ai modelli di addestramento per metriche generiche. Grazie a centinaia di ablazioni su scala ridotta, abbiamo scoperto che competenze generiche come il ragionamento basato sul buon senso possono essere apprese all’inizio, mentre altre più complesse, come programmazione, matematica e SQL, possono essere apprese in modo efficace verso l’ultima fase dell’addestramento. È possibile tracciare un’analogia con la vita e l’istruzione umane, laddove apprendiamo le capacità partendo dalle più semplici e arrivando a quelle più difficili. Arctic è stato quindi addestrato con un curriculum in tre fasi, ognuna con una composizione diversa di dati, orientata a competenze generiche nella prima fase (1 trilione di token) e a competenze di tipo enterprise nelle ultime due fasi (1,5 trilioni di token e 1 trilione di token). Di seguito è riportato un riepilogo generale del nostro curriculum dinamico.
Efficienza dell’inferenza
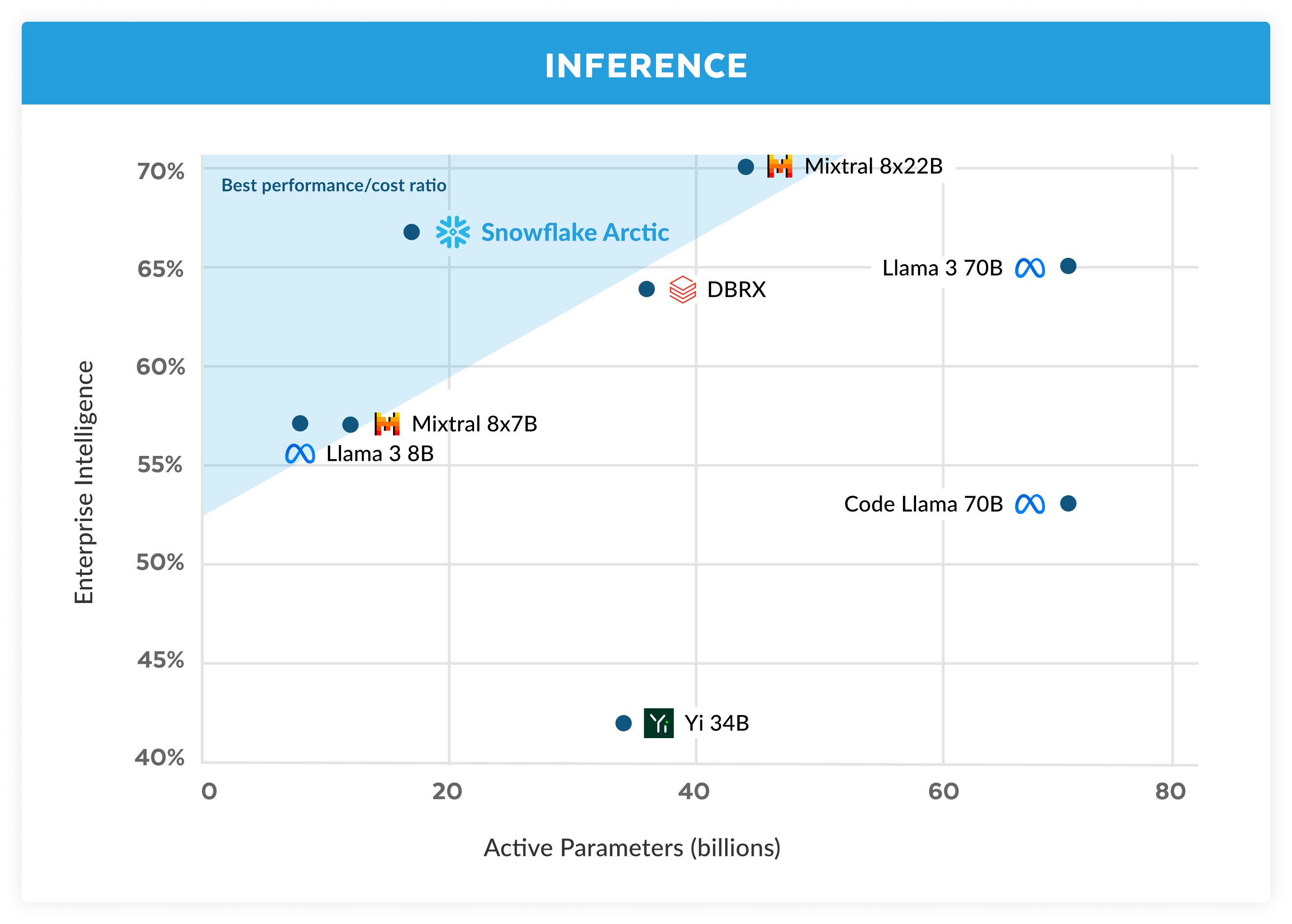
L’efficienza dell’addestramento rappresenta tuttavia solo un aspetto dell’intelligenza efficiente di Arctic. L’efficienza dell’inferenza è anch’essa di importanza critica per consentire una pratica implementazione del modello a basso costo. Arctic rappresenta un balzo in avanti nella scala dei modelli MoE, grazie all’uso di un numero di esperti e parametri totali più elevato rispetto a qualsiasi altro modello MoE autoregressivo. Abbiamo pertanto introdotto diversi insight di sistema e innovazioni per gestire l’inferenza in modo efficiente in Arctic:
a) Per l’inferenza interattiva di un batch di dimensioni ridotte, ad esempio un batch di taglia 1, la latenza di inferenza di un modello MoE è rallentata dal tempo necessario per leggere tutti i parametri attivi, quando l’inferenza è limitata dalla larghezza di banda della memoria. Con un batch di queste dimensioni, Arctic (17 miliardi di parametri attivi) può ridurre fino a 4 volte le letture della memoria rispetto a Code‑Llama 70B e fino a 2,5 volte rispetto a Mixtral 8x22B (44 miliardi di parametri attivi), e di conseguenza le prestazioni di inferenza sono più rapide.
Abbiamo collaborato con NVIDIA e lavorato con i team NVIDIA (TensorRT‑LLM) e vLLM per fornire un’implementazione preliminare di Arctic per l’inferenza interattiva. Con la quantizzazione FP8, possiamo inserire Arctic all’interno di un singolo nodo GPU. Anche se lontano dall’ottimizzazione totale, con un batch di taglia 1, Arctic offre un throughput di oltre 70 token al secondo che garantisce una buona interattività.
b) Quando le dimensioni dei batch aumentano in modo significativo, ad esempio con migliaia di token per passaggio, Arctic passa dal vincolo della larghezza di banda della memoria a quello della capacità di calcolo, dove l’inferenza è rallentata dal numero di parametri attivi per token. A questo punto, Arctic usa una capacità di calcolo 4 volte inferiore a quella di CodeLlama 70B e Llama 3 70B.
Per abilitare l’inferenza vincolata alla capacità di calcolo e un elevato throughput relativo che corrisponde al ridotto numero di parametri attivi in Arctic (vedi figura 3), è necessario un batch di grandi dimensioni. Per ottenerlo è necessaria una memoria cache KV sufficiente a supportare le grandi dimensioni del batch, oltre a memoria sufficiente per l’archiviazione di quasi 500 miliardi di parametri per il modello. Anche se difficile, questo risultato si può ottenere con l’inferenza a due nodi utilizzando una combinazione di ottimizzazioni del sistema come pesi FP8, split‑fuse e batching continuo, parallelismo tensoriale all’interno del nodo e parallelismo della pipeline sui nodi.
Abbiamo lavorato in stretta collaborazione con NVIDIA per ottimizzare l’inferenza per i microservizi NVIDIA NIM con tecnologia TensorRT‑LLM. Stiamo lavorando in parallelo con la community vLLM e il nostro team di sviluppo interno abiliterà nelle prossime settimane l’efficiente inferenza di Arctic per casi d'uso enterprise.
Realmente aperto
Arctic è stato creato sulla base delle esperienze collettive dei nostri diversi team, oltre ai principali insight e lezioni apprese dalla community. L’open collaboration è la chiave per l’innovazione e Arctic non sarebbe stato possibile senza il codice e gli insight di ricerca della community open source. Abbiamo un debito di riconoscenza con la community open source e siamo impazienti di restituire quanto appreso per arricchire la conoscenza collettiva e aiutare gli altri a realizzare i propri progetti.
Il nostro impegno per un ecosistema realmente aperto si estende oltre l’apertura di codice e pesi, fino alla condivisione di insight di ricerca aperti e recipe open source.
Insight di ricerca aperti
La struttura di Arctic si è sviluppata lungo due traiettorie distinte: un tracciato aperto, che abbiamo percorso rapidamente grazie ai tanti insight provenienti dalla community, e un tracciato più complesso, caratterizzato da segmenti di ricerca per i quali non esistevano informazioni della community e che necessitavano di debugging intensivo e di numerose ablazioni.
Con questa release, non ci limitiamo a svelare il modello, ma condividiamo anche i nostri insight di ricerca attraverso una guida completa che svela i risultati che abbiamo ottenuto percorrendo il tracciato più complesso. Il cookbook è progettato per velocizzare il processo di apprendimento per chiunque voglia creare modelli MoE eccellenti. Offre infatti una miscela di insight di alto livello e dettagli tecnici granulari per la realizzazione di un LLM simile ad Arctic e per la creazione dell’intelligenza desiderata in modo efficiente ed economico, percorrendo il sentiero aperto invece di quello difficile.
Il cookbook affronta un’ampia serie di argomenti, inclusi pre‑addestramento, fine‑tuning, inferenza e valutazione, approfondendo anche aspetti quali modellazione, dati, sistemi e infrastruttura. Guarda in anteprima il sommario, che contiene più di 20 argomenti. Nel corso del prossimo mese pubblicheremo ogni giorno i nuovi post su questi argomenti sul blog Medium.com. Per esempio, presenteremo le nostre strategie per l’acquisizione e il perfezionamento dei dati web nella sezione “What data to use?” e parleremo di composizione dei dati e curriculum in “How to compose data”. Esploreremo in modo dettagliato l’architettura MoE nella sezione “Advanced MoE architecture”, in cui discuteremo anche del co‑design dell’architettura dei modelli e di prestazioni del sistema. Per chi desidera approfondire il tema della valutazione degli LLM, il blog “How to evaluate and compare model quality — less straightforward than you think” farà luce sulle complessità impreviste che abbiamo riscontrato.
Con questa iniziativa, desideriamo contribuire a una community aperta in cui l’apprendimento e il progresso collettivi rappresentino la norma, per espandere ulteriormente i confini di questo campo.
Codice open source
- Stiamo rilasciando punti di controllo dei modelli sia per la versione base che per la versione con instruction tuning di Arctic con licenza Apache 2.0. Questo significa che è possibile utilizzarli liberamente nelle proprie ricerche, così come nei prototipi e prodotti.
- La nostra pipeline di fine‑tuning basata su LoRA, completa di “recipe”, ovvero istruzioni di riferimento, consente il tuning efficace dei modelli su un singolo nodo.
- In collaborazione con NVIDIA TensorRT‑LLM e vLLM, stiamo sviluppando implementazioni di inferenza iniziali per Arctic, ottimizzate per l’uso interattivo con batch di taglia 1. Siamo entusiasti di lavorare con la community per far fronte alle complessità dell’inferenza con batch molto grandi e modelli MoE di grandissime dimensioni.
- Arctic è stato addestrato con una finestra di contesto di 4K. Nelle prossime settimane ci dedicheremo a sviluppare un’implementazione di finestra scorrevole con “attention sink” per supportare una capacità di generazione di sequenze illimitate. Siamo impazienti di lavorare con la community per l’estensione a una finestra di attenzione a 32K nel prossimo futuro.
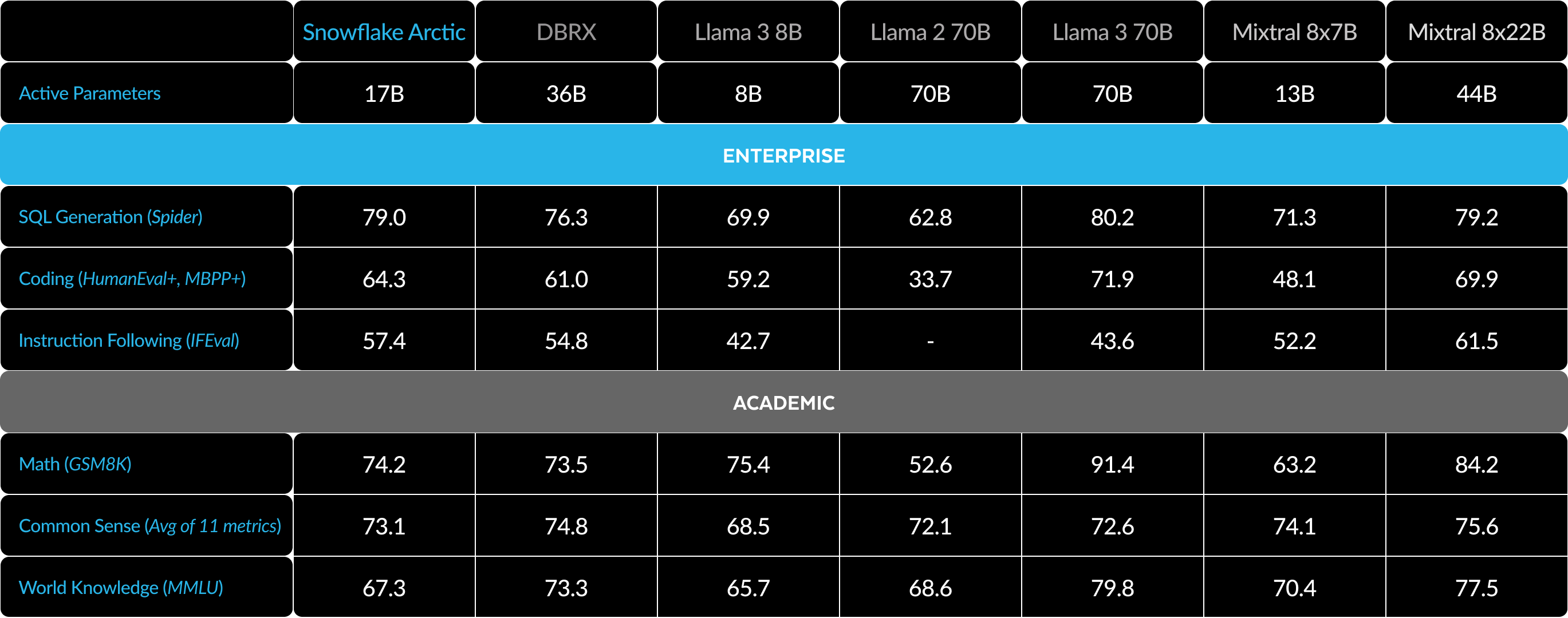
Metriche
La nostra attenzione dal punto di vista delle metriche è rivolta principalmente a quelle che definiamo metriche di enterprise intelligence, una raccolta di capacità critiche per i clienti enterprise che include Programmazione (HumanEval+ e MBPP+), Generazione di SQL (Spider) ed Esecuzione di istruzioni (IFEval).
Allo stesso tempo, è parimenti importante valutare i LLM in base alle metriche utilizzate dalla community per la valutazione, che includono conoscenza del mondo, ragionamento basato sul buon senso e capacità matematiche, e che definiamo benchmark accademici.
Di seguito è riportato un confronto tra Arctic e diversi altri modelli open source sulla base di metriche accademiche ed enterprise:
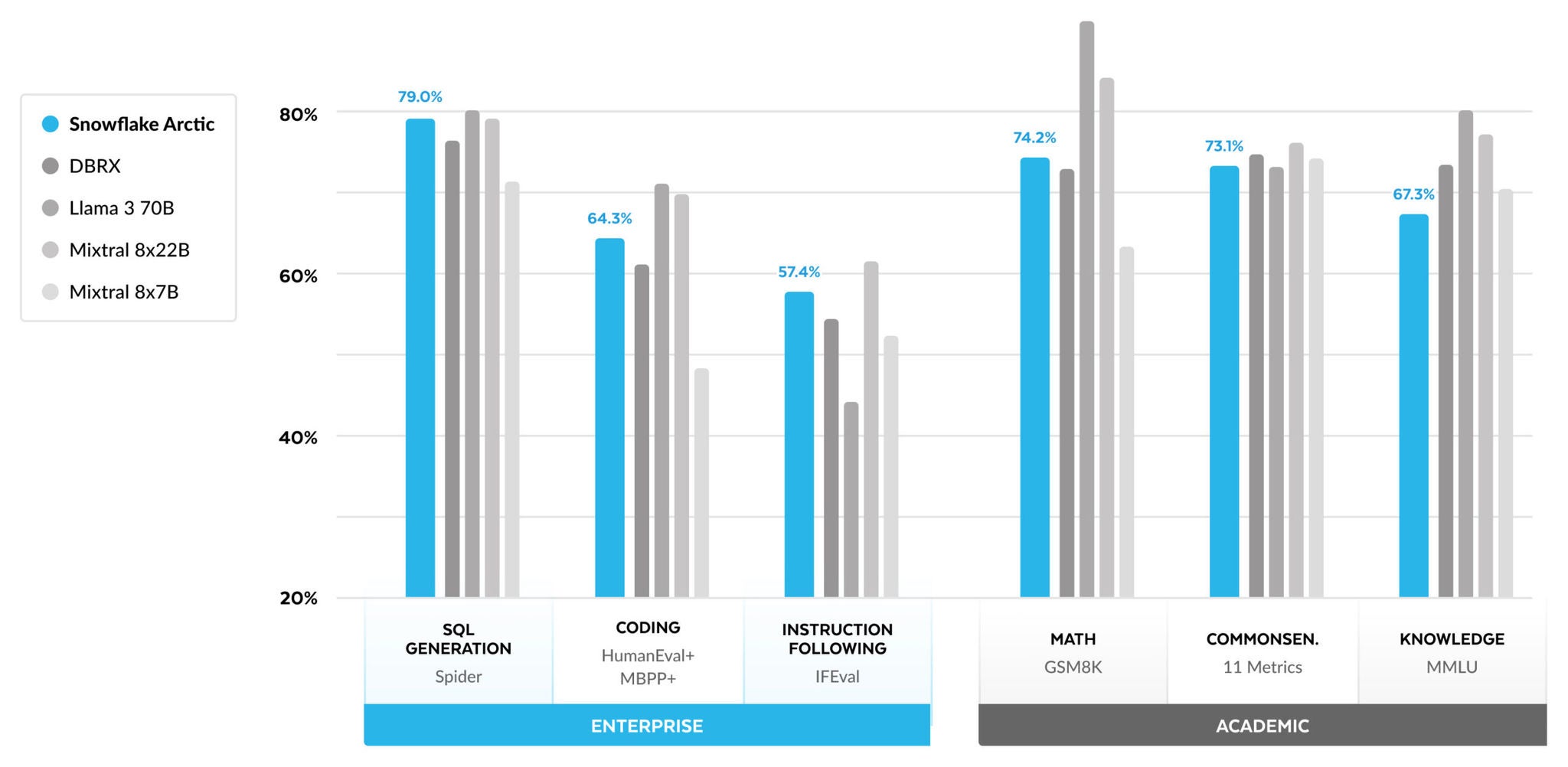
Per le metriche enterprise, Arctic dimostra prestazioni superiori agli altri modelli open source, indipendentemente dalla classe di risorse di calcolo. Per le altre metriche, raggiunge prestazioni migliori nella classe di risorse di calcolo e resta competitivo anche nei confronti dei modelli addestrati con budget per le risorse di calcolo più elevati. Snowflake Arctic è il modello open source migliore per i casi d’uso enterprise standard. Chi invece desidera addestrare il proprio modello partendo da zero con il costo totale di proprietà (TCO) più basso possibile, troverà particolarmente interessanti l’infrastruttura di addestramento e le ottimizzazioni dei sistemi descritte nel nostro cookbook.
Per i benchmark accademici, l’attenzione è stata posta su metriche di conoscenza del mondo come MMLU per rappresentare le prestazioni del modello. Con dati web e STEM di alta qualità, MMLU si sposta monotonamente verso l’alto come funzione dei FLOPS di addestramento. Poiché uno degli obiettivi era addestrare Arctic in modo efficiente con un budget per il training contenuto, è ovvio che le prestazioni MMLU sono inferiori a quelle dei recenti modelli best‑in‑class. In linea con queste osservazioni, prevediamo che il nostro attuale processo di addestramento avrà un budget per le risorse di calcolo dedicate al training superiore rispetto a quello di Arctic per superare le prestazioni MMLU di Arctic. Si noti che le prestazioni di conoscenza del mondo MMLU non sono necessariamente correlate al nostro focus sull’enterprise intelligence.
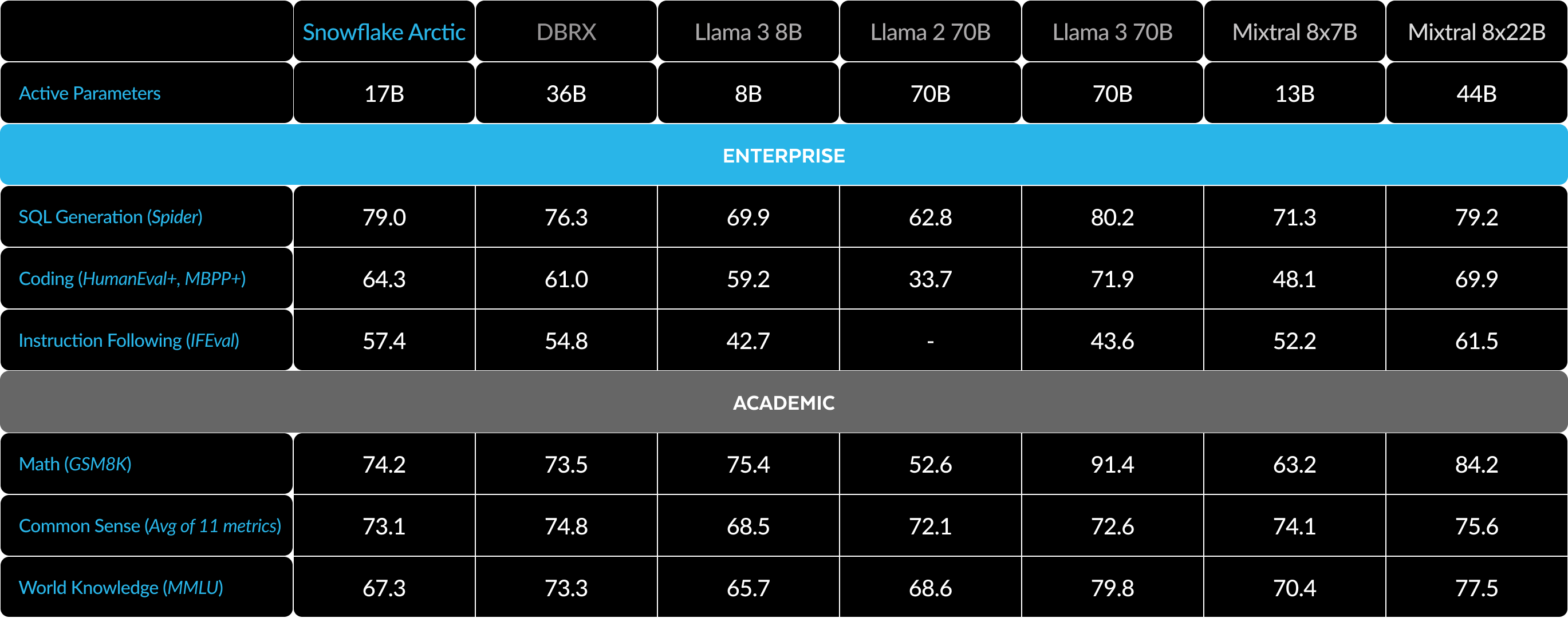
Tabella 3. Tutte le metriche: confronto tra Snowflake Arctic e DBRX, LLAMA‑3 8B, LLAMA-3 70B, Mixtral 8x7B, Mixtral 8x22B (con instruction‑tuning o varianti chat se disponibili).1 2 3
Come iniziare con Arctic
Snowflake AI Research ha di recente annunciato e reso open source la famiglia di modelli Arctic Embed che raggiunge SoTA nel recupero MTEB. Siamo impazienti di collaborare con la community allo sviluppo della prossima generazione della famiglia di modelli Arctic. Partecipa al nostro Data Cloud Summit dal 3 al 6 giugno per saperne di più.
Ecco come possiamo collaborare su Arctic a partire da oggi:
- Vai su Hugging Face per scaricare direttamente Arctic e utilizza il nostro repository Github per recipe su inferenza e fine‑tuning.
- Per un’esperienza serverless in Snowflake Cortex, i clienti Snowflake con un metodo di pagamento in archivio potranno accedere gratuitamente a Snowflake Arctic fino al 3 giugno. Si applicano limiti giornalieri.
- Arctic è accessibile dal tuo model garden o catalogo preferito, inclusi Amazon Web Services (AWS), Lamini, Microsoft Azure, NVIDIA API catalog, Perplexity, Replicate e Together nei prossimi giorni.
- Chatta con Arctic! Prova subito una demo live su Streamlit Community Cloud o su Hugging Face Streamlit Spaces, con un’API basata sulla tecnologia dei nostri amici di Replicate.
- Accedi a mentoring e crediti che possono aiutarti a costruire la tua applicazione con Arctic durante il nostro Community Hackathon su Arctic.
Infine, non dimenticare di leggere la prima edizione del nostro cookbook di recipe per scoprire come costruire i tuoi modelli MoE personalizzati nel modo più economico possibile.
Riconoscimenti
Desideriamo ringraziare AWS per la collaborazione alla creazione dell’infrastruttura e del cluster di addestramento di Arctic, e NVIDIA per la collaborazione e il supporto di Arctic su NVIDIA TensorRT-LLM. Ringraziamo inoltre la community open source per aver prodotto i modelli, i data set, gli insight per le data recipe che abbiamo utilizzato per rendere possibile questa release. I nostri ringraziamenti vanno anche ai nostri partner in AWS, Microsoft Azure, NVIDIA API catalog, Lamini, Perplexity, Replicate e Together AI per la loro collaborazione alla realizzazione di Arctic
1. Le 11 metriche per Comprensione del linguaggio e Ragionamento includono ARC‑Easy, ARC‑Challenge, BoolQ, CommonsenseQA, COPA, HellaSwag, LAMBADA, OpenBookQA, PIQA, RACE e WinoGrande.
2. I punteggi di valutazione per HumanEval+/MBPP+ v0.1.0 sono stati ottenuti utilizzando (1) bigcode-evaluation-harness con template di chat specifici per il modello e post-processing allineato, e (2) decodifica greedy. Per garantire la coerenza, abbiamo valutato tutti i modelli con la nostra pipeline. Abbiamo poi verificato la coerenza dei risultati delle nostre valutazioni con la leaderboard EvalPlus e constatato che i numeri prodotti con la nostra pipeline superano di alcuni punti quelli di EvalPlus per tutti i modelli. Questo ci permette di affermare con sicurezza che il nostro metodo di valutazione di ogni modello è il migliore possibile.
3. I punteggi IFEval sono la media di prompt_level_strict_acc e inst_level_strict_acc
Articolo di
