La valanga Apache Iceberg: in che modo il formato Open Table cambia il volto dei data lake

L’archiviazione dei dati si è evoluta, dai database ai data warehouse e ai data lake espansivi, con architetture che rispondono a esigenze aziendali e di dati diverse. I database tradizionali eccellevano nei workload strutturati e transazionali, ma con la crescita dei volumi di dati faticavano a scalare le prestazioni. Il data warehouse risolveva i problemi di prestazioni e scalabilità ma, come i database che lo precedevano, si affidava a formati proprietari per creare sistemi verticalmente integrati. I sistemi di data lake sono passati a formati più aperti, ma mancavano dei vantaggi funzionali offerti dai data warehouse, come transazioni ACID-compliant, governance completa e altro ancora. Alla fine, gli utenti si sono trovati bloccati tra due opzioni: una piattaforma completamente integrata con solo soluzioni proprietarie o un data lake vendor-neutral ad alta intensità di risorse e sviluppato da loro.
Ora non c’è più bisogno di scegliere. Con l’avvento e l’adozione generalizzata di Apache Iceberg™, è emerso l’open data lakehouse, che combina il meglio dei data warehouse e dei data lake disaccoppiando l’open storage e la capacità di calcolo per dotare i team dati della flessibilità e del controllo delle architetture aperte e delle alte prestazioni dei data warehouse. Per questo Snowflake sta adottando pienamente questo formato di tabella aperto. Ora i clienti possono ottenere i vantaggi di archiviare i dati in un formato completamente aperto e interoperabile, sfruttando al contempo la potenza della piattaforma semplice, connessa e affidabile Snowflake. Di conseguenza, le organizzazioni possono accelerare le loro strategie di lakehouse open e fornire analisi avanzate e AI più rapidamente.
Che cos’è Iceberg?
Al centro di questa rivoluzione dell’open data lakehouse c’è Iceberg, un formato di tabella open source per grandi workload analitici. Iceberg non è un motore di calcolo e nemmeno un database. È una descrizione di come un insieme di file può comportarsi come una tabella di database. Poiché la descrizione è aperta e indipendente dal motore, una tabella Iceberg è intrinsecamente vendor neutral. Questa combinazione di funzionalità e neutralità sta aprendo la strada all’evoluzione dell’architettura: il lakehouse aperto, in cui capacità di calcolo, formato e storage sono tutti disaccoppiati tra loro.
Le Iceberg Tables diventano interoperabili mantenendo la conformità ACID aggiungendo un livello di metadati ai file di dati nell’object storage dell’utente. Un catalogo esterno tiene traccia degli ultimi metadati delle tabelle e aiuta a garantire la coerenza tra più reader e writer.
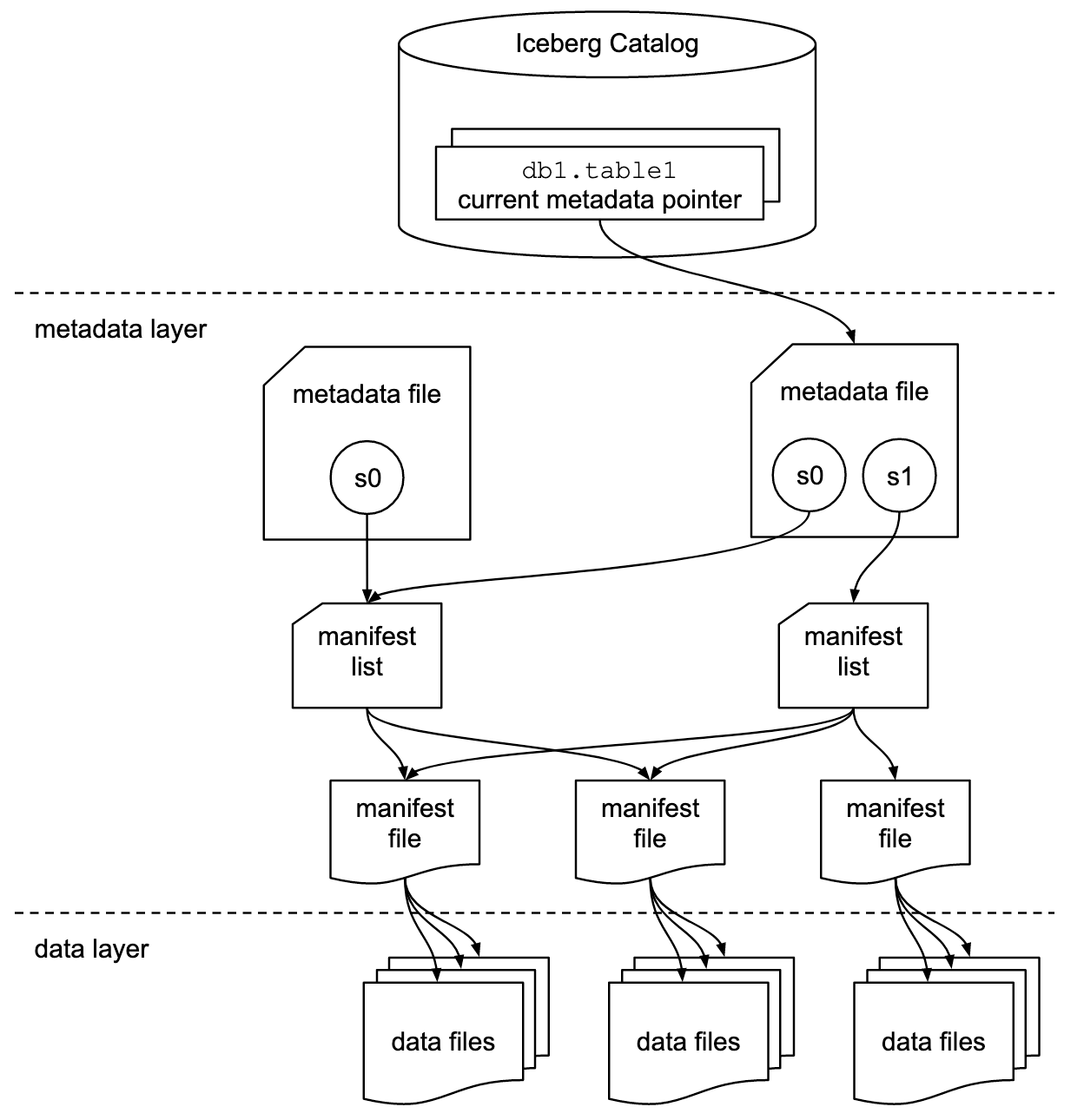
In poche parole: Iceberg è metadati. I file di dati sono monitorati singolarmente, anziché a livello di directory, da file manifest, elenchi manifest e file di metadati. Questo livello di metadati ben coordinato significa che Iceberg non cade vittima di alcuni dei problemi più dannosi che altri formati di tabella comuni (come Apache Hive™) incontrano a causa della loro stretta dipendenza da una struttura di directory fisica.
Perché dovresti preoccuparti di Iceberg?
Senza l’adozione delle Iceberg Tables, i team dati sono costretti a dedicare molto tempo e risorse alla gestione delle migrazioni e della governance prima di riuscire a cogliere le opportunità offerte dalle nuove tecnologie e soluzioni. Iceberg elimina questo compromesso. Offrendo un formato di storage completamente interoperabile che consente ai data engineer di possedere e controllare il proprio livello di storage, Iceberg offre la flessibilità necessaria per sfruttare qualsiasi piattaforma dati o motore di calcolo moderno compatibile. Questo significa che i team dati possono passare dall’idea all’impatto in tempi record, senza compromessi, e produrre un impatto alla velocità richiesta dalle aziende di oggi.
Ecco come i team dati possono trarre vantaggio dalle loro architetture lakehouse aperte sulle tabelle Iceberg:
Maggiore produttività degli sviluppatori: Iceberg consente a sviluppatori e data engineer di lavorare come se utilizzassero un database relazionale standard come Postgres, ma possono scalare fino a petabyte di dati.
Possibilità di scrivere una volta, leggere ovunque: Iceberg è compatibile con tutti gli strumenti di analisi più recenti senza migrazione. Cambia motore o utilizza più motori contemporaneamente senza penalità.
Compute più veloce: Il layer dei metadati di Iceberg è ottimizzato per il cloud storage, consentendo il pruning anticipato di file e partizioni con un overhead IO minimo.
Poiché è uno standard open source, disponibile per qualsiasi strumento o motore, Iceberg può portare questi incredibili vantaggi a qualsiasi organizzazione. In definitiva, questa apertura è vantaggiosa per il cliente.
Essere più open
Snowflake mette da sempre gli utenti al primo posto. Con le tecnologie in continua evoluzione, Snowflake continua a dare la priorità ai propri clienti supportando iniziative open source. I vantaggi sono evidenti: Quando gli utenti hanno la scelta, ottengono i vantaggi. Questo impegno per l’open source è evidenziato dal contributo di Snowflake a Iceberg per consentire una gestione efficiente e governata del data lake con evoluzione dello schema, partizionamento e gestione delle transazioni.
Anche se Iceberg specifica come dovrebbero comportarsi i cataloghi, la community Iceberg si è volutamente tenuta alla larga dal fornirne uno. Poiché il catalogo gestisce i metadati della tabella e contribuisce a garantire la coerenza tra più reader e writer, questa assenza di un catalogo standardizzato ha creato il rischio di reintrodurre i compromessi che Iceberg doveva risolvere. Nello specifico, costringerebbe ancora una volta le organizzazioni a scegliere tra due opzioni: implementare, gestire e mantenere autonomamente un catalogo o sfruttare di nuovo una soluzione di un fornitore con il potenziale di rimanere bloccati. Constatando questa lacuna, Snowflake ha raddoppiato il suo impegno per gli standard aperti e lo sviluppo guidato dalla community creando e quindi rendendo disponibile un catalogo Iceberg e contribuendo alla Apache Software Foundation, ora nota come Apache Polaris (incubating), a luglio 2024.
Polaris è un catalogo Iceberg open source completo. Dal punto di vista del design, Polaris è vendor-neutral e la sua struttura di governance e lo sviluppo guidato dalla community lo garantiscono. L’implementazione dell’API REST Iceberg da parte di Polaris aiuta a garantire la coerenza tra più reader e writer e fornisce un mezzo per aggiornare atomicamente le tabelle da uno stato all’altro.
Polaris fornisce anche un mezzo centralizzato per proteggere i dati di un’organizzazione. Inizialmente creata come catalogo Iceberg interoperabile, la roadmap Polaris ora include il supporto per una più ampia gamma di formati e tipi di oggetti di dati per garantire che gli utenti possano catalogare tutti i propri dati da un unico posto.
Creare un data lakehouse open
L’obiettivo di Snowflake è aiutare le organizzazioni a definire e accelerare le loro ambizioni di apertura del lakehouse per sbloccare un maggiore impatto con meno complessità.
Iniziare:
Inizia ad attivare i dati archiviati in un cloud storage provider senza vincoli, creando Iceberg Tables direttamente dai file Parquet esistenti in Snowflake.
Applica controlli di sicurezza e governance completi all’interno della piattaforma Snowflake tramite Horizon Catalog.
Gestisci l’accesso sicuro a più motori con Snowflake Open Catalog, un servizio completamente gestito per Polaris che conserva la possibilità di autogestirsi mantenendo intatti i controlli di accesso basati sui ruoli (RBAC), gli spazi dei nomi e le definizioni, indipendentemente da dove è ospitato il catalogo, eliminando quasi la complessità della migrazione.
Inoltre, il motore dati elastico zero-ops di Snowflake continua a evolversi con funzionalità progettate appositamente per migliorare le prestazioni e l’efficienza delle query per le tabelle Iceberg. I clienti ottengono vantaggi come tecniche di pruning migliorate, che riducono le richieste di cloud storage e accelerano l’esecuzione delle query, e Adaptive Scan, che consente di eseguire più rapidamente query ad alta intensità di scansione. Queste funzionalità sono pronte all’uso, senza la necessità di passare attraverso una nuova implementazione, sbloccando così prestazioni migliorate e riducendo l’overhead operativo.
Scopri come WHOOP sta ripensando l’architettura dati con Snowflake e Iceberg, consentendo di risparmiare 20 ore di capacità di calcolo al giorno e migliorando l’accessibilità dei dati in tutta l’organizzazione.
Scopri di più
Partecipa all’Iceberg Summit con Snowflake, un evento di due giorni che si terrà a San Francisco l’8 aprile e virtualmente il 9 aprile. Siamo entusiasti di supportare la community come sponsor principale dell’evento inaugurale.
Sintonizzati sul webinar Data Engineering Connect: Building Pipelines for Open Lakehouse il 29 aprile, con due demo virtuali e un laboratorio pratico.
Leggi “The Essential Guide to Modernizing Data Lakes for AI with Snowflake”, che offre una guida esperta per creare le basi per sbloccare il pieno potenziale dei dati e dell’AI.
Articolo di
