Snowflake annonce des nouveautés pour le data warehouse, le data lake et le data lakehouse dans le Data Cloud

Au fil des ans, le paysage technologique de la gestion des données a donné naissance à différents modèles d’architecture, dont chacun est judicieusement conçu pour prendre en charge des cas d’usage et des besoins spécifiques. Ces modèles incluent à la fois des modèles de stockage centralisés, tels que le data warehouse, le data lake et le data lakehouse, et des modèles distribués, tels que le data mesh. Chacune de ces architectures présente des avantages et des inconvénients qui lui sont propres. Historiquement, de nombreux outils et plateformes commerciales ont été conçus pour s’aligner avec un modèle d’architecture spécifique. Les entreprises ont rencontré des difficultés pour s’adapter à l’évolution de leurs besoins professionnels, impactant ainsi l’architecture de données.
Chez Snowflake, nous ne pensons pas qu’un modèle unique pour tous nos clients permette de répondre à leurs besoins. Nous cherchons au contraire à aider nos clients en leur fournissant une plateforme qui leur permette de créer des architectures en fonction de ce qui fonctionne dans leur entreprise et de les adapter au fil du temps. Bien souvent, nos clients ont vérifié la loi de Conway. Tout évolue : les cas d’usage, les besoins, la technologie. L’infrastructure de données doit pouvoir s’adapter et évoluer avec ces changements. Nous nous engageons à offrir à nos clients le choix et la possibilité de s’adapter tout en maintenant nos piliers fondamentaux de sécurité et de gouvernance renforcées, de performances optimales et de simplicité.
Par exemple, les clients qui ont besoin d’un entrepôt centralisé de données à la fois diversifiées et nombreuses (fichiers JSON, fichiers texte, documents, images et vidéos) ont créé leur data lake avec Snowflake. Par ailleurs, de nombreux clients équipés, à l’échelle de l’entreprise, d’un référentiel de tables hautement optimisées pour SQL, ainsi qu’un grand nombre de workloads et de rapports de Business Intelligence simultanés, ont créé un data warehouse sur Snowflake. Les clients nécessitant un modèle hybride pour prendre en charge différents outils et langages ont créé un data lakehouse. De nombreux clients préfèrent que chaque équipe garde le contrôle de ses données (plutôt que d’opter pour une équipe centralisée) et respecte des normes spécifiques pour gérer l’infrastructure. Ils ont donc utilisé Snowflake comme plateforme pour leur data mesh.
Pour faire face à ces besoins de gestion de données en constante évolution, nous lançons de nouvelles fonctionnalités pour accompagner nos clients sur tous ces modèles.
Apache Iceberg pour un datalakehouse ouvert
L’architecture de data lakehouse a été créée pour combiner les avantages d’adaptabilité et de flexibilité des data lakes avec la gouvernance, l’application de schémas et les propriétés transactionnelles des data warehouses. Depuis le départ, la plateforme Snowflake a été proposée en tant que service, sous forme de stockage optimisé, de calcul multi-cluster élastique et de services cloud. Depuis son lancement en 2015, notre stockage sous forme de tables entièrement gérées vient s’ajouter au stockage d’objets et est similaire à ce que le marché connaît aujourd’hui avec les formats open source tels que Apache Iceberg, Apache Hudi et Delta Lake. Le format de tables de Snowflake étant entièrement géré, les fonctionnalités telles que le chiffrement, la cohérence des transactions, la gestion des versions et Time Travel sont fournies automatiquement.
Si de nombreux clients apprécient la simplicité d’une solution de stockage entièrement gérée et d’un unique moteur de calcul multi-cluster et multilingue pour alimenter différents workloads, certains préfèrent gérer leur propre stockage depuis des formats ouverts. C’est pourquoi nous avons ajouté la prise en charge d’Apache Iceberg. Bien qu’il existe d’autres formats de tables ouverts, nous considérons Apache Iceberg comme la norme pour les formats de tables ouverts pour de nombreuses raisons. Nous privilégions donc ce format pour mieux servir nos clients.
Les Iceberg Tables (bientôt en public preview) sont un type de table unique qui tire parti de la facilité de gestion et des excellentes performances de Snowflake pour les données stockées en externe dans un format ouvert. Les Iceberg Tables offrent également une importation plus simple et plus abordable, sans nécessiter une ingestion de données en amont. Pour offrir à nos clients une intégration flexible de Snowflake à leur architecture, les Iceberg Tables peuvent être configurées pour utiliser Snowflake ou un service externe, tel que AWS Glue, comme catalogue de tables permettant de suivre les métadonnées, grâce à une simple instruction SQL d’une ligne qui bascule sur Snowflake sous forme d’opération utilisant uniquement des métadonnées.
Indépendamment d’une configuration de catalogue Iceberg Tables, de nombreux éléments restent identiques :
- Les données sont stockées en externe dans le compartiment de stockage du client.
- Les requêtes de Snowflake sont en moyenne deux fois plus performantes qu’avec les External Tables.
- De nombreuses autres fonctionnalités sont également disponibles, telles que le partage de données, les commandes d’accès basées sur les rôles, Time Travel, Snowpark, Object Tagging, Row Access Policies et les politiques de masquage.
Lorsque les Iceberg Tables utilisent Snowflake comme catalogue de tables pour gérer les métadonnées, d’autres avantages viennent s’ajouter :
- Snowflake peut effectuer des opérations d’écriture comme INSERT, MERGE, UPDATE et DELETE.
- Opérations automatiques de maintenance de stockage telles que le compactage, l’expiration des aperçus et la suppression des fichiers orphelins.
- Cluster automatique pour des requêtes plus rapides (en option).
- Apache Spark peut utiliser le SDK du catalogue Iceberg de Snowflake pour lire les Iceberg Tables sans nécessiter de ressources de calcul Snowflake.
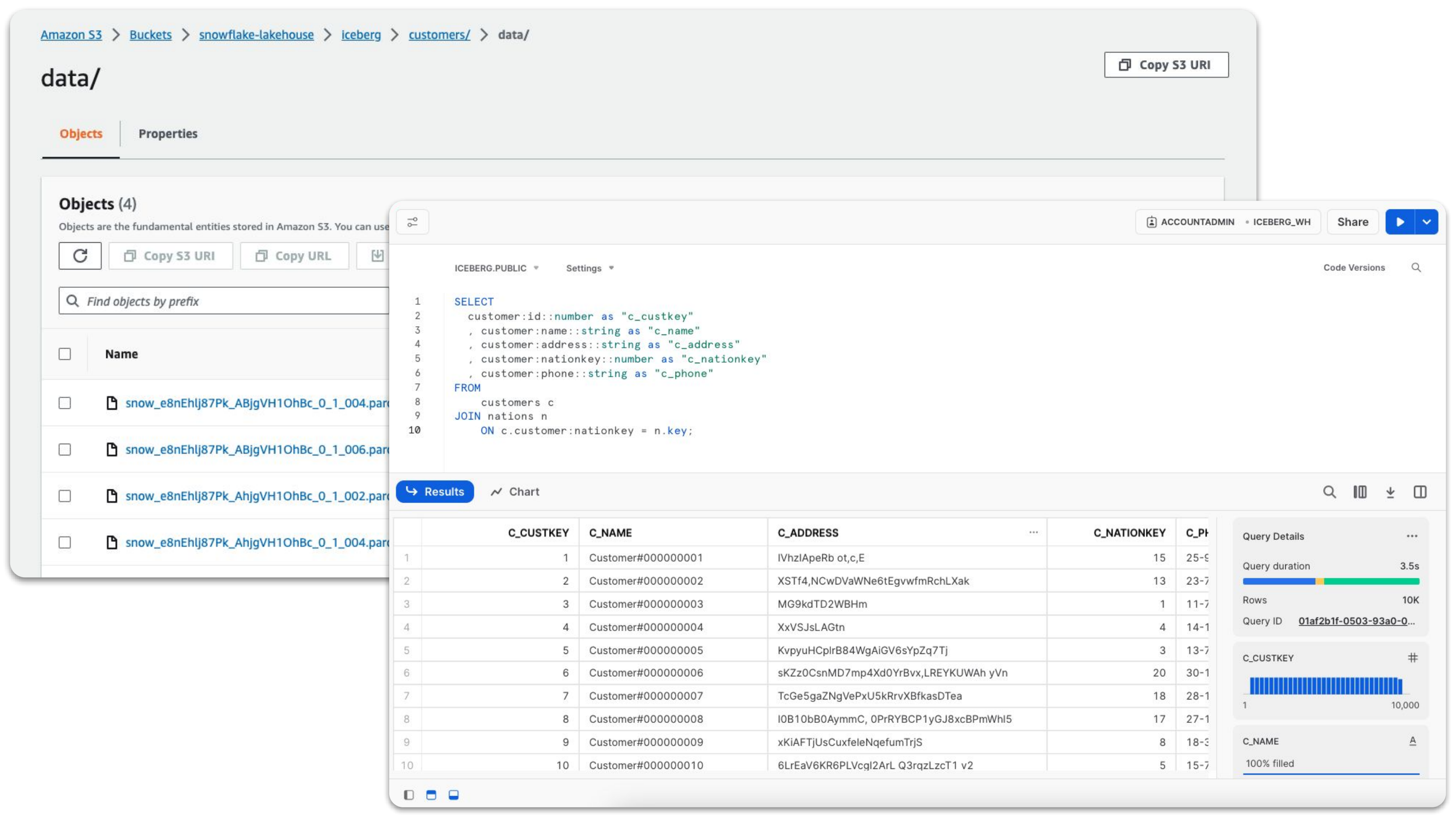
Prise en charge étendue des données semi-structurées et non-structurées pour les datalakes
Un data lake est un modèle d’architecture attractif en raison de sa capacité à stocker des objets avec quasiment n’importe quel format de fichier ou schéma, à très grande échelle et à un coût relativement faible. Au lieu de définir le type de schéma en amont, les utilisateurs peuvent définir le schéma et les données dont ils ont besoin pour leur cas d’usage. Snowflake prend en charge depuis longtemps les types de données semi-structurées et les formats de fichiers tels que JSON, XML et Parquet. Depuis peu, nous prenons également en charge le stockage et le traitement des données non-structurées telles que les documents PDF, les images, les vidéos et les fichiers audio. Que vos fichiers soient enregistrés sur le stockage géré par Snowflake (stockage interne) ou sur un stockage d’objets externe (stockage externe), nous vous offrons de nouvelles fonctionnalités prenant en charge ces types de données et cas d’usage.
Nous avons élargi notre prise en charge des données semi-structurées avec la possibilité d’ajouter facilement le schéma des fichiers JSON et CSV (bientôt disponible pour tous nos clients) dans un data lake. Le schéma des données semi-structurées tend à évoluer avec le temps. Les systèmes qui génèrent des données ajoutent de nouvelles colonnes pour inclure des informations supplémentaires, nécessitant des tables en aval pour évoluer en conséquence. Pour remédier à ce problème, nous avons ajouté la prise en charge de l’évolution du schéma de tables (bientôt disponible pour tous nos clients).

Pour les cas d’usage impliquant des fichiers tels que des documents PDF, des images, des vidéos ou des fichiers audio, vous pouvez désormais utiliser Snowpark for Python/Scala (disponible pour tous nos clients) pour traiter tout type de fichier de façon dynamique. Les data engineers et data scientists peuvent tirer parti du moteur rapide de Snowflake grâce à un accès sécurisé à des bibliothèques open source pour le traitement des images, de la vidéo, de l’audio et bien plus encore.
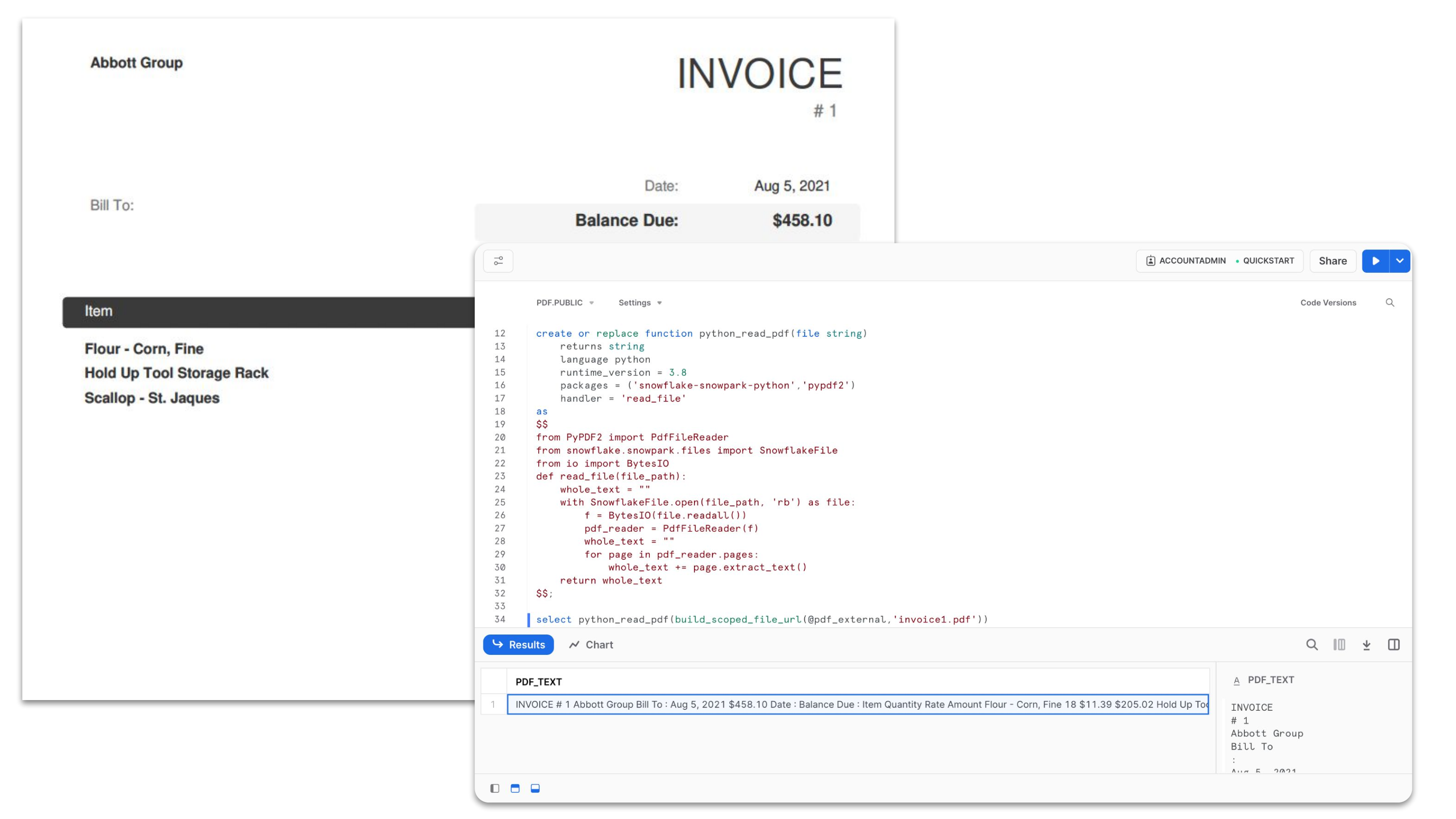
SQL plus rapide et plus avancé pour un datawarehouse
SQL est de loin le langage le plus courant pour les workloads de data warehouse. Nous continuons de repousser les limites des types de calcul qui peuvent être générés grâce au SQL. Par exemple, grâce à la prise en charge récente des AS OF JOIN (bientôt en private preview), les data analysts peuvent désormais créer des requêtes bien plus simples qui combinent des données de séries temporelles. Ces cas d’usage sont courants dans le domaine des services financiers, l’Internet des objets et les cas d’usage de feature engineering, pour lesquels les jointures sur les horodatages ne sont pas des correspondances exactes, mais plutôt approximatives avec l’enregistrement précédent ou suivant. Nous améliorons également notre prise en charge des analyses avancées dans Snowflake en augmentant la taille limite des fichiers pour le chargement (bientôt disponible en private preview). Vous pouvez désormais charger des objets volumineux (jusqu’à 128 Mo), souvent nécessaires dans les cas d’usage impliquant le traitement du langage naturel, l’analyse des images et l’analyse des opinions.
Nous maintenons notre engagement à améliorer les performances et à réduire les dépenses de nos clients. Grâce à nos récentes optimisations, nos clients pourront améliorer leurs performances et réduire leurs dépenses de nombreuses façons :
- Les requêtes ad-hoc sur les entrepôts utilisant des cas d’usage ML lourds en mémoire sont désormais plus rapides et plus rentables grâce à Query Acceleration Service pour Snowpark Optimized Warehouses (disponible pour tous nos clients).
- Les expressions SELECT contenant les clauses ORDER BY et LIMIT sont plus rapides, notamment sur les grandes tables, grâce à l’algorithme « top-k pruning » (bientôt disponible pour tous nos clients).
- Les frais de maintenance Materialized View sont réduits de plus de 50 % grâce aux nouvelles efficacités des entrepôts (disponible pour tous nos clients).
- Les requêtes utilisant des fonctions non-déterministes comme ANY_VALUE() ou MODE() peuvent désormais utiliser un cache de résultat pour optimiser leurs performances. Selon notre analyse, certains modèles de requêtes ont généré une réduction de 13 % des crédits pour les requêtes impactées (disponible pour tous nos clients).
- Les expressions INSERT sont plus rapides grâce à l’ajout de la prise en charge dans Query Acceleration Service (disponible en private preview).
- Une nouvelle fonctionnalité permet d’estimer les coûts de maintenance en amont et en cours pour le cluster automatique sur une table spécifique (en private preview).
Premiers pas
Nous sommes ravis que nos clients puissent bénéficier de ces nouvelles fonctionnalités au sein d’une seule et même plateforme, ce qui leur permet de continuer à créer et adapter l’architecture de leur choix avec le Data Cloud. Pour les fonctionnalités ci-dessus disponibles en private preview, contactez votre responsable de compte Snowflake pour y avoir accès. Pour les fonctionnalités présentées en public preview ou déjà disponibles pour tous nos clients, consultez les notes de version et la documentation pour en savoir plus et vous lancer.
Pour en savoir plus sur la façon dont Snowflake prend en charge les modèles d’architecture décrits dans cette publication, visitez nos pages pour le data warehouse, le data lake, le data lakehouse et le data mesh.
Vous souhaitez voir ces fonctionnalités en action ? Découvrez la session sur Snowday.
Déclarations prévisionnelles
Ce communiqué de presse contient des déclarations prévisionnelles expresses et implicites, y compris des déclarations concernant (i) la stratégie commerciale de Snowflake, (ii) les produits, services et offres technologiques de Snowflake, y compris ceux qui sont en cours de développement ou pas encore communément disponibles, (iii) la croissance du marché, les tendances et les considérations concurrentielles et (iv) l’intégration, l’interopérabilité et la disponibilité des produits de Snowflake avec et sur des plateformes tierces. Ces déclarations prévisionnelles sont soumises à un certain nombre de risques, d’incertitudes et d’hypothèses, y compris ceux décrits dans nos rapports déposés auprès de la Securities and Exchange Commission. À la lumière de ces risques, incertitudes et hypothèses, les résultats réels pourraient différer matériellement et négativement de ceux anticipés ou supposés dans les déclarations prévisionnelles. Ces déclarations ne sont valables qu’à la date à laquelle elles ont été faites pour la première fois. Sauf si la loi l’exige, Snowflake n’est tenu à aucune obligation de mettre à jour les déclarations contenues dans ce communiqué de presse. Par conséquent, vous ne devez considérer aucune déclaration prévisionnelle comme une prédiction d’événements futurs.
Toutes les futures informations sur le produit contenues dans ce communiqué de presse visent à définir l’orientation générale du produit. La date réelle de mise à disposition d’un produit, d’une fonction ou d’une fonctionnalité peut être différente de ce qui est énoncé dans ce communiqué de presse.
Authors


