Avec le ML, Snowflake accélère et affine la prise de décisions

Les data analysts n’ont pas un métier facile. Pour suivre le rythme de la croissance explosive des données au sein de leur entreprise, ils doivent trouver le juste équilibre entre tout le travail nécessaire pour extraire des informations précises et la nécessité de prendre rapidement des décisions.
L’analyse des données demande un temps et des efforts considérables pour comprendre et expliquer les anomalies sans délai. De plus, les outils existants pour les analyses courantes, pourtant destinés à leur faciliter la tâche, ne sont pas toujours en mesure de prendre en charge le volume de données qui les attend quotidiennement. Ainsi, les data analysts peinent à surmonter tous ces obstacles, tout en assurant la sécurité du traitement des données qu’ils utilisent dans le cadre de leurs analyses avancées.
Les algorithmes de machine learning peuvent résoudre certains de ces défis. Toutefois, le manque de connaissances en programmation et en data science, ainsi que la complexité de l’infrastructure de calcul, freinent l’adoption du ML par les analystes.
Chez Snowflake, nous avons la conviction que les analystes peuvent tirer parti des avantages du ML, à condition d’être capables de réduire la complexité de ces environnements.
C’est pourquoi nous avons annoncé, lors du Summit 2023, le lancement en public preview de plusieurs fonctionnalités basées sur le ML : ces fonctions SQL familières s’appuient sur le ML pour aider les analystes à prendre des décisions plus éclairées et ce, plus rapidement. Dans ce blog, nous allons vous expliquer précisément comment ces fonctions basées sur le ML y parviennent.
Forecasting
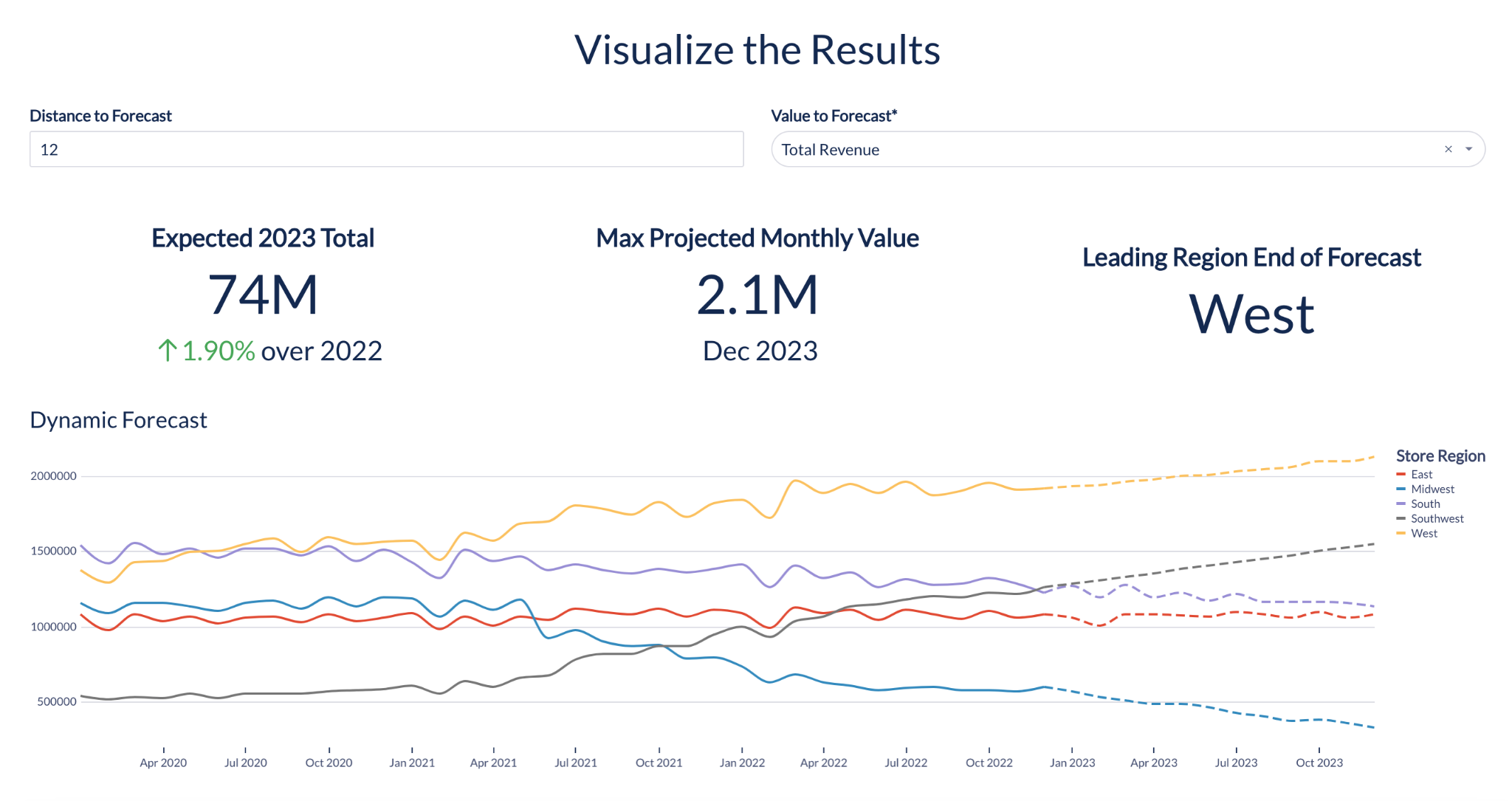
Les analystes peuvent désormais utiliser la nouvelle fonction Forecasting pour formuler des prévisions de séries temporelles plus précises, avec une gestion automatisée de la saisonnalité, de l’évolutivité et bien plus encore.
Grâce à cette fonctionnalité, les analystes peuvent entraîner des modèles ML destinés à produire constamment des prédictions. Avec Forecasting, il est possible de générer une estimation prévisionnelle, ainsi qu’une plage d’estimations, appelé intervalle de prédiction. Cela permet de définir une plage probable pour les prévisions.
Cette fonctionnalité facilite la tâche des analystes qui, par exemple, veulent estimer le chiffre d’affaires futur en s’appuyant sur des prévisions précises des volumes de ventes par boutique, sans avoir besoin de faire appel à leur équipe de data science pour les aider.
Avec Forecasting, les analystes peuvent générer des prédictions pour une seule série temporelle ou pour plusieurs catégories dans une série temporelle unique. Par exemple, dans le secteur du retail, il est possible de formuler des prévisions de ventes par boutique, plutôt que de prédire les ventes agrégées d’un article sur l’ensemble des boutiques. Ainsi, la fonction Forecasting permet de rendre chaque prévision plus granulaire, avec simplement une seule ligne de code supplémentaire.
En outre, vous pouvez améliorer la qualité de vos prédictions en incluant des variables exogènes, qu’elles soient numériques ou catégoriques. Par exemple, si vous savez que les jours fériés ont un impact important sur vos volumes de ventes retail, vous pouvez inclure ces jours fériés comme variables exogènes pour améliorer la précision de vos prévisions.
Forecasting vous permet également de générer des prédictions à des horizons personnalisés, comme 4 heures, 1 jour ou 7 jours. Nous avons bon espoir que cette flexibilité vous aidera à obtenir des prévisions adaptées à vos besoins et calendriers spécifiques, sans avoir à demander de l’aide à votre équipe de data science.
Anomaly Detection
Et si les analystes pouvaient exploiter le ML pour identifier les anomalies et déclencher des alertes ? C’est maintenant possible, grâce à notre nouvelle fonction Anomaly Detection. Les analystes peuvent également l’utiliser pour détecter les événements anormaux sur lesquels enquêter afin de repérer les activités suspectes, ainsi que les situations à exclure des analyses futures, car il est peu probable qu’elles se produisent à nouveau.
Anomaly Detection prédit spécifiquement les anomalies pour une série temporelle unique ou plusieurs catégories d’une série temporelle. Cette méthode de détection des anomalies basée sur le ML peut s’avérer utile si vous souhaitez remplacer les seuils statiques par un modèle de base intelligent et dynamique pour l’analyse de vos données.
Afin de mieux maîtriser le nombre de faux positifs soulevés par cette fonction, vous pouvez ajuster l’intervalle de prédiction utilisé pour repérer les anomalies. Vous pouvez ensuite utiliser Snowflake Tasks et Alerts pour recevoir automatiquement des notifications lorsqu’une anomalie est détectée, comme expliqué ci-dessous.
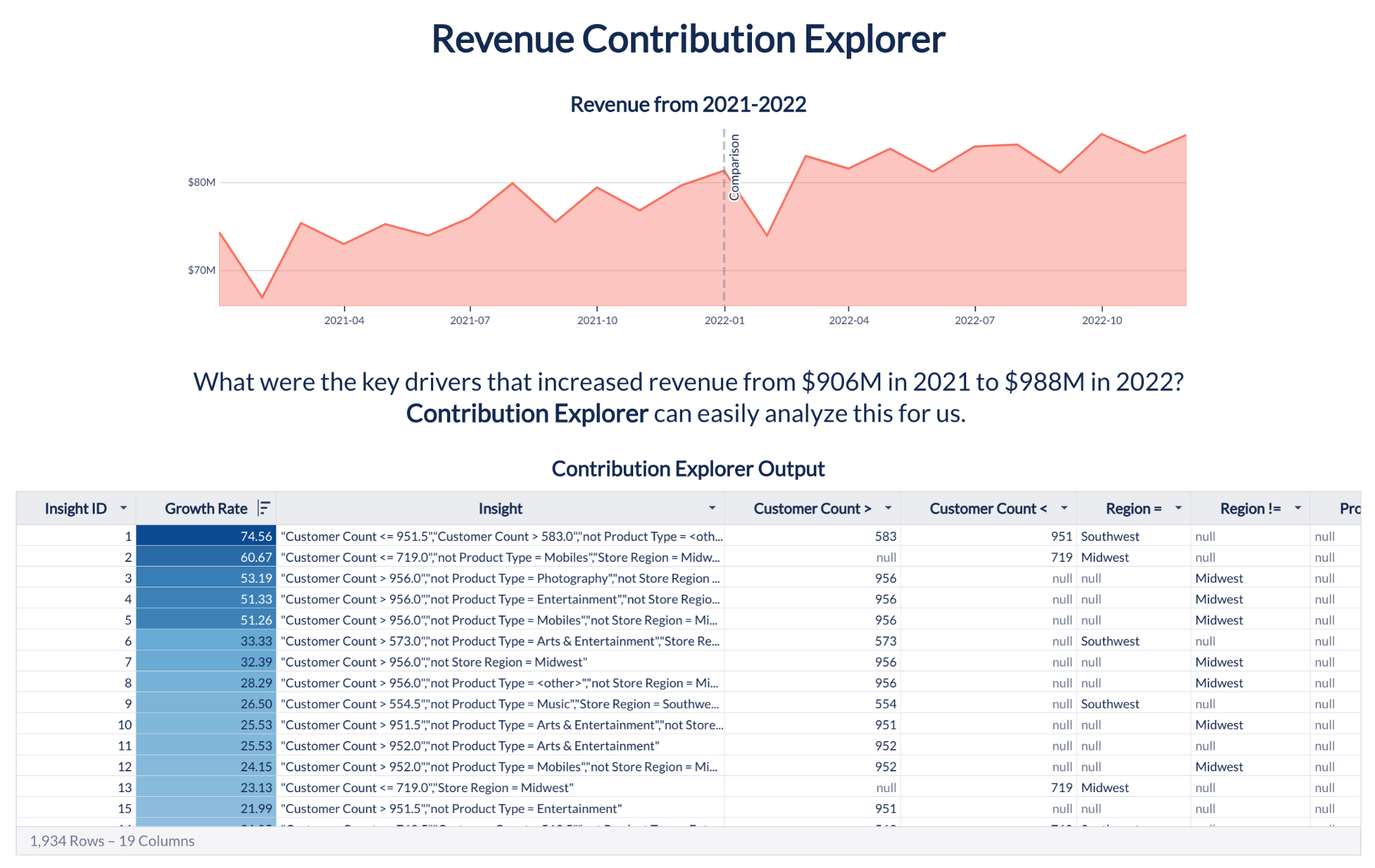
Contribution Explorer
Les analystes peuvent maintenant exploiter le ML pour identifier rapidement les dimensions contribuant à la modification d’un indicateur donné entre deux intervalles de temps définis par l’utilisateur. Si vous constatez une anomalie dans un indicateur clé tel que les ventes ou l’utilisation, il est normal que vous en recherchiez les facteurs et la cause profonde. Contribution Explorer explore des millions de combinaisons de dimensions avec leurs valeurs, appelées « segments », afin de repérer les plus surprenantes. Vous pouvez, par exemple, recourir à cette fonction si vous remarquez qu’un client particulier dans une certaine région a subitement cessé d’utiliser votre produit.
En fait, vous pouvez même utiliser Contribution Explorer pour analyser régulièrement les indicateurs pour en révéler la valeur cachée, même lorsque les données ne contiennent aucune anomalie apparente à un niveau agrégé. Par exemple, les ventes peuvent sembler stables, alors qu’elles peuvent avoir dans le même temps chuté auprès d’un client et bondi auprès d’un autre.
En quoi les fonctions basées sur le ML de Snowflake sont-elles uniques?
Élasticité, opérations quasi nulles, gouvernance des données et bien plus encore
Les fonctions basées sur le ML de Snowflake s’adaptent facilement pour traiter de une à des millions de combinaisons de dimensions et de valeurs, grâce à l’élasticité du moteur de Snowflake, qui ne nécessite quasiment aucune opération. En outre, vous pouvez intégrer les recours aux fonctions Forecasting, Anomaly Detection et Contribution Explorer dans vos pipelines de données, tout comme n’importe quelle autre fonction SQL. Utilisez ces fonctions avec Snowflake Tasks et Alerts pour entraîner automatiquement de nouveaux modèles chaque semaine, à mesure que vous obtenez de nouvelles données, générez des prédictions chaque jour ou heure (en fonction de vos besoins) et recevez des alertes en cas de détection d’une anomalie nécessitant une enquête.
Quelle que soit la façon dont vous utilisez les fonctions basées sur le ML, vous bénéficiez de la gouvernance des données homogène de Snowflake sur l’ensemble des entrées et sorties de ces fonctions.
Étendue des capacités de ML
Les fonctions basées sur le ML complètent parfaitement les fonctions de ML Snowpark axées sur la data science. En effet, les premières prennent en charge l’entraînement des modèles, l’évaluation et bien plus encore avec un minimum d’efforts pour un analyste ou un décisionnaire déjà bien occupé, tandis que les secondes fournissent aux data scientists une boîte à outils riche et flexible pour leur permettre de concevoir leurs propres modèles.
Ensemble, elles offrent toute une gamme d’options selon la nature du problème et les efforts en matière de data science que vous êtes prêt à fournir pour le résoudre.
Extraction d’informations pour le machine learning à partir des outils de BI comme Sigma
Nous sommes fiers de travailler en partenariat avec Sigma, un outil de Business Intelligence qui prend en charge les fonctions basées sur le ML de Snowflake et fournit une interface conviviale pour permettre aux utilisateurs professionnels d’extraire des informations grâce au ML. Ainsi, cet outil assure une prise en charge front-end des fonctions Time Series Forecasting et Contribution Explorer de Snowflake.
En activant ces fonctions dans votre compte Snowflake et en accordant un accès au rôle de Sigma, vous pouvez exploiter les ensembles de données de Sigma, qui constituent un point de départ simplifié pour une analyse tabulaire et visuelle. Pour utiliser les fonctions Time Series Forecasting ou Contribution Explorer, identifiez le tableau ou l’ensemble de données voulu, groupez les données selon la granularité de votre choix, et créez des indicateurs agrégés à explorer. Préparez un tableau, créez une vue d’entrepôt, définissez un ensemble de données avec CustomSQL et appliquez la fonction correspondante en utilisant la syntaxe fournie.
Time Series Forecasting génère en ensemble de prédictions temporelles. Contribution Explorer fournit une liste triée des segments qui ont le plus contribué à la croissance d’un indicateur clé. Les deux ensembles de données peuvent être intégrés facilement à des classeurs de travail, afin d’en permettre la visualisation, l’exploration et le recoupement avec d’autres tableaux de votre entrepôt de données. Pour une plus grande interactivité, remplacez les variables statiques dans Custom SQL par des paramètres, afin de permettre aux utilisateurs de modifier des fonctions dans le classeur de travail.
Forecasting
Contribution Explorer
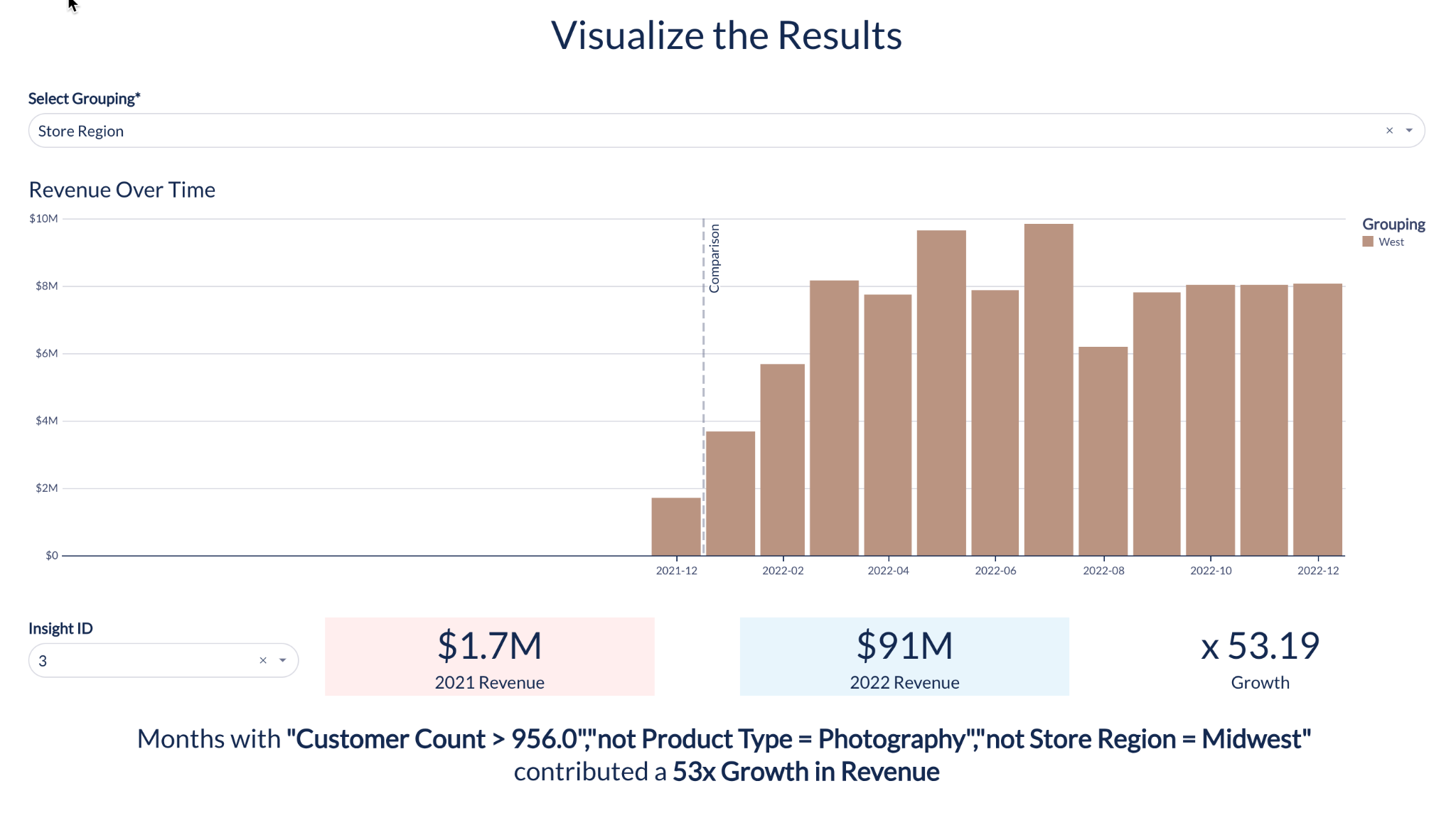
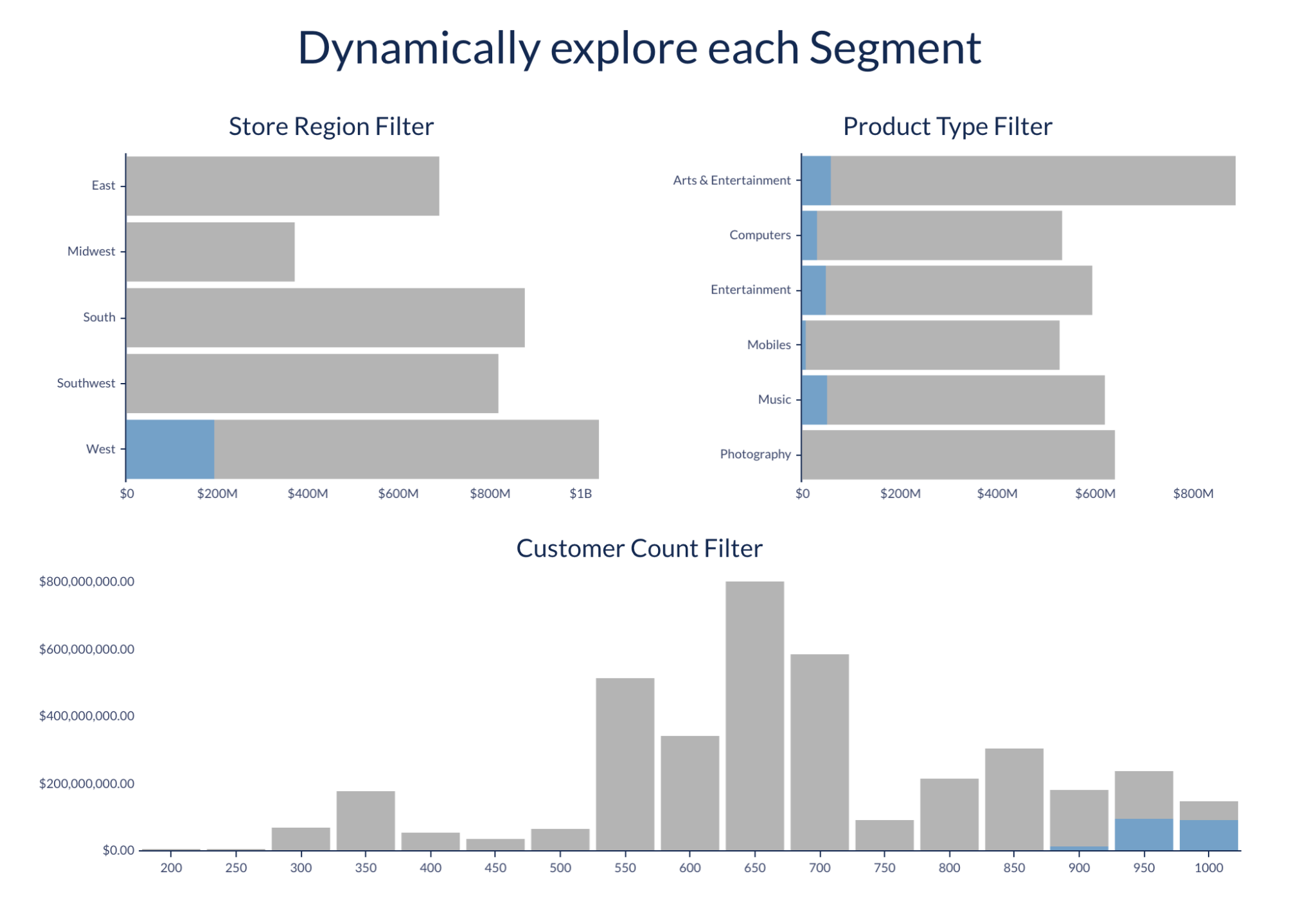
Cet ensemble de données peut être utilisé en toute simplicité dans n’importe quel classeur de travail, afin de faciliter sa visualisation, son exploration et son recoupement avec d’autres tableaux de votre entrepôt de données, pour favoriser une compréhension globale des indicateurs futurs attendus. Essayez par vous-même !
Et maintenant?
Les premiers retours de nos clients nous ont permis de travailler sur l’extension des fonctions mentionnées ci-dessus et de l’ensemble des capacités pour les renouveler et les rendre plus fascinantes encore. Les fonctions Anomaly Detection et Contribution Explorer partent de données sur les séries temporelles, mais ne devraient pas s’arrêter là. En effet, elles s’appliquent aussi à d’autres données pour détecter des anomalies parmi vos clients ou comparer des groupes d’utilisateurs, afin de repérer les segments les plus intéressants qui contribuent à leur différenciation. De fait, nous nous efforçons d’élargir les données couvertes par les fonctions basées sur le ML.
Au fur et à mesure que nous faisons progresser ces fonctionnalités, nous invitons certains de nos clients à les essayer pour obtenir leur avis. Restez à l’affût et contactez les équipes dédiées à votre compte pour accéder aux prochaines previews dès leur mise à disposition. Et n’hésitez pas à nous expliquer vos cas d’usage ici. Les possibilités futures du ML sont quasiment illimitées. Les fonctions qu’il alimente devraient accroître les capacités que vous pouvez exploiter pour améliorer vos résultats, sans avoir à suivre le rythme exponentiel de la recherche dans ce domaine.
Pour en savoir plus sur les fonctions basées sur le ML, consultez la documentation Snowflake.
Authors


