Apache Iceberg Avalanche : comment le format de table ouvert change le visage des data lakes

Le stockage de données évolue, des bases de données aux data warehouses puis aux data lakes étendus, chaque architecture répondant à des besoins commerciaux et de données différents. Les bases de données traditionnelles étaient idéales pour les données structurées et les workloads transactionnels, mais rencontraient des difficultés de performances à grande échelle à mesure que les volumes de données augmentaient. Le data warehouse répondait aux exigences de performances et d’évolutivité, mais, à l’instar des bases de données, s’appuyait sur des formats propriétaires pour créer des systèmes intégrés verticalement. Les systèmes de data lake sont passés à des formats plus ouverts, mais n’avaient pas les avantages fonctionnels offerts par les data warehouses, tels que les transactions ACID, la gouvernance complète et plus encore. En fin de compte, les utilisateurs se sont retrouvés coincés entre deux options : soit une plateforme entièrement intégrée avec seulement des solutions propriétaires disponibles, soit un data lake auto-créé, gourmand en ressources et neutre vis-à-vis des fournisseurs, en état de migration constante, dans l’espoir de finalement capter la valeur promise.
Désormais, vous n’avez plus à choisir. Avec l’avènement et l’adoption généralisée d’Apache Iceberg™, le data lakehouse ouvert a vu le jour, combinant le meilleur des data warehouses et des data lakes en découplant le stockage ouvert et le calcul pour offrir aux équipes data la flexibilité et le contrôle des architectures ouvertes ainsi que les performances élevées des data warehouses. C’est pourquoi Snowflake adopte pleinement ce format de table ouvert. Nos clients peuvent désormais bénéficier des avantages du stockage des données dans un format entièrement ouvert et interopérable tout en continuant à exploiter la puissance de la plateforme simple, connectée et fiable de Snowflake. Par conséquent, les entreprises peuvent accélérer leurs stratégies de data lakehouse ouvert et fournir des analyses avancées et l’IA plus rapidement.
Qu’est-ce qu’Iceberg ?
Au cœur de cette révolution de data lakehouse ouvert se trouve Iceberg, un format de table open source pour les gros workloads analytiques. Iceberg n’est pas un moteur de calcul ni même une base de données. Il décrit comment un ensemble de fichiers peut se comporter comme une table de base de données. La description étant ouverte et indépendante du moteur, une Iceberg Table est intrinsèquement neutre vis-à-vis des fournisseurs. Cette combinaison de fonctions et de neutralité vis-à-vis des fournisseurs ouvre la voie à la prochaine étape de l’évolution de l’architecture : le lakehouse ouvert, où le calcul, le format et le stockage sont tous dissociés les uns des autres.
Les Iceberg Tables deviennent interopérables tout en maintenant la conformité ACID en ajoutant une couche de métadonnées aux fichiers de données dans le stockage d’objets d’un utilisateur. Un catalogue externe effectue un suivi des dernières métadonnées de tables et contribue à assurer la cohérence entre plusieurs lecteurs et rédacteurs.
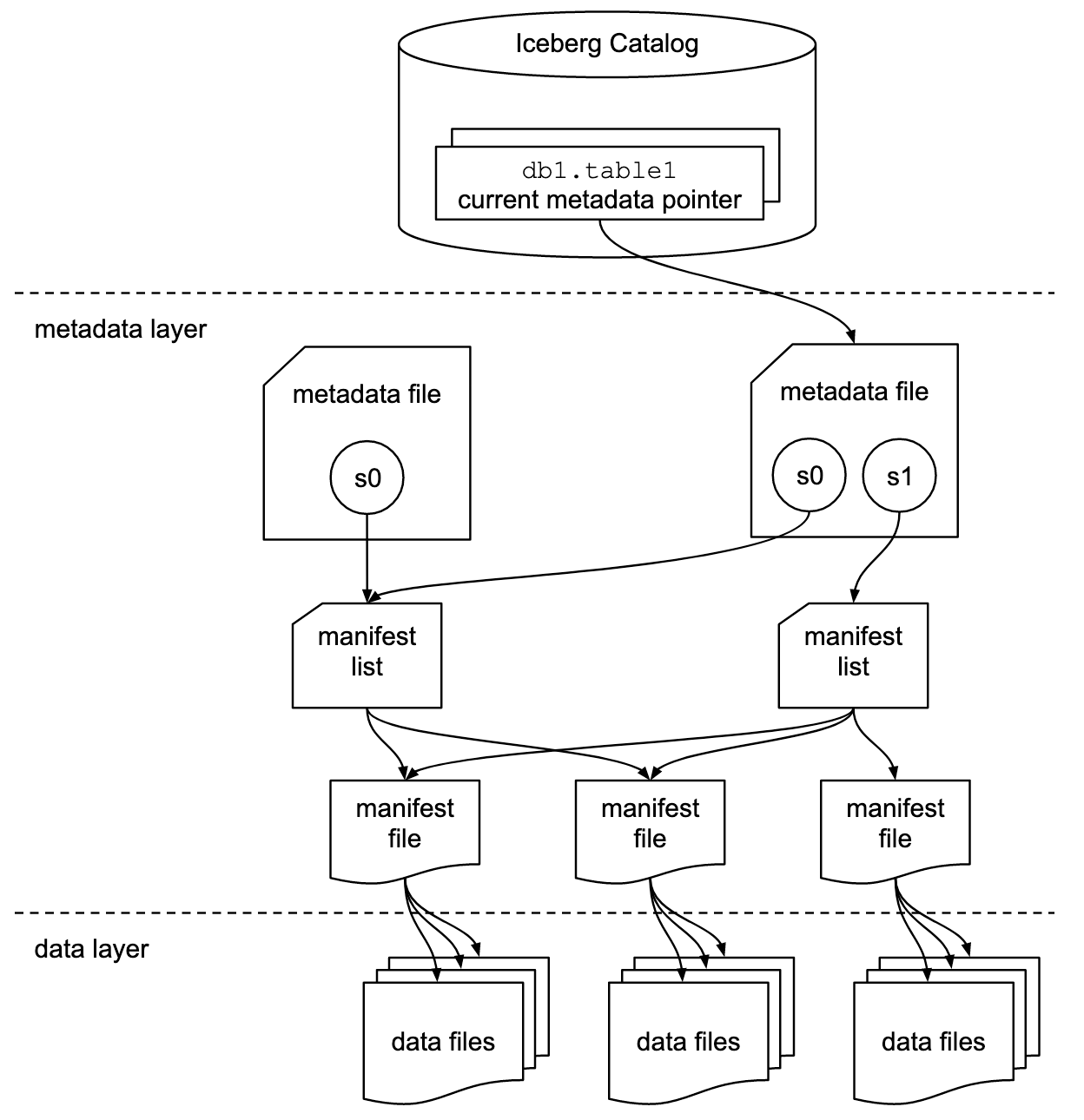
Pour faire simple : Iceberg, ce sont des métadonnées. Les fichiers de données sont suivis individuellement, plutôt qu’au niveau du répertoire, par des fichiers manifestes, des listes manifestes et des fichiers de métadonnées. Cette couche de métadonnées bien coordonnée permet à Iceberg de ne pas être victime de certains des problèmes les plus pernicieux que rencontrent les autres formats de table courants (e.g., Apache Hive™) en raison de leur dépendance stricte à une structure de répertoire physique.
Pourquoi devriez-vous vous soucier d’Iceberg ?
Sans avoir adopté les Iceberg Tables, les équipes data sont obligées de consacrer beaucoup de temps et de ressources à la gestion des migrations et de la gouvernance avant de pouvoir saisir les opportunités qu’offrent les nouvelles technologies et solutions. Iceberg élimine ce compromis. En offrant un format de stockage entièrement interopérable qui permet aux data engineers de posséder et de contrôler leur couche de stockage, Iceberg offre la flexibilité nécessaire pour tirer parti de n’importe quelle plateforme data ou n’importe quel moteur de calcul moderne compatible. Cela signifie que les équipes data peuvent passer de l’idée à l’impact en un temps record – sans compromis – et produire un impact à la vitesse que les entreprises demandent aujourd’hui.
Voici comment les équipes data peuvent bénéficier de l’ancrage de leurs architectures de lakehouse ouvertes sur les Iceberg Tables :
Plus grande productivité des développeurs : Iceberg permet aux développeurs et aux data engineers de travailler comme s’ils utilisaient une base de données relationnelle standard telle que Postgres, mais peut évoluer jusqu’à plusieurs pétaoctets de données.
Écrire unique, lecture partout : Iceberg est compatible avec tous les outils d’analyse les plus récents sans migration. Changez de moteur ou utilisez plusieurs moteurs en même temps sans pénalité.
Calcul plus rapide : la couche de métadonnées d’Iceberg est optimisée pour le stockage dans le cloud, ce qui permet d’effectuer un nettoyage anticipé des fichiers et des partitions avec des frais I/O minimes.
Parce qu’il s’agit d’un standard open source, que tous les outils ou moteurs peuvent prendre en charge et exploiter, Iceberg peut apporter ces incroyables gains à n’importe quelle organisation. En fin de compte, cette ouverture est gagnante pour vous.
Être plus ouvert d’esprit
Snowflake a toujours donné la priorité à ses utilisateurs. Alors que la technologie continue d’évoluer, Snowflake continue de donner la priorité à ses clients en soutenant les initiatives open source. Les avantages sont évidents : quand les utilisateurs ont le choix, ils gagnent. Cet engagement en faveur de l’open source est souligné par les contributions de Snowflake à Iceberg pour permettre une gestion efficace et gouvernée des data lakes avec une évolution schématique, un partitionnement et une gestion des transactions.
Alors qu’Iceberg précise comment les catalogues doivent se comporter, la communauté Iceberg s’est très intentionnellement gardée d’en fournir un. Étant donné que le catalogue gère les métadonnées de la table et contribue à assurer la cohérence entre plusieurs lecteurs et rédacteurs, cette absence de catalogue normalisé a créé le risque de réintroduire les compromis que l’Iceberg était censé résoudre. Plus précisément, cela forcerait à nouveau les entreprises à choisir entre deux options : soit mettre en œuvre, gérer et maintenir elles-mêmes un catalogue, soit tirer parti d’une solution de fournisseur avec le risque d’en rester dépendantes, à nouveau. Constatant cette lacune, Snowflake a redoublé d’engagement envers les normes ouvertes et le développement communautaire en créant puis en rendant open source un catalogue Iceberg et en l’introduisant à l’Apache Software Foundation, désormais connue sous le nom Apache Polaris (incubation), en juillet 2024.
Polaris est un catalogue Iceberg open source complet. De par sa conception, Polaris est neutre vis-à-vis des fournisseurs, et sa structure de gouvernance et son développement communautaire le garantissent. La mise en œuvre par Polaris de l’API REST d’Iceberg permet d’assurer la cohérence entre plusieurs lecteurs et rédacteurs et fournit un moyen de mettre à jour les tables d’un état à l’autre de manière atomique.
Polaris fournit également un moyen centralisé de sécuriser les données d’une entreprise. Créée à l’origine sous la forme d’un catalogue Iceberg interopérable, la feuille de route Polaris comprend désormais une prise en charge d’un plus grand nombre de formats de données et de types d’objets de données pour permettre aux utilisateurs de cataloguer toutes leurs données depuis un seul et même endroit.
Créer un data lakehouse ouvert
L’objectif de Snowflake est d’aider les entreprises à établir et à accélérer leurs ambitions de lakehouse ouvert afin qu’elles puissent obtenir plus d’impact avec moins de complexité.
Premiers pas :
Commencez à activer les données stockées dans un fournisseur de stockage dans le cloud, sans verrouillage, en créant des Iceberg Tables directement à partir de fichiers Parquet existants dans Snowflake.
Appliquez des contrôles de sécurité et de gouvernance complets dans la plateforme Snowflake via Horizon Catalog.
Gérez l’accès sécurisé multimoteur avec Open Catalog de Snowflake, un service entièrement géré pour Polaris qui préserve la possibilité d’autogestion en maintenant intacts les contrôles d’accès basés sur les rôles (RBAC), les espaces de noms et les définitions, quel que soit l’endroit où le catalogue est hébergé, ce qui élimine presque la complexité de la migration.
De plus, le moteur de données zéro opération élastique de Snowflake continue d’évoluer avec des capacités spécifiquement conçues pour améliorer les performances et l’efficacité des requêtes pour les Iceberg Tables. Nos clients bénéficient d’avantages tels que des techniques de nettoyage améliorées, qui réduisent les demandes de stockage dans le cloud et accélèrent l’exécution des requêtes, et Adaptive Scan, qui accélère l’exécution des requêtes lourdes à analyser. Ces capacités sont disponibles dès le départ, sans avoir à passer par une nouvelle mise en œuvre, ce qui permet d’améliorer les performances tout en réduisant les frais opérationnels.
Découvrez comment WHOOP réimagine son architecture de données avec Snowflake et Iceberg, économisant 20 heures de calcul chaque jour et améliorant l’accessibilité des données dans toute l’entreprise.
En savoir plus
Rejoignez Snowflake au Iceberg Summit, un événement de deux jours qui aura lieu à San Francisco les 8 et 9 avril. Nous sommes ravis d’appuyer la communauté en tant que commanditaire principal de l’événement inaugural.
Suivez notre webinaire Data Engineering Connect: Building Pipelines for Open Lakehouse le 29 avril, avec deux démos virtuelles et un atelier pratique.
Lisez The Essential Guide to Modernizing Data Lakes for AI with Snowflake, qui offre des conseils d’experts pour créer les bases permettant d’exploiter tout le potentiel des données et de l’IA.
Auteurs
