Snowpark ofrece funciones ampliadas que incluyen contenedores totalmente gestionados, API de ML nativas, nuevas versiones de Python, acceso externo, DevOps mejoradas y mucho más

Desde su lanzamiento hace dos años, Snowpark ha permitido a los científicos e ingenieros de datos, así como a los desarrolladores de aplicaciones, optimizar sus arquitecturas, acelerar el desarrollo y aumentar el rendimiento de los workloads Data Engineering e IA/ML en Snowflake. En el Summit de este año, nos complace anunciar la incorporación de una serie de mejoras en los tiempos de ejecución y las bibliotecas de Snowpark, que harán que la implementación y el procesamiento de código que no sea SQL en Snowflake sean más sencillos, rápidos y seguros.
Snowpark: un conjunto de bibliotecas y tiempos de ejecución para la implementación y el procesamiento seguros de código que no sea SQL en Snowflake Data Cloud
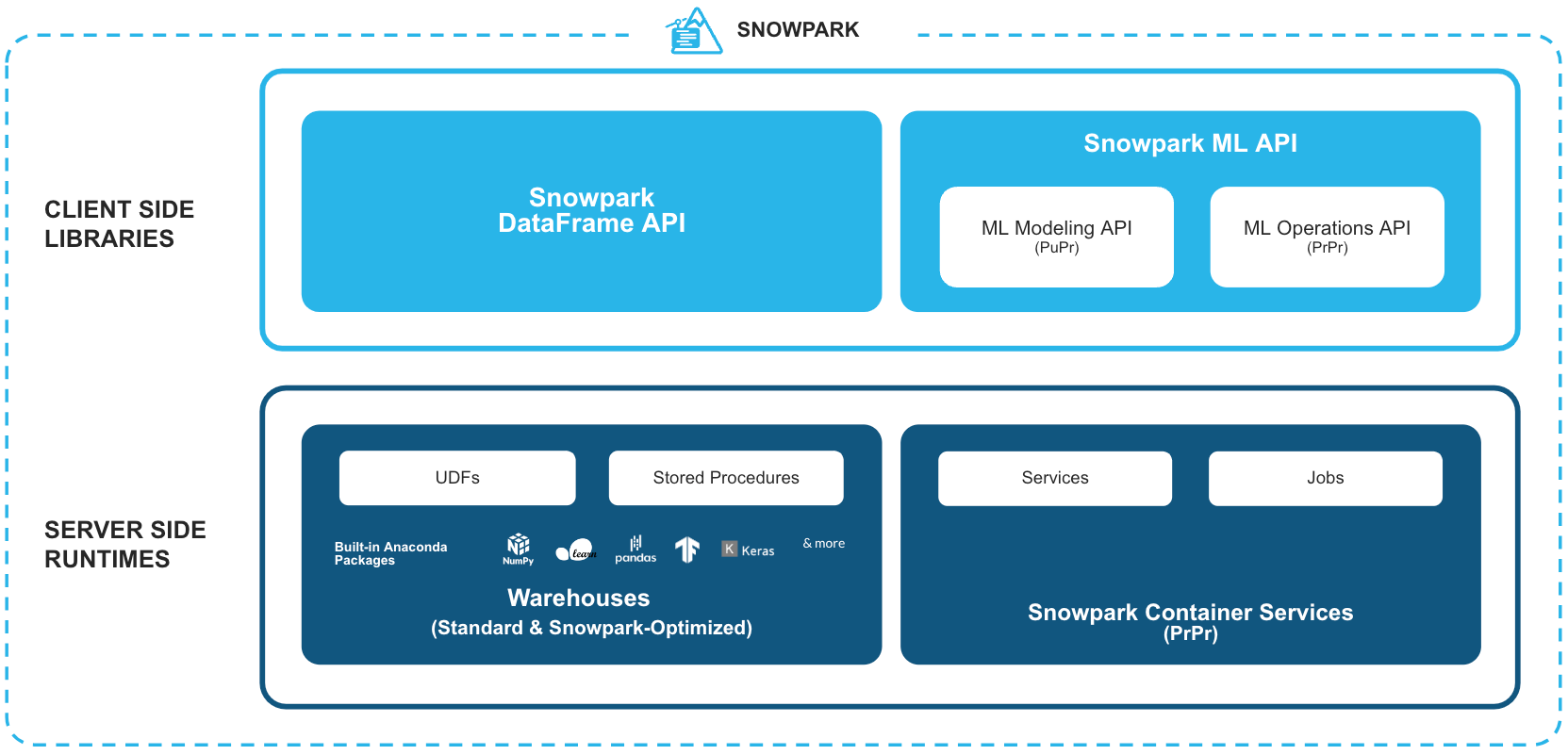
Bibliotecas conocidas del cliente: Snowpark ofrece una programación completamente integrada de estilo DataFrame e interfaces de programación de aplicaciones (application programming interface, API) compatibles con sistemas de soporte de operaciones (operational support system, OSS) para los lenguajes que los profesionales de los datos prefieran. Ofrece API conocidas para diferentes tareas centradas en los datos, como la preparación, la limpieza y el preprocesamiento de los datos, el entrenamiento de modelos y las tareas de implementación. Además, nos complace anunciar la compatibilidad con un nuevo conjunto de API de ML para obtener funciones de desarrollo (en vista previa pública) y de implementación (en vista previa privada) de modelos eficientes.
Estructuras de tiempo de ejecución flexibles: Snowpark proporciona estructuras de procesamiento y de tiempo de ejecución flexibles que permiten a los usuarios introducir y ejecutar la lógica personalizada en almacenes o en Snowpark Container Services (en vista previa privada). En el modelo de almacén, los usuarios pueden ejecutar sin problemas y hacer operativos los flujos de datos y los modelos de aprendizaje automático (machine learning, ML), así como las aplicaciones de datos con funciones definidas por el usuario (user-defined functions, UDF) y los procedimientos almacenados (stored procedures, sprocs). Snowpark Container Services ofrece la solución ideal para los workloads que requieren utilizar hardware especializado, como unidades de procesamiento de gráficos (graphics proccessing unit, GPU), bibliotecas y tiempos de ejecución personalizados, o bien proporcionar alojamiento a aplicaciones de pila completa de larga duración.
En conjunto, estas funciones proporcionan potentes enlaces de extensibilidad adaptados a los requisitos y las preferencias de los ingenieros y científicos de datos, así como de los desarrolladores. De esta forma, las organizaciones se liberan de la ardua tarea de poner en marcha y gestionar complejos sistemas independientes que operan fuera de los límites de gobernanza de Snowflake. Al acercar el procesamiento a los datos, las empresas pueden eliminar los silos de datos, abordar los retos de seguridad y gobernanza, y optimizar las operaciones, lo que se traduce en una mayor eficiencia, a la vez que se evita la sobrecarga de gestión asociada a sistemas e infraestructuras adicionales.
En este blog, profundizaremos en los anuncios más recientes sobre las bibliotecas del cliente de Snowpark y las mejoras del servidor en los almacenes. Para obtener más información sobre Snowpark Container Services, consulta nuestra publicación del blog sobre el lanzamiento aquí.
Novedades: Snowpark para Python
Python es cada vez más popular, hasta el punto de haberse convertido en el lenguaje favorito de los científicos de datos y el tercero más popular entre los desarrolladores. Nuestro objetivo es que Snowflake sea la mejor plataforma para los profesionales de Python. Por este motivo, hemos lanzado un conjunto integral de mejoras y uno ampliado de funciones de Snowpark para Python.
Actualizaciones generales de la plataforma
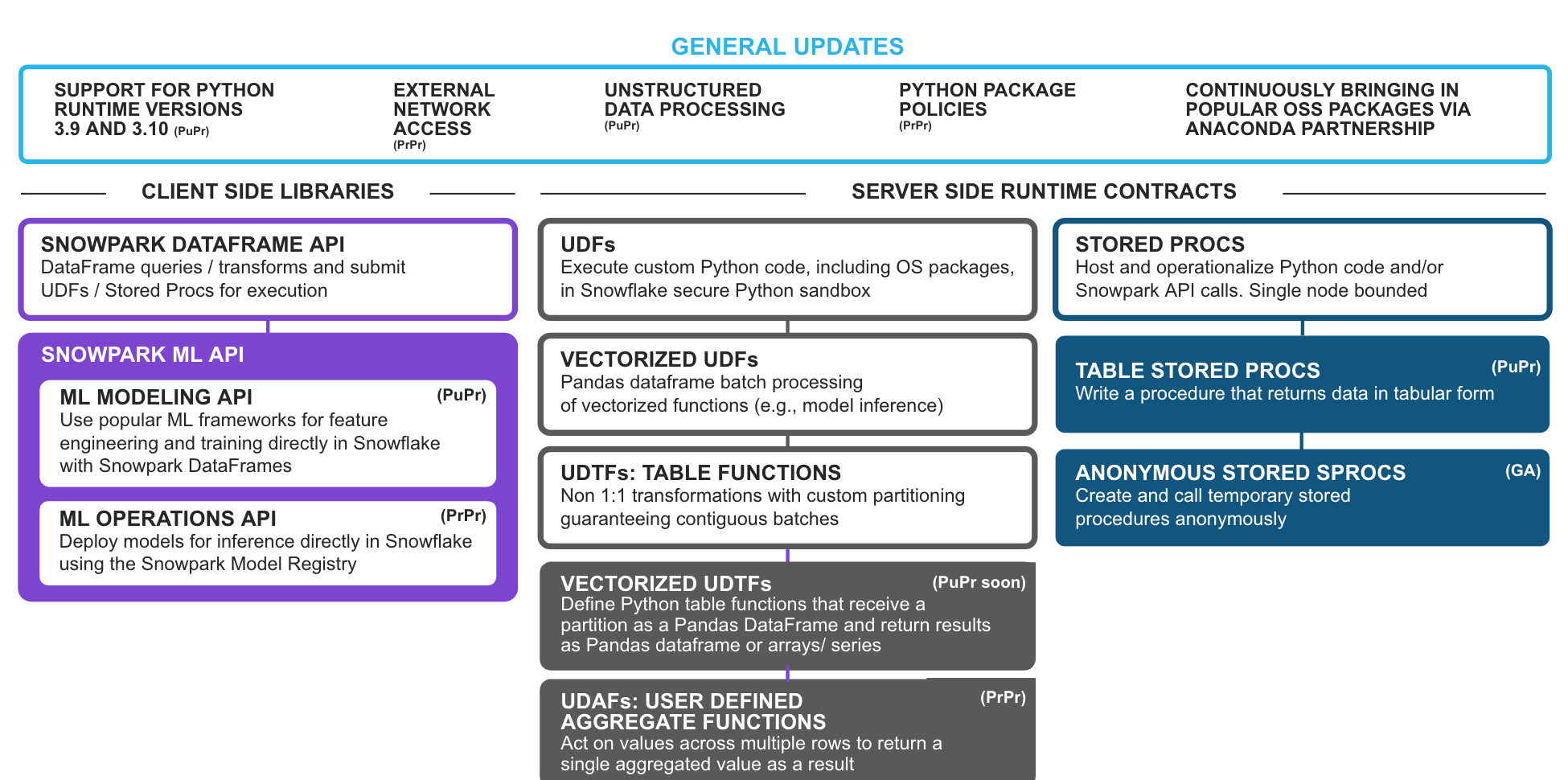
Compatibilidad con las versiones 3.9 y 3.10 de Python (en vista previa pública): los usuarios podrán actualizar a versiones más recientes para aprovechar las mejoras de Python y los paquetes de terceros compatibles en Snowpark.
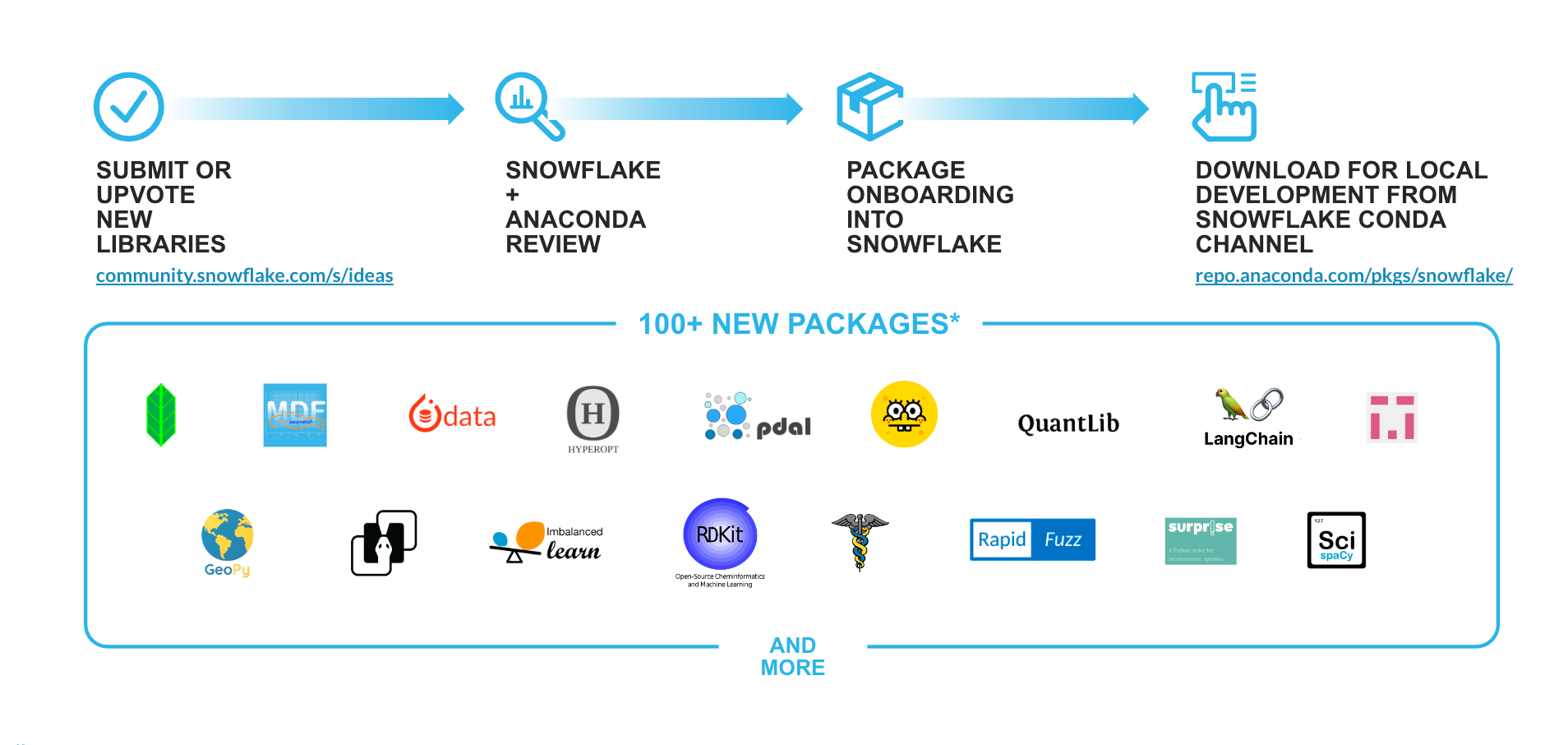
Compatibilidad con las nuevas bibliotecas de Python (Anaconda) en Snowflake: ya que la potencia de Python reside en su completo ecosistema de paquetes de código abierto, como parte de la oferta de Snowpark para Python, hemos incorporado innovaciones de código abierto fluidas y apropiadas para la empresa al Data Cloud mediante la integración con Anaconda. Gracias a los comentarios de los clientes y al tablón de ideas de Snowflake, seguimos añadiendo paquetes al repositorio actual, que ya cuenta con más de 5000 en el canal de Snowflake. Entre las adiciones recientes y las bibliotecas que se incorporarán próximamente se incluyen: langchain, implicit, imbalanced-learn, rapidfuzz, rdkit, mlforecast, statsforecast, scikit-optimize, scikit-surprise, etc.
Procesamiento de datos no estructurados de Python (en vista previa pública): el procesamiento de datos no estructurados ahora es compatible con Python de forma nativa. Los usuarios pueden aprovechar las UDF, las funciones de tabla definidas por el usuario (user-defined table function, UDTF) y los procedimientos almacenados de Python para leer, procesar y obtener información de forma segura y dinámica de archivos no estructurados (como imágenes, vídeos, audios o formatos personalizados), procedente de fases internas/externas o de almacenamiento on-premise.
Acceso de red externa (en vista previa privada): permite a los usuarios conectarse sin problemas a puntos de conexión externos desde su código de Snowpark (UDF/UDTF y procedimientos almacenados) a la vez que garantizan una alta gobernanza y seguridad.
Políticas de los paquetes de Python (en vista previa privada): permite a los usuarios con los privilegios adecuados establecer listas de permitidos y bloqueados para mejorar la gobernanza de los paquetes de Anaconda utilizados en su cuenta. Esta función permite a los clientes que requieren una auditoría y/o seguridad más estrictas tener un control y una gobernanza más precisos sobre el uso de paquetes de Python y OSS en sus entornos de Snowflake.
Actualizaciones de las bibliotecas del cliente
Presentación de Snowpark ML API: nos complace anunciar la compatibilidad con las Snowpark ML API, formadas por API ML Modeling (en vista previa pública) y API ML Operations (en vista previa privada), que facilitarán el desarrollo integral del ML en Snowflake.
Snowpark ML Modeling API (en vista previa pública): escala horizontalmente la ingeniería de funciones y simplifica el entrenamiento de modelos en Snowflake.
- Preprocesamiento: realiza tareas habituales de preprocesamiento e ingeniería de funciones directamente en los datos de Snowflake utilizando las ya conocidas API estilo sklearn y benefíciate de un rendimiento mejorado y de la paralelización de Snowflake para escalar grandes conjuntos de datos con ejecución distribuida y multinodo.
- Modelado: entrena modelos para los modelos populares de scikit-learn y XGBoost directamente sobre los datos de Snowflake. Proporciona API conocidas para llevar a cabo el entrenamiento de forma directa sin necesidad de crear procedimientos almacenados ni UDF manualmente.
Snowpark ML Operations API (en vista previa privada): incluye Snowpark Model Registry (en vista previa privada) con el fin de implementar fácilmente los modelos registrados para la inferencia con una infraestructura de Snowflake escalable y fiable.
Actualizaciones del contrato de tiempo de ejecución de almacén
Funciones de agregado definidas por el usuario (user defined aggregate functions, UDAF) (en vista previa privada): permiten a los usuarios crear funciones que pueden actuar sobre valores de varias filas y devolver un solo valor agregado como resultado, lo que posibilita escenarios de agregado personalizados, fáciles de usar y fluidos en Snowpark.
UDTF vectorizadas (próximamente en vista previa pública): permiten a los usuarios crear funciones de tabla que operan en particiones como pandas DataFrame y devuelve los resultados como pandas DataFrame o listas de pandas Series/arrays. En comparación con el procesamiento fila por fila de las UDTF escalares, las UDTF vectorizadas permiten un procesamiento fluido partición por partición. Dado que es más rápido concatenar DataFrames que recoger los datos fila por fila con la función de procesamiento, se mejorará el rendimiento de varios casos de uso, como el entrenamiento distribuido de modelos múltiples e independientes (por ejemplo, el ajuste de hiperparámetros), el análisis y la previsión de series temporales distribuidas, la inferencia de modelos con varias salidas, etc.
Procedimientos almacenados anónimos (de disponibilidad general [general availability, GA]): crean y llaman a un procedimiento anónimo similar a un procedimiento almacenado pero que no se guarda para su uso posterior. Es ideal para desarrollar aplicaciones e integraciones de Snowpark que requieran ejecutar códigos de Snowpark que no haya que conservar. Por ejemplo, los modelos de dbt Python y las hojas de trabajo de Snowflake para Python aprovechan los sprocs anónimos en segundo plano.
Procedimientos almacenados en tablas de Python (en vista previa pública): los procedimientos almacenados previamente solo devolvían valores escalares. Ahora, pueden devolver resultados en tablas, lo que permitirá a los usuarios devolver convenientemente una tabla para que se procese posteriormente como parte de su código de Snowpark.
Novedades: DevOps en Snowflake
Además de las anteriores mejoras de Snowpark, en el Summit anunciamos una serie de avances relacionados con DevOps de Snowflake, que facilitarán el trabajo, la gestión, las pruebas y la puesta en funcionamiento del código de Snowpark. Algunas de las mejoras más destacadas son las siguientes:
Registro y seguimiento con tablas de eventos (en vista previa pública): los usuarios pueden realizar registros y seguimientos desde las UDF, las UDTF, los procedimientos almacenados y los contenedores de Snowpark, y enviarlos sin problemas a una tabla de eventos del cliente segura. Los usuarios pueden consultar y analizar la telemetría del evento, así como registrar y hacer un seguimiento en las tablas de eventos para solucionar problemas de sus aplicaciones u obtener información sobre el rendimiento y el comportamiento del código. Junto con otras funciones de telemetría, como las alertas y notificaciones por correo electrónico de Snowflake, los clientes pueden recibir informes sobre los nuevos eventos y errores en las aplicaciones.
API Python Tasks (próximamente en vista previa privada): proporciona API de Python de primera clase para crear y gestionar tareas y grafos acíclicos dirigidos (directed acyclic graphs, DAG) de Snowflake.
Pruebas locales de Snowpark (en vista previa privada): permite a los usuarios crear una sesión de Snowpark y DataFrames sin tener una conexión en tiempo real con Snowflake. Los usuarios pueden acelerar sus conjuntos de pruebas de Snowpark y ahorrar créditos mediante una sesión local y cambiar sin problemas a una conexión en tiempo real sin modificar el código.
Integración nativa con Git (próximamente en vista previa privada): Snowflake ahora admite la integración nativa de los repositorios de Git. Esta integración permite a los usuarios conectarse de forma segura a un repositorio de Git desde una cuenta de Snowflake y acceder a los contenidos desde cualquier rama, etiqueta o destino dentro de Snowflake. Tras la integración, los usuarios pueden crear UDF, procedimientos almacenados, aplicaciones de Streamlit y otros objetos solo con hacer referencia al repositorio y a la rama, tal como lo harían con un archivo en una fase.
Interfaz de línea de comandos (command-line interface, CLI) de Snowflake (en vista previa privada): una interfaz de línea de comandos de código abierto que permite a los desarrolladores crear, gestionar, actualizar y visualizar aplicaciones sin esfuerzo, junto con funciones de automatización de creación y de integración y desarrollo continuos (continuous integration/continuous development, CI/CD) en workloads centrados en aplicaciones.
Tareas activadas (en vista previa privada): este nuevo tipo de tarea permite a los usuarios consumir datos en un flujo de Snowflake de forma más eficiente. Antes, las tareas podían ejecutarse en un minuto. Con las tareas activadas, los datos pueden utilizarse a medida que llegan, lo que reduce significativamente la latencia, optimiza la utilización de los recursos y disminuye los costes.
Estas nuevas actualizaciones de Snowpark y DevOps optimizan el proceso de codificación para todos los desarrolladores de Python, permitiéndoles así trabajar de la forma habitual, a la vez que disfrutan de las ventajas de la gobernanza y el rendimiento de Snowflake. Gracias a estas mejoras, los ingenieros de datos podrán migrar sin problemas desde Spark para realizar procesos de extracción, transformación y carga (extract, transform, load; ETL) y de extracción, carga y transformación (extract, load, transform; ELT), los científicos de datos podrán desarrollar e implementar modelos de ML de forma nativa y los desarrolladores de datos podrán diseñar aplicaciones con Snowpark.
Snowpark en profundidad
Echa un vistazo a estos blogs y vídeos tan detallados del equipo de ingeniería de Snowpark sobre cómo se desarrolló Snowpark, cómo funciona y cómo logra que sea fácil y seguro procesar código Python, Java y Scala en Snowflake.
Historias de éxito de clientes
Desde que se anunció su GA en el Snowday de noviembre de 2022, Snowpark para Python ha experimentado un fuerte crecimiento, con una adopción tres veces mayor por parte de los clientes. Miles de clientes están acelerando el desarrollo y el rendimiento de sus workloads con Snowpark para Python en casos de uso de ML y de Data Engineering.

OpenStore es una empresa de comercio electrónico que pasó de PySpark a Snowpark para realizar grandes transformaciones de datos, logrando así una reducción del 87 % en el tiempo de ejecución integral, una mejora del 25 % en el rendimiento y una disminución del 80 % en las horas de mantenimiento técnico.

Intercontinental Exchange, la empresa principal de NYSE, utiliza Snowpark para optimizar los flujos de datos y ahorrar costes en las aplicaciones esenciales utilizadas para la elaboración de informes normativos.

EDF Energy es un proveedor de energía líder en Reino Unido que utiliza Snowpark para desarrollar un motor inteligente de clientes. “Poder ejecutar tareas de ciencia de datos, como la ingeniería de funciones, directamente donde se encuentran los datos es increíble. Ahora, nuestro trabajo es mucho más eficiente y divertido”, asegura Rebecca Vickery, Data Science Lead de EDF.

Snowpark ofrece a Bridg una forma de acceder directamente a los datos, entrenar modelos y ejecutar acciones en un único clúster de Snowflake, lo que hace que el proceso se realice de forma totalmente interna, automatizada y eficiente. “Juntos, Snowflake y Snowpark nos han permitido desarrollar y automatizar modelos de ML propios mucho más rápido”, ha afirmado Dylan Sager, Lead Data Scientist de Bridg.
Programa Snowpark Accelerated
También estamos encantados con el gran interés que ha despertado nuestro ecosistema de partners, incluidas las nuevas colaboraciones como la de KX. Como parte del programa Snowpark Accelerated, contamos con varios partners que desarrollan integraciones con Snowpark para Python para mejorar la experiencia que ofrecen a sus clientes junto con Snowflake.

Trabaja de forma más rápida e inteligente con Snowpark
El principal objetivo de Snowpark es ayudar a los usuarios a llevar a cabo iniciativas con un gran impacto a partir de los datos, a la vez que se mantienen la simplicidad, la escalabilidad y la seguridad de la plataforma de Snowflake. Estamos deseando ver tus creaciones con Snowpark para Python.
Para ayudarte a empezar, echa un vistazo a los siguientes recursos:
Authors
