
In the ever-evolving world of data analytics, efficiency and expressiveness are crucial. At Snowflake, we continue to extend the SQL capabilities to meet the demands of modern data professionals. Today, we’re excited to share the general availability of the REDUCE function in Snowflake — a powerful addition to our robust array processing functions — to make working with arrays more intuitive and efficient.
Let’s step back: What are higher-order functions ?
A higher-order function is one that accepts another function (lambda expression) as input, making it particularly useful for processing semistructured data. For example, when there’s a need to iterate over an array and perform specific actions on each element, higher-order functions offer a straightforward and efficient solution. Snowflake already supports two higher-order functions, namely FILTER and TRANSFORM, which help to filter and transform arrays, respectively, based on the logic in the lambda expression. Since the GA of those functions in May 2024, we have seen more than 13.5 million queries use these features. To learn more about these functions, refer to our FILTER and TRANSFORM documentation. Now onto the new REDUCE higher-order function.
What is the REDUCE higher-order function?
The REDUCE function is a higher-order SQL function that processes elements in an array and reduces them to a single value using a lambda expression. This function empowers users to perform sophisticated aggregations and express complex operations on arrays in a concise manner.
The REDUCE function in Snowflake has the following syntax:
REDUCE( <array> , <init> , <lambda_expression> )<array>: The array to be reduced.<init>: The initial state / accumulator value.<lambda_expression>: A lambda expression that defines theREDUCElogic on each array element.
Why is this a game-changer?
Before the introduction of the REDUCE function, certain data transformations in SQL were either cumbersome or inefficient. Complex aggregations or manipulations on array elements often required using user-defined functions (UDFs) or FLATTEN operations, often leading to decreased performance and increased complexity. The REDUCE function changes this by allowing you to perform array transformations easily. With the new REDUCE function, you can:
- Simplify complex logic: Replace intricate query constructs with concise expressions that are easier to understand and maintain. In addition, utilize lambda expressions for modular and expressive code.
- Perform advanced analytics: Go beyond simple analytics using the higher-order functions that allow you to iterate over array elements and implement custom logic for data transformation and analytics.
- Boosts performance: Write code that is more performant than typical workarounds like using
LATERAL FLATTENor UDFs.
Example: Merging key-value pairs in an array column
Let’s explore the REDUCE function through a practical scenario. Imagine you’re responsible for managing configuration settings for multiple applications or environments. Each application’s configuration is stored in a table named configurations, with each row representing the settings of a specific application.In this table, the configurations are stored as arrays of key-value pair objects. Here, each key represents the name of a configuration setting (e.g., hostname), and the corresponding value holds the actual value for that setting (e.g., server1.example.com) as shown below. This structured approach allows flexibility to ingest varying keys and metadata across different applications.
[{ "key": "hostname","value": "server1.example.com"},... ]he task at hand is to convert these arrays of key-value pairs into a JSON object. In the resulting JSON, the values will be accessible directly by their key names, such as:
[{"hostname": "server1.example.com"},... ]First, let’s create some sample data
CREATE OR replace TABLE configurations AS
SELECT 1 AS config_id,
[ {'key':'hostname', 'value':'server1.example.com'},
{'key':'port', 'value':443},
{'key':'use_ssl', 'value':true}
] AS config_data
UNION
SELECT 2 AS config_id,
[
{'key':'hostname', 'value':'server2.example.com'},
{'key':'port', 'value':80},
{'key':'use_ssl', 'value':false}
] AS config_dataThis is how the sample data looks:
| CONFIG_ID | CONFIG_DATA |
| 1 | [ { „key“: „hostname“, „value“: „server1.example.com“ }, { „key“: „port“, „value“: 443 }, { „key“: „use_ssl“, „value“: true } ] |
| 2 | [ { „key“: „hostname“, „value“: „server2.example.com“ }, { „key“: „port“, „value“: 80 }, { „key“: „use_ssl“, „value“: false } ] |
Using REDUCE to merge key-value pairs
Now, we’ll use the REDUCE function to merge the key-value pairs from the config_data array into a single JSON object for each configuration.
SELECT config_id,
REDUCE(config_data,OBJECT_CONSTRUCT(),(acc, item) ->
OBJECT_INSERT(acc, item['key'], item['value'])) AS merged_config
FROM configurations;| CONFIG_ID | MERGED_CONFIG |
| 1 | { „hostname“: „server1.example.com“, „port“: 443, „use_ssl“: true } |
| 2 | { „hostname“: „server2.example.com“, „port“: 80, „use_ssl“: false } |
Workaround using LATERAL FLATTEN
Before the REDUCE function, merging the array of key-value pairs into a single object required more complex queries involving table flattening and manual aggregation.
SELECT
config_id,
OBJECT_AGG(item:key, item:value) AS merged_config
FROM configurations,
LATERAL FLATTEN(input => config_data) AS flattened,
LATERAL (SELECT flattened.value AS item)
GROUP BY config_id;Workaround using UDFs
CREATE OR REPLACE FUNCTION reduce_array_into_object(items ARRAY)
RETURNS variant
LANGUAGE JAVASCRIPT
AS
$$
return ITEMS.reduce((acc, item) =>
{
acc[item.key] = item.value;
return acc;
},
{})
$$;
select config_id, reduce_array_into_object(config_data) merged_config
from configurations;Using the REDUCE function transforms the process into a more elegant solution. It offers simplicity by expressing the entire transformation in a single, concise expression. This streamlined approach enhances both readability and maintainability — the logic is clear, easy to follow and straightforward to update, ensuring the code remains accessible for future improvements.
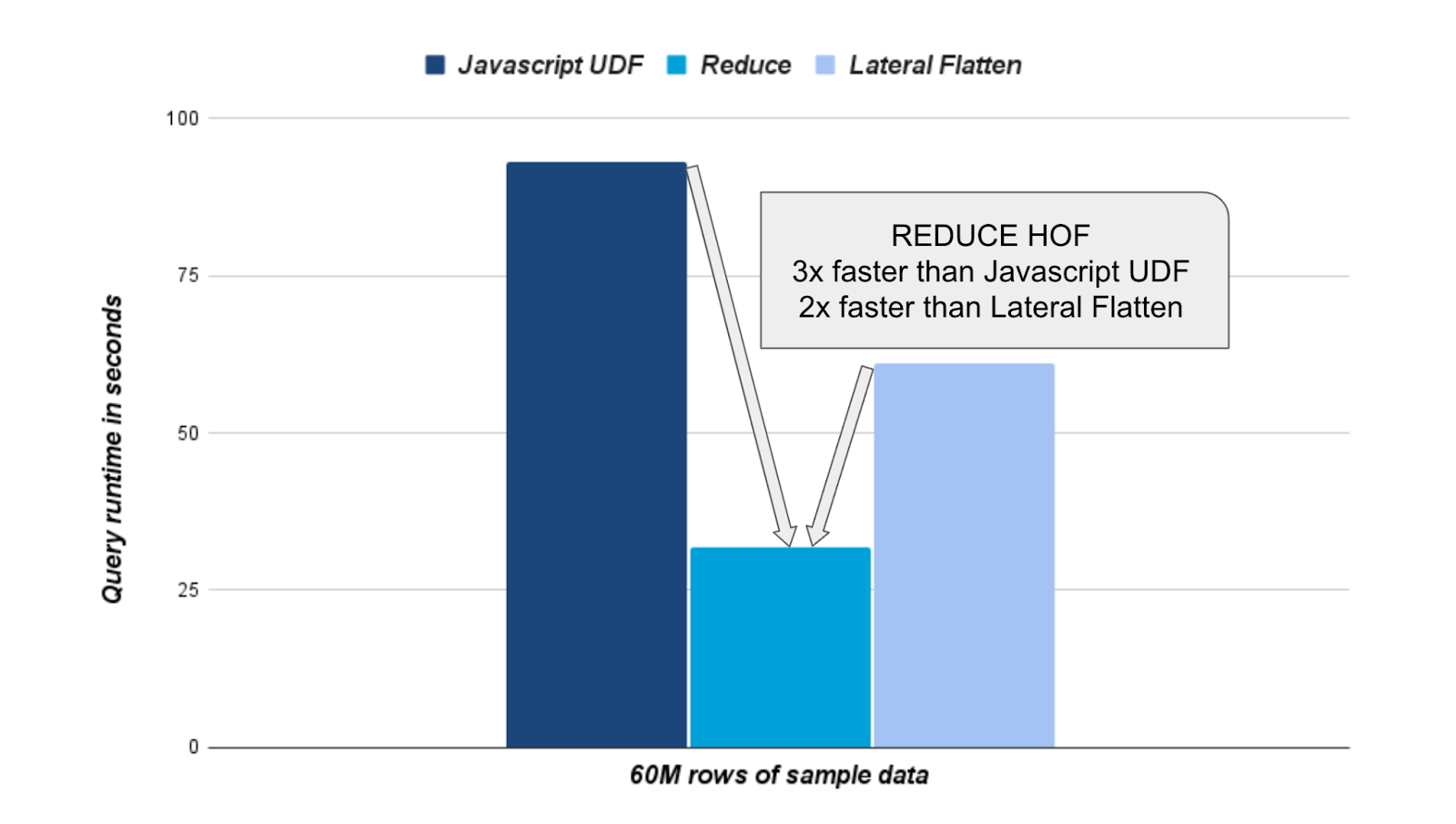
In addition, there could be performance benefits you might observe when using REDUCE, as compared to typical workarounds like using LATERAL FLATTEN or UDFs. In our performance tests on the aforementioned example, REDUCE was approximately twice as fast as LATERAL FLATTEN and three times faster than the JavaScript UDF. While results may vary depending on table size and the complexity of the lambda expression, the numbers and the graph below highlight the potential performance gains that REDUCE can provide.
Conclusion
The introduction of the REDUCE function in Snowflake marks a significant advancement in simplifying complex data transformations, and you can now perform computations that were previously difficult or inefficient easily.
Whether you’re merging key-value pairs from an array column, reconstructing complex data structures, performing custom aggregations or simplifying data processing tasks, the REDUCE function opens up new possibilities for working with arrays in Snowflake.We encourage you to explore the REDUCE function and experience firsthand how it can streamline your data workflows. Please refer to our documentation to learn more.


