Automatic Performance: Query Acceleration Through Smarter Join Decisions

In this blog, we’ll discuss Adaptive Join Decisions, a new Snowflake performance feature that uses runtime query information to make smarter join decisions, accelerating performance for applicable queries by 9.5%*. This feature is on by default, and customers benefit from it automatically.
Efficient joins on large data sets
In modern data analytics, handling large data sets efficiently is crucial. Imagine a scenario where you need to analyze sales data in Snowflake, which includes a large sales fact table and several smaller dimension tables like product, customer and date.
The tables could be defined as follows:
CREATE TABLE product (
product_id INT PRIMARY KEY,
product_name STRING,
category STRING
);
CREATE TABLE customer (
customer_id INT PRIMARY KEY,
customer_name STRING,
region STRING
);
CREATE TABLE date (
date_id INT PRIMARY KEY,
date DATE,
month STRING,
year INT
);
CREATE TABLE sales (
sale_id INT PRIMARY KEY,
product_id INT,
customer_id INT,
date_id INT,
amount DECIMAL(10, 2),
FOREIGN KEY (product_id) REFERENCES product(product_id),
FOREIGN KEY (customer_id) REFERENCES customer(customer_id),
FOREIGN KEY (date_id) REFERENCES date(date_id)
);Generating a sales dashboard would require you to join the sales table with each of the dimension tables. For example, you might write a query like this:
SELECT
s.sale_id,
p.product_name,
c.customer_name,
d.date,
s.amount
FROM
sales s
JOIN
product p ON s.product_id = p.product_id
JOIN
customer c ON s.customer_id = c.customer_id
JOIN
date d ON s.date_id = d.date_id;Efficiently joining these tables and selecting optimal join strategies are crucial for query performance. The performance of individual joins significantly depends on the chosen join distribution strategy — in this case, hash-partitioned hash joins vs. broadcast joins.
With Adaptive Join Decisions, Snowflake uses feedback from runtime query execution, and intelligently selects between hash-partitioning and broadcast joins based on the specific characteristics of your data and queries to improve the performance of queries.
Broadcast joins vs. hash-partitioning hash joins
Broadcast joins are highly efficient when the build side fits into memory. In this case, the build side is replicated and sent to all worker nodes over the network. Each worker node then performs the join locally with its partition of the larger data set.
Taking our example, here is a conceptual visualization of how a join between the sales and the product table on four participating nodes could look like:
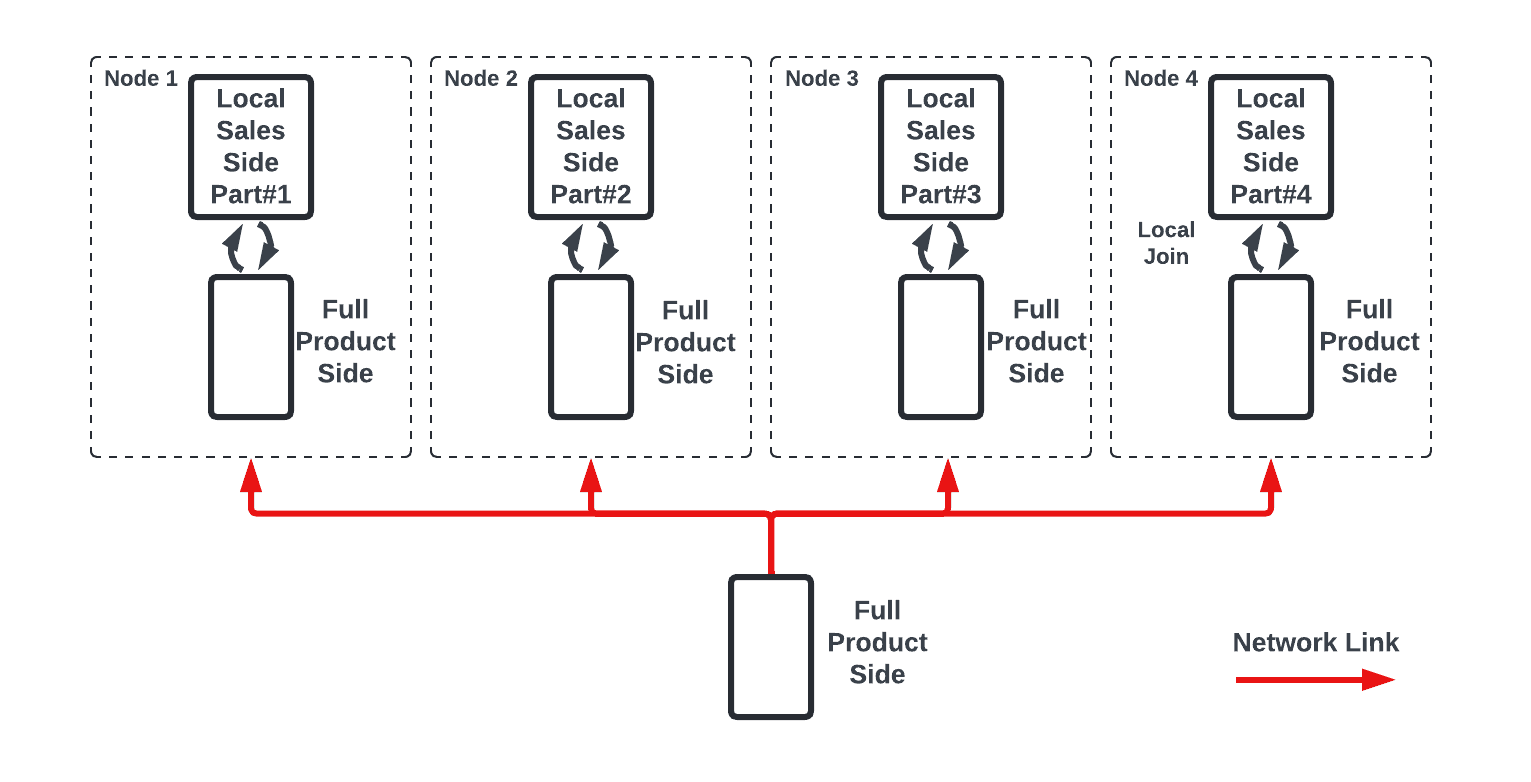
By contrast, hash-partitioning hash joins are designed for large data sets. Both the build and probe sides are partitioned using the same hash function, and only corresponding partitions are exchanged and joined at each worker node. This method distributes the data more evenly across nodes, allowing parallel processing and reducing memory overhead.
Here’s how the same join would look as a hash-partitioning hash join:
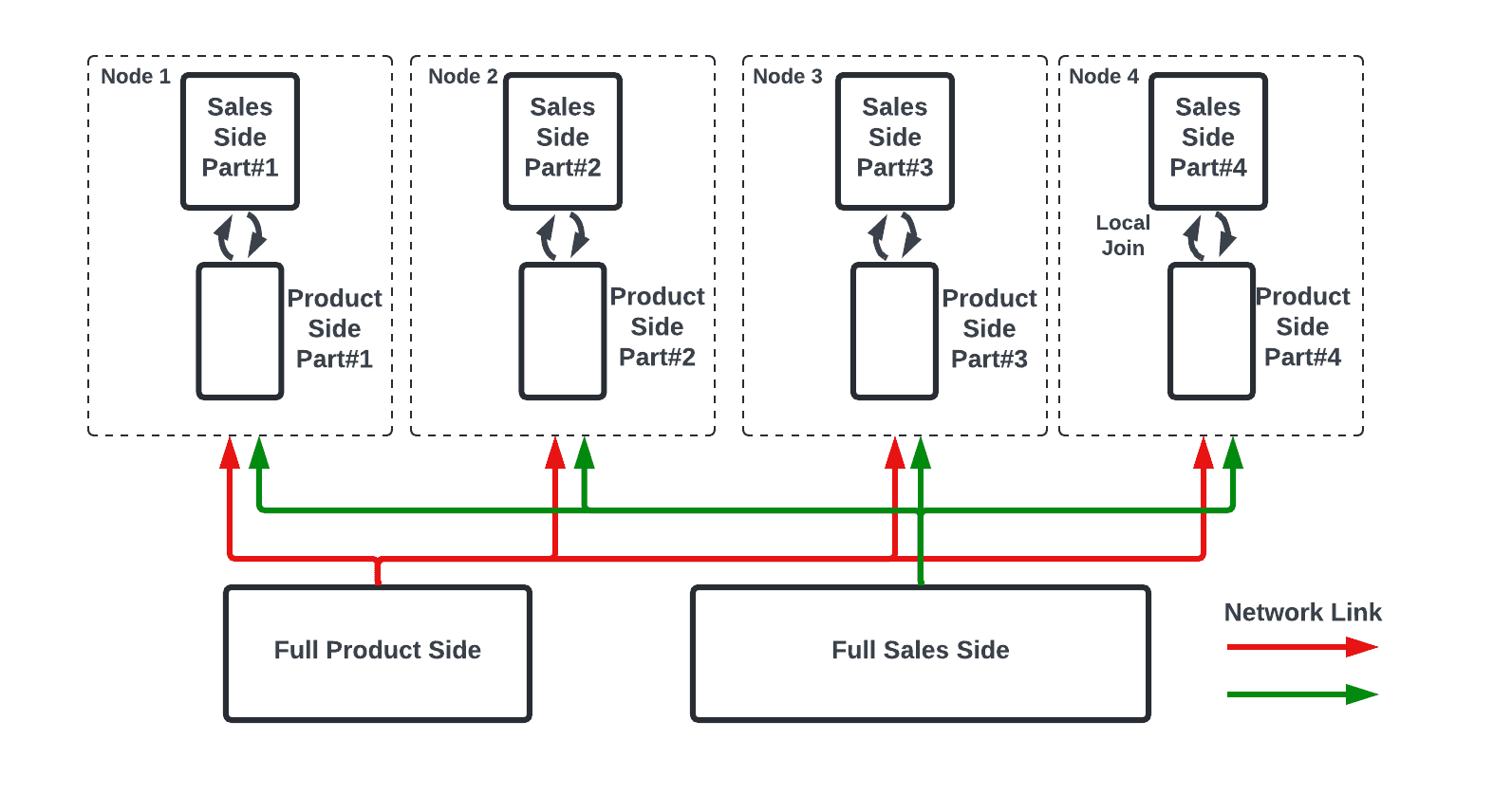
The main advantage of broadcast joins is that they eliminate the need for expensive shuffling of large data sets, making them ideal for small build sides. However, when the build side is large, broadcasting becomes inefficient as it leads to high network overhead and memory constraints, since each worker node must receive and store a full copy of the build side.
On the other hand, while hash-partitioning hash joins are well-suited for large build sides, they introduce unnecessary complexity and overhead for small build sides, where partitioning and shuffling may be redundant. Thus, hash-hash joins excel in handling large data sets but are less optimal for small ones.
The following graphic visualizes these differences, depending on the size of the build-side table (in our example, the product table), showcasing the network overhead when the build side is large and we do a broadcast join.
BROADCAST - Small Build Side | BROADCAST - Large Build Side  |
HASH-PARTITIONING HASH - Small Build Side  | HASH-PARTITIONING HASH - Large Build Side  |
While most other systems determine join strategies during compilation, Snowflake takes a different approach by making adaptive join decisions at runtime. This allows for much more accurate size estimates of hash tables, especially when metadata for join inputs is lacking, resulting in enhanced performance.
One of the improvements, our probe-side annotated join decision-making, combines these runtime-calculated, build-side size estimates with probe-side compile time annotations. As a result, we can avoid expensive broadcast joins (i.e., wide build sides but relatively narrow probe sides).
Performance impact
The probe-side annotated join decisions apply to a wide range of queries, affecting ~5 million per day with the median improvement of 9.5%*. To illustrate the impact of this performance, let’s look at Q40 from the industry-standardized TPC-DS benchmark.
SELECT
s.sale_id,
p.product_name,
c.customer_name,
d.date,
s.amount
FROM
sales s
JOIN
product p ON s.product_id = p.product_id
JOIN
customer c ON s.customer_id = c.customer_id
JOIN
date d ON s.date_id = d.date_id;Before | After |
Now, let’s take a look at the query plan:
Before (4 s) | After (831 ms) |
In Fig. 5, we observe a shift in the time spent on different parts of the query. Instead of having the single Join[3] take up 86.9% of the entire execution time, it now only takes 24.0%. This is achieved by choosing a hash-partitioning hash join, which dramatically reduces the network load of this query from nearly 39 GB to just about 3 GB — a more than 10x improvement!
Making the decision to choose a hash-partitioning hash join in this case helps for several reasons: First, even though the optimizer's decision on join order is appropriate, the build side ends up having ~7x as many rows as the probe side. The significant reduction of the probe side is due to the joins corresponding to JoinFilter[16], which significantly reduces the initially larger probe side from 241M rows down to around 2.5 M. In addition, the probe side is rather narrow (consisting only of integral types), while the build side also has larger text columns, making it expensive to send over the network. The result: a more than 3x improvement in query duration for this query!
Right-deep join trees
Another area where we made significant improvements involves query plans with deeply nested right-deep join trees. In Snowflake connotation, right-deep joins involve dimension tables that form the build sides of a long join pipeline, all relating to a common fact table (the sales table, from our example). This structure is common in BI queries, where large fact tables are joined with multiple dimension tables, and is generally the preferred execution strategy for handling complex queries with multiple joins.
For our introductory example, the query plan would look as follows:
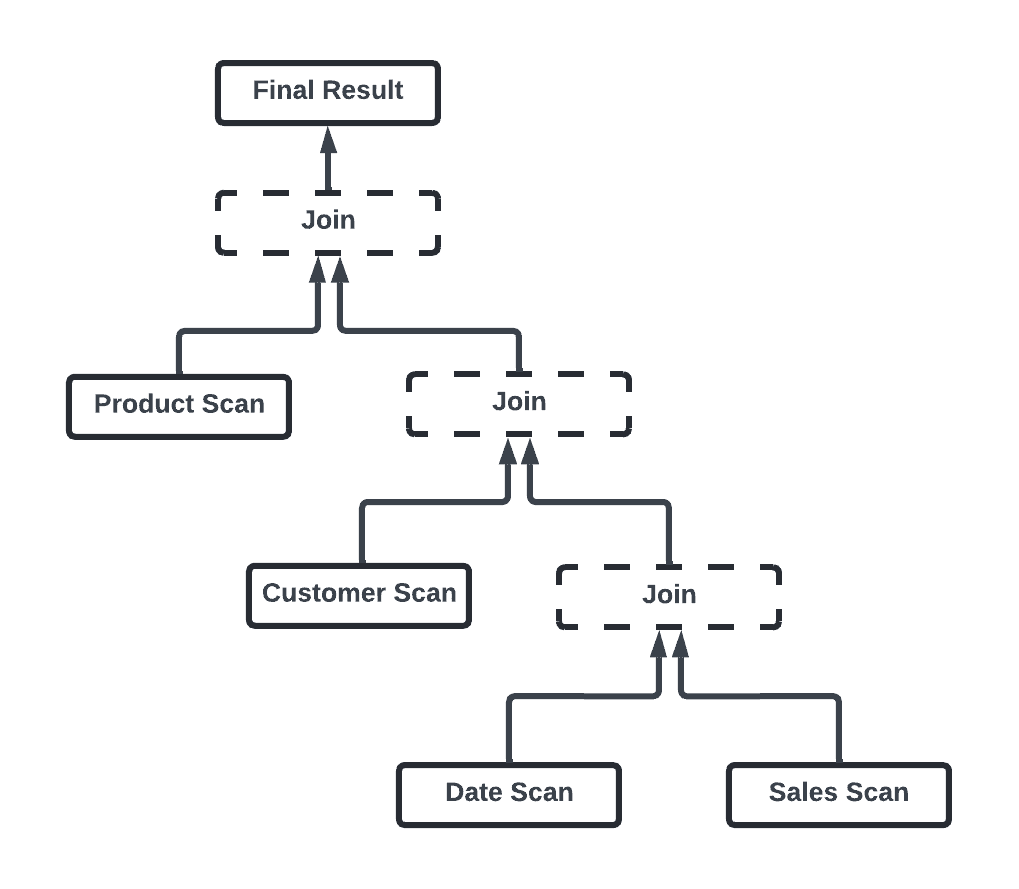
Figure 6. Right-deep join tree example.
The right-deep join structure thereby allows for efficient pipelining of data, enabling each join to process the results of the previous join immediately without intermediate materialization of data. However, selecting the appropriate join strategy at each stage is critical to prevent overcommitting resources.
Coordinated join decisions
Since all joins in these right-deep pipelines execute in parallel and compete for resources, coordination of their join decisions is crucial to ensure optimal performance and resource efficiency. By making a holistic decision about which joins in the pipeline can use broadcast joins and which should employ hash-partitioning hash joins, we can prevent memory overcommitment caused by excessive broadcast joins. This approach helps avoid performance degradation and cost increases, leading to more efficient execution of complex join operations.
Below is an example that illustrates how we coordinate join decisions adaptively to pick the most effective join strategy.
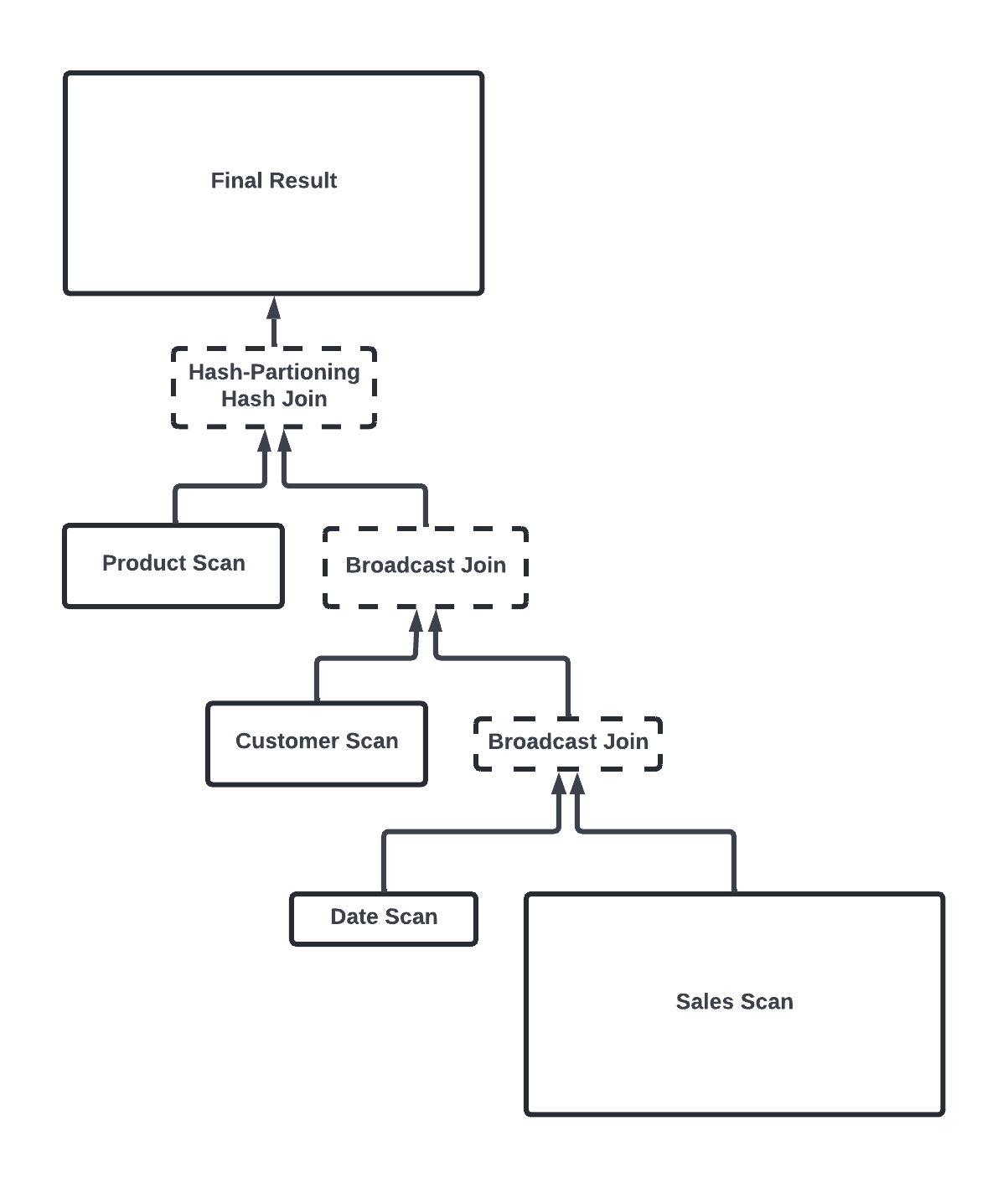
Figure 7. Example of how Snowflake makes adaptive join decisions.
By making decisions adaptively at runtime, Snowflake eliminates the need to rely on potentially inaccurate build size estimates during compilation. This prevents memory overcommitment, which can cause query failures, and under-commitment, which leads to slow queries. Inaccurate estimates often result from complex join inputs, such as intricate subtrees or rows with variable-length data types.
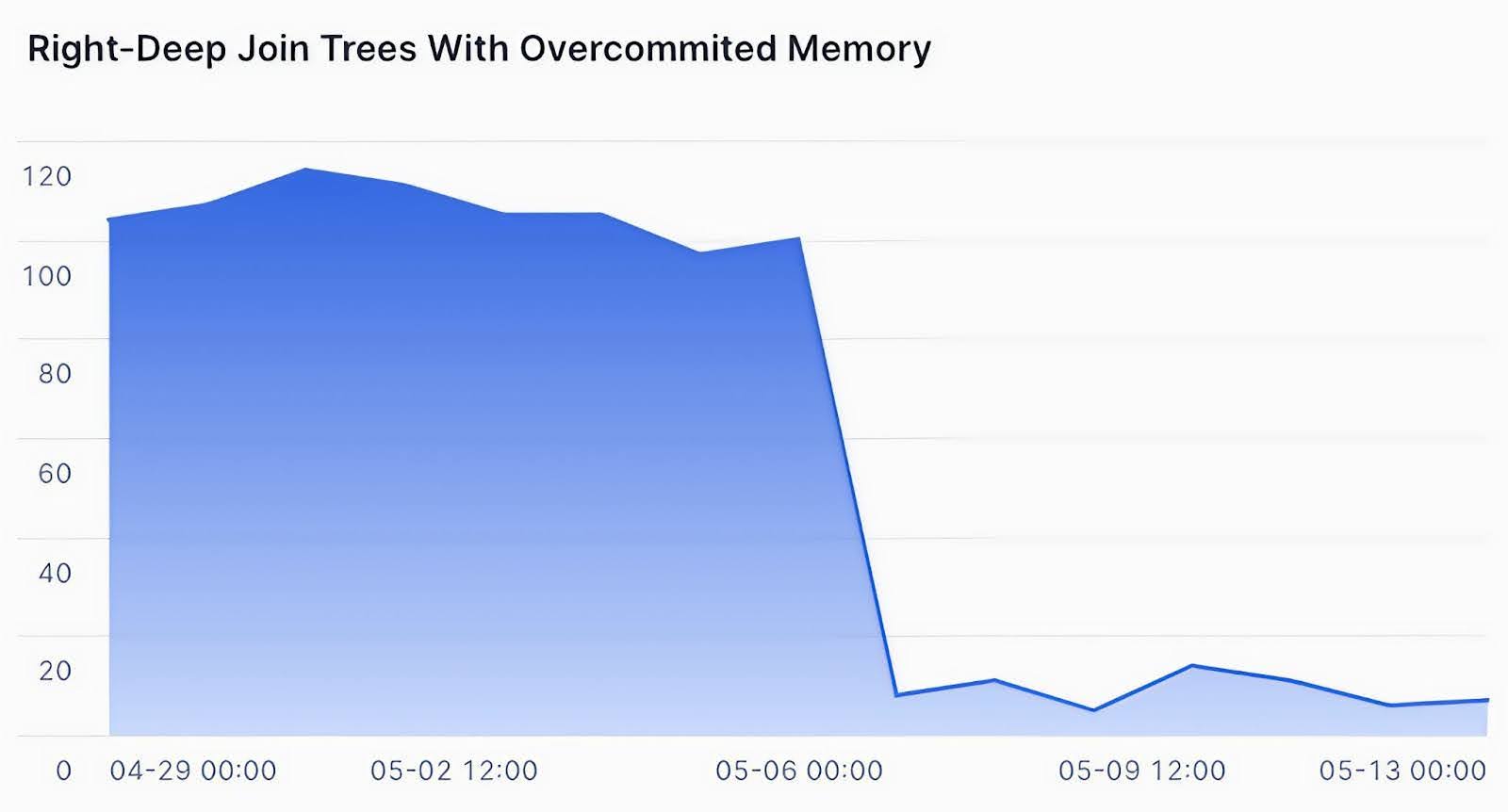
Real-world impact
Thanks to the new adaptive decision model, hundreds of thousands of queries per day benefit from at least one modified join decision within right-deep join pipelines. For example, in one customer scenario, we observed up to a 10x improvement in memory management for queries utilizing right-deep join trees. The latency of these specific queries improved by an average of 2.5x.
Conclusion
At Snowflake, we're on a continuous quest to enhance performance, with a particular focus on accelerating the core database engine, and we are proud to deliver these performance improvements through our weekly releases. In this blog post, we covered a recently released performance optimization that’s broadly applicable, highly impactful and now generally available to all customers.
To learn how Snowflake measures and prioritizes performance improvements, please read more about the Snowflake Performance Index here. For a list of key performance improvements by year and month, visit Snowflake Documentation.
*Based on a randomly sampled, representative workload across more than 500 accounts.
Authors

