
Top-K queries, which retrieve the Top “K” results based on specific criteria, are foundational in analytics, from performing ad hoc data analysis to rendering data tables on business intelligence (BI) dashboards. However, the conventional approach is often inefficient when queries request the Top-K groups in a data set. Typically, all groups are aggregated, only for many to be ignored if they fall outside the Top-K range. This inefficiency stems from how most query optimizers process data in reusable chunks, even when the results ultimately discard most of those chunks.
At Snowflake, we continuously seek to minimize redundant computation, executing only the necessary processing to yield correct results. Particularly for complex queries, this approach helps reduce wasted resources on rows that don’t contribute to the final result. By refining how we handle Top-K queries, we can help customers get to insights faster and reduce the overall compute cost. In this blog post, we will cover how we implemented additional improvements to Top-K pruning with aggregation for all of our customers. You can learn about our journey from previous posts here and here.
Introducing Top-K Aggregation: Early filtering of non-essential groups
In certain scenarios, we can determine early in query execution which groups won’t appear in the Top-K result. The Top-K Aggregation optimization activates when the primary sorting criterion is a grouping key (such as store ID) rather than an aggregate function (such as total sales). For instance, suppose a dashboard displays total sales by store, limited to the top 10 stores. Once we identify the first 10 store IDs, we can safely discard rows from other stores as irrelevant to the query output.
By filtering out unnecessary rows early, we save on the computational cost of aggregating and handling them in downstream operations. This is achieved using a specialized heap structure that works alongside our existing hash table for aggregation, setting this process apart from a standard Top-K query. Here’s how this works in practice:
- Standard Top-K heap: Each incoming row is checked against the heap. If the row qualifies, it’s added; otherwise, it’s discarded.
- Aggregate Top-K heap: Rows that meet the criteria and match an existing hash table entry update aggregate functions (e.g., summing sales). New entries that meet the criteria are added to the hash table. This structure is optimized to handle unique group entries, so we avoid the inefficiency of duplicates for more memory-efficient processing.
The ability to differentiate between necessary and redundant rows allows us to perform a minimal number of aggregate operations, avoiding wasted computation. This not only speeds up the query but also frees up resources for more intensive tasks, making the query engine more efficient.
Further optimize query efficiency by proactively enforcing Top-K limits
To optimize efficiency, Snowflake enforces Top-K limits as early in the query plan as possible. Our query optimizer analyzes the query plan from top to bottom, activating the Top-K optimization wherever possible. Simple operations like projections and outer joins don’t alter row counts and allow us to retain this optimization. More complex operations, such as filters and inner joins, still permit a modified Top-K optimization.
When the optimizer encounters an Aggregate node with an active Top-K optimization, an aggregate Top-K heap is added to the node. Additionally, when a TableScan node encounters this “filtered” optimization, it uses the top row of the heap to determine the boundary for row pruning. By pruning rows early, Snowflake avoids scanning unnecessary partitions, drastically reducing I/O.
The real-world impact: Faster queries for all
In November 2024, this optimization affected about 9 million queries per day (on average), benefiting 15% of Snowflake’s customer base. From May to September 2024, customers have seen an average reduction in query duration by 3.4% across the affected workloads, with 16% of the affected workloads running at least 2x faster. For example, a global consulting firm experienced an impressive 22% improvement, which relies heavily on “select distinct … order by limit” clauses, an ideal use case for this optimization.
Ratio of avg. query duration before and after the optimization
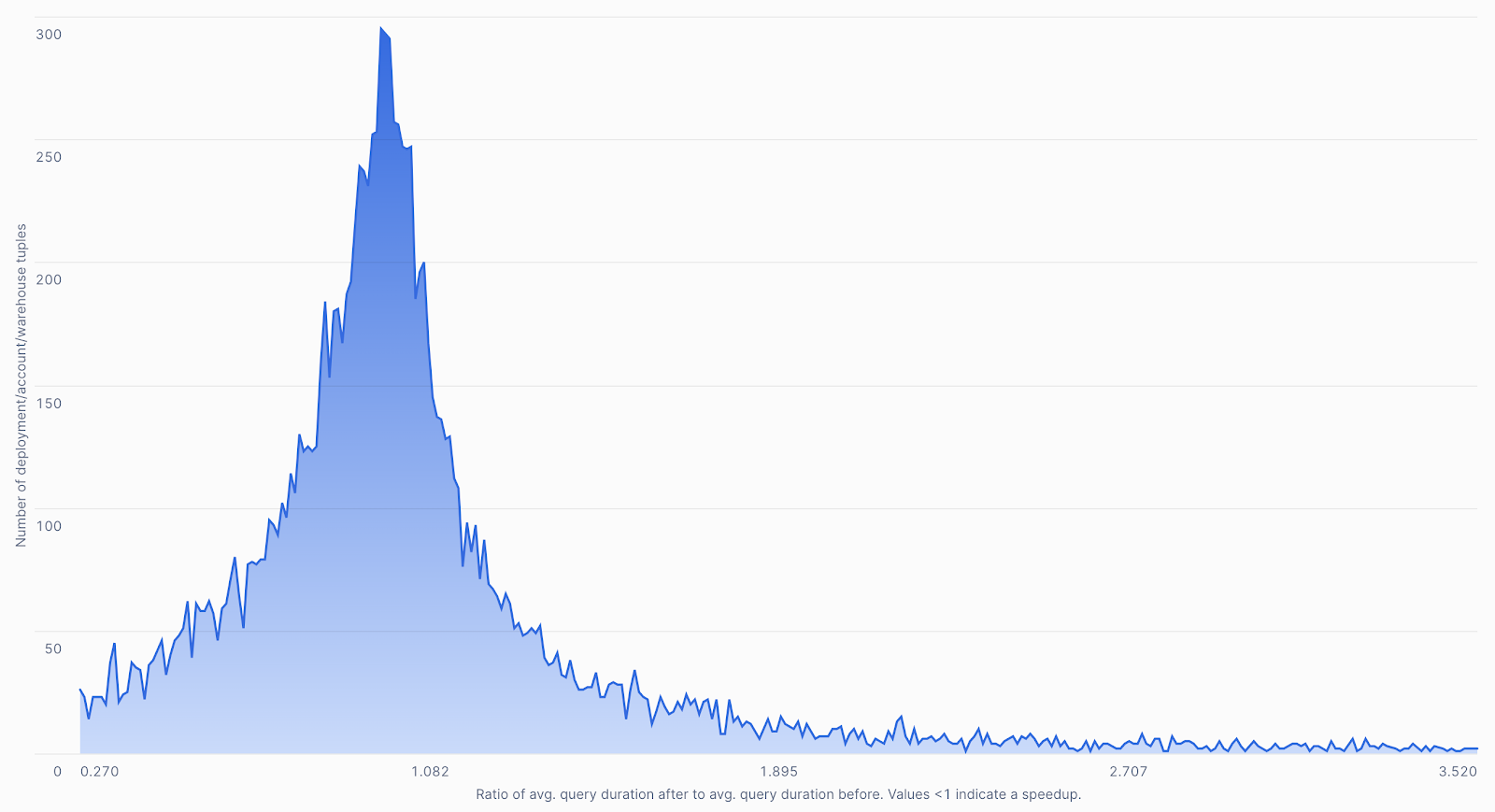
By optimizing Top-K queries, we not only decrease query run time but also significantly reduce system resource utilization. This gives teams faster results and leaves room for handling even more queries.
Enhanced performance with Top-K Aggregation pruning
Top-K Aggregation pruning extends our original optimization by sharing the Top-K heap with TableScan nodes. By referencing the heap’s top row, TableScan nodes can prune out partitions that will not be in the Top K, skipping redundant I/O. This makes query execution significantly faster.
Since the general availability of Top-K Aggregation Pruning, we have seen an additional 5% of runtime improvement to more than 3 million queries per day on average on top of all the performance benefits that the early filtering technique had brought. A major mobile service provider in Singapore, saw their Top-K Aggregation queries sped up by over one hundredfold, going from 1.5-minute to sub-second runtime. Such improvements emphasize Snowflake’s commitment to providing the fastest analytics experience for our customers.
A cross-team success story: From hackathon to core feature
The journey of Top-K Aggregation Pruning began as two separate projects from our internal Snowvation hackathon. Developed independently by Snowflake engineering teams across multiple offices, the project became one of the most impactful features of recent years. The engineering team harmonized the Top-K heap data structures used across different operators to enable seamless compatibility, even across distributed systems — a testament to Snowflake’s cross-time-zone collaboration and technical rigor.
The Future of Top-K Aggregation
Snowflake’s commitment to performance means our work on Top-K Aggregation is far from over. We are already exploring further refinements, such as extending Top-K optimization to even more complex query scenarios and improving Top-K pruning for intricate aggregations. As we continue innovating, our focus remains on providing faster, more efficient analytics solutions that empower our customers to make data-driven decisions faster than ever.
Interested in learning more? Hear how Juliane Waack, a Software Engineer at Snowflake, helped build Top-K pruning into Snowflake.
