
In May 2024, Snowflake announced free table conversions and assessments with SnowConvert, our high-fidelity, native code conversion tooling, to accelerate data warehouse migrations. Correct code conversion is critical to minimize issues when testing a migrated system.
Today, we are pleased to announce an expansion of SnowConvert’s capabilities. You can now convert tables and views for Oracle, Teradata and SQL Server without needing to engage with Snowflake Professional Services. This enhancement enables you to convert your entire data model and accelerate your transition to Snowflake faster than ever before.
As part of this announcement, we want to provide more detailed information on the inner workings of SnowConvert, so you can understand its real power and value at the core of a migration project from a legacy data warehouse platform.
What is SnowConvert and how does it work?
SnowConvert understands the semantic differences between legacy platforms (Oracle, Teradata and SQL Server) and Snowflake. For example, SnowConvert understands how strings are operated in Teradata Teramode and generates code that is equivalent in Snowflake without the need to modify the underlying data. The more accurate the code conversion is, the easier the next step in the migration process will be.
SnowConvert is a type of tool known in computer science as a transpiler, or a source-to-source compiler. The key difference between a compiler and a transpiler lies in the level of the output code. A compiler typically generates machine code, which is interpreted directly by the computer. By contrast, a transpiler generates high-level code that is semantically equivalent to the input but remains human-readable and understandable by a programmer.

Internally, SnowConvert processes the code in two stages: the frontend transpiler and the backend transpiler. The frontend stage reads the source code and creates an intermediate representation, while the backend stage transforms this representation and generates the final source code.

This frontend stage has three components: a scanner, a parser and a semantic analyzer.
SnowConvert begins by loading the file containing the source code into memory. The scanner then reads the text and breaks it into tokens. For example, the scanner will take the statement SELECT * FROM A, B and break it into individual tokens.

Tokens are the individual words or symbols that make up a statement. Once the list of tokens is generated, the parser begins its work. The parser recognizes the grammatical syntax of the input language and generates an intermediate representation based on the tokens provided by the scanner. This intermediate representation is typically represented using an Abstract Syntax Tree (AST).

As shown in the diagram above, we have a set of nodes with a root node representing the SELECT token. The leftmost leaf is the asterisk (*), and under the FROM node, we have A and B as its child nodes. This internal data structure is used to make decisions on how to convert the syntax into semantically equivalent Snowflake code.
In the expression we’re considering, it’s not immediately clear whether A and B represent tables or views. This contextual information is inferred by the semantic analyzer. You can think of the semantic analyzer as a „tree decorator“ that adds the necessary context to the various nodes in the tree.

Once we’ve gathered all the information that can be inferred from the input files and created the decorated ASTs, the second stage of SnowConvert — the backend — comes into play, specifically the component we call the Transformer.

By now, it should be clear that SnowConvert is not a simple find-and-replace tool; it is a highly sophisticated conversion tool, powered by artificial intelligence and pattern-matching algorithms.
The role of the Transformer is to translate specific patterns into their equivalent Snowflake representations. This process modifies the AST, as shown in the diagram above. The Transformer uses a recursive algorithm to rewrite the AST until its structure fully matches the Snowflake syntax and semantics. In this simple example, we are adding a schema name to each of the two data sources.
Finally, once the translation is complete, the last step is what we call the „pretty printer.“ The pretty printer takes the AST and generates the output code, which is then written to a file that can be executed by Snowflake.

Now that we understand the inner workings a bit better, let’s see SnowConvert in action with a couple of examples.
Examples
Let’s start with an interesting Oracle View (Oracle on the left, converted Snowflake on the right):
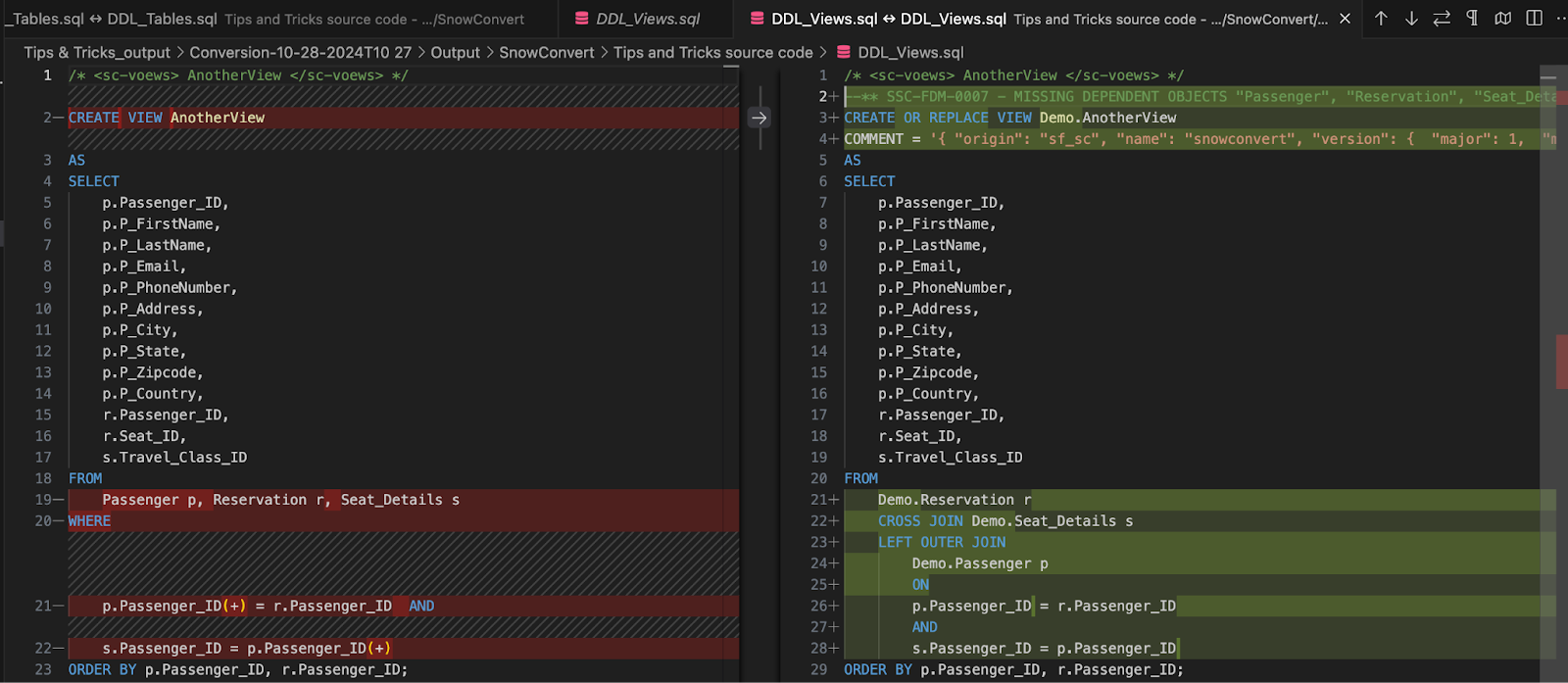
As you can see, the Oracle view uses a complex outer join pattern, which SnowConvert translates into a cross join plus a left outer join. SnowConvert handles this complexity for you. Now, imagine having hundreds of views with this pattern: How much time would the automatic conversion save you?
Another detail is the naming convention. You can configure SnowConvert to automatically add schema names to the objects. While this might seem like a trivial task when done once, repeating it for all of your objects would take a significant amount of time.
Let’s look at a similar example with an Oracle materialized view and see how SnowConvert migrates it to a Snowflake Dynamic Table.
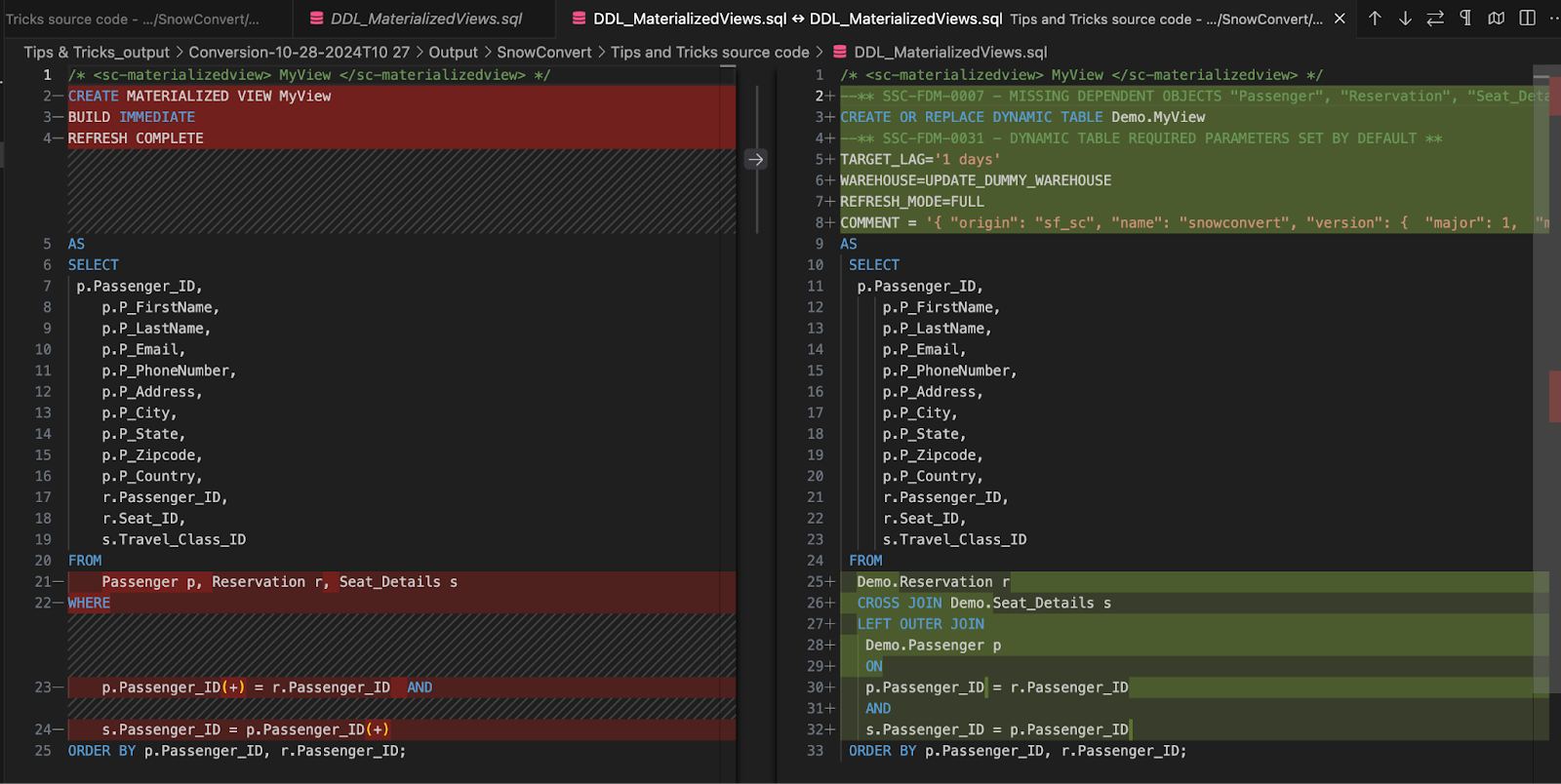
Once again, complex view syntax was seamlessly migrated to Snowflake, taking advantage of some of the latest features, such as Dynamic Tables.
Finally, let’s examine a complex pattern in an Oracle procedure and see how SnowConvert can assist with the migration.
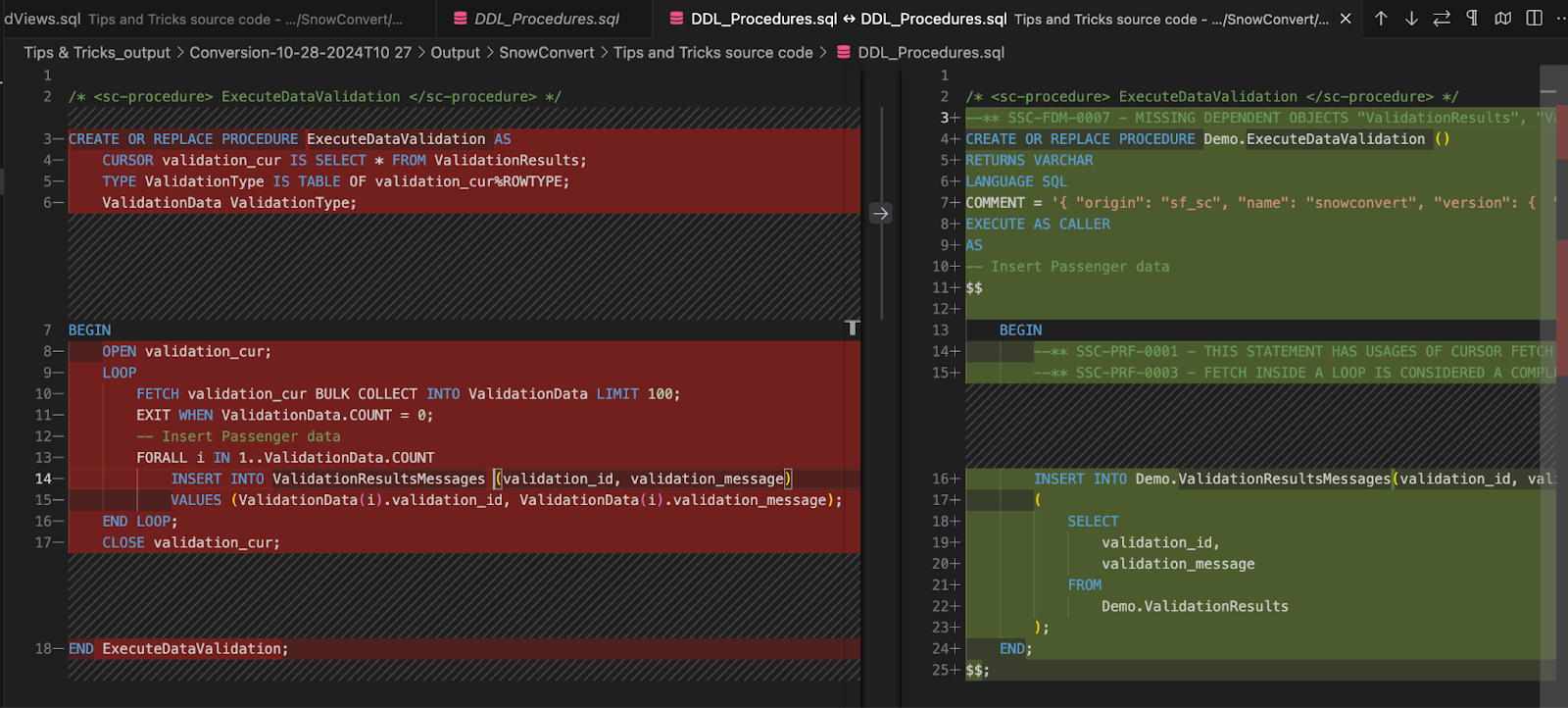
The procedure has a cursor declaration, then opens the cursor and starts looping. Each time the cursor fetches a row, it inserts the values in the new table.
SnowConvert detected this bulk insert pattern and automatically translated it into an INSERT INTO statement. The INSERT syntax uses the SELECT defined in the cursor declaration. Additionally, SnowConvert identified that the INSERT only requires two columns from the original tables, so instead of a SELECT *, it optimized the query to include only the necessary columns.
While the ability to convert procedures is currently available only with a Snowflake Professional Services agreement, this demonstrates how you can accelerate migration projects by minimizing the time spent on converting and fixing complex patterns like this one.
If you’re considering a migration from Oracle, Teradata or SQL Server, we encourage you to explore Snowflake’s migration tools and resources to help speed up the process.
Conclusion
In summary, SnowConvert now allows you to migrate not only your table DDLs but also your view DDLs — essentially your entire data model. This enables your business users to start familiarizing themselves with Snowflake as quickly as possible.
With more than 1.7 billion lines of code converted to date, we recommend you consider utilizing this free accelerator when planning your migration projects. To access SnowConvert, Snowflake provides free training before granting tool access. Training is required because, while operating SnowConvert may seem simple — just point to some legacy code, click „convert“ and get the converted code — it’s important to understand the scope of its capabilities and limitations to ensure the best results and avoid common mistakes.
Once you complete the training, you’ll gain access to SnowConvert in Assessment mode. This allows you to assess all your legacy code and generate converted code for your TABLE and VIEW DDLs.
Additional SnowConvert features are available when you enter into a support relationship with Snowflake Professional Services. At Snowflake, we’re committed to helping you get the most out of the tool, sharing lessons learned from converting millions of lines of code for hundreds of enterprises worldwide.
To learn more about SnowConvert from migration experts, join our free webinar.


