Snowflake Arctic Embed Joins ArcticTraining: Simple And Scalable Embedding Model Training

We are pleased to announce that the Arctic Embed project has migrated its core training code into the open source ArcticTraining project. Though Snowflake has released all of its AI models under a permissive Apache 2.0 license since Day 1, today we’re going a step further to enable a broader community to engage directly with the tools behind our embedding models' development. This new open code release adds to the rich body of detailed technical publications on our model training processes, making it now easier than ever to reproduce, extend and remix our work to create the world’s most efficient frontier embedding models.
Climbing onto the shoulders of giants: DeepSpeed and ArcticTraining
Our newly migrated training codebase allows Arctic Embed to build upon ArcticTraining and DeepSpeed (which serves as the backend for ArcticTraining). DeepSpeed is a mainstay in AI model development and is used for many embedding model training workloads, including those of Alibaba’s GTE team, Nomic’s team, and Jina AI’s embedding team. As such, we are excited to join the list of teams leveraging the same easy-to-use ZeRO stage 1 memory efficiency optimizations that have made DeepSpeed the tool of choice for so many others. Notably, this transition brings us greater ease of scaling up to larger model sizes.
DeepSpeed’s unopinionated CLI entry point and laissez-faire approach to training script management leave it up to end users to maintain clean pipelines for experimentation. While simple for smaller projects, things can become complex in long-term projects and projects shared between multiple collaborators who may have different styles of organizing their work. This is where ArcticTraining comes into the picture for Arctic Embed.
ArcticTraining is the front door to DeepSpeed, providing much-appreciated ease-of-use abstractions, including automatic validation of job configurations, to make it easier to organize training code and experimental workflows. While migrating from our previous pure-PyTorch implementation to standard DeepSpeed patterns would have been a major paradigm shift, ArcticTraining implements a clean, pydantic-validated, and config-driven parameterization of training quite similar to what we built into our previous implementation. This made for a smooth transition of our training codebase.
Thanks to DeepSpeed and ArcticTraining, the new Arctic Embed training codebase is now more powerful and simpler to use than the original implementation used to train Arctic Embed 1.0, 1.5, and 2.0, and we are thrilled to be sharing it openly with the world.
Key feature: Generalized contrastive data representation
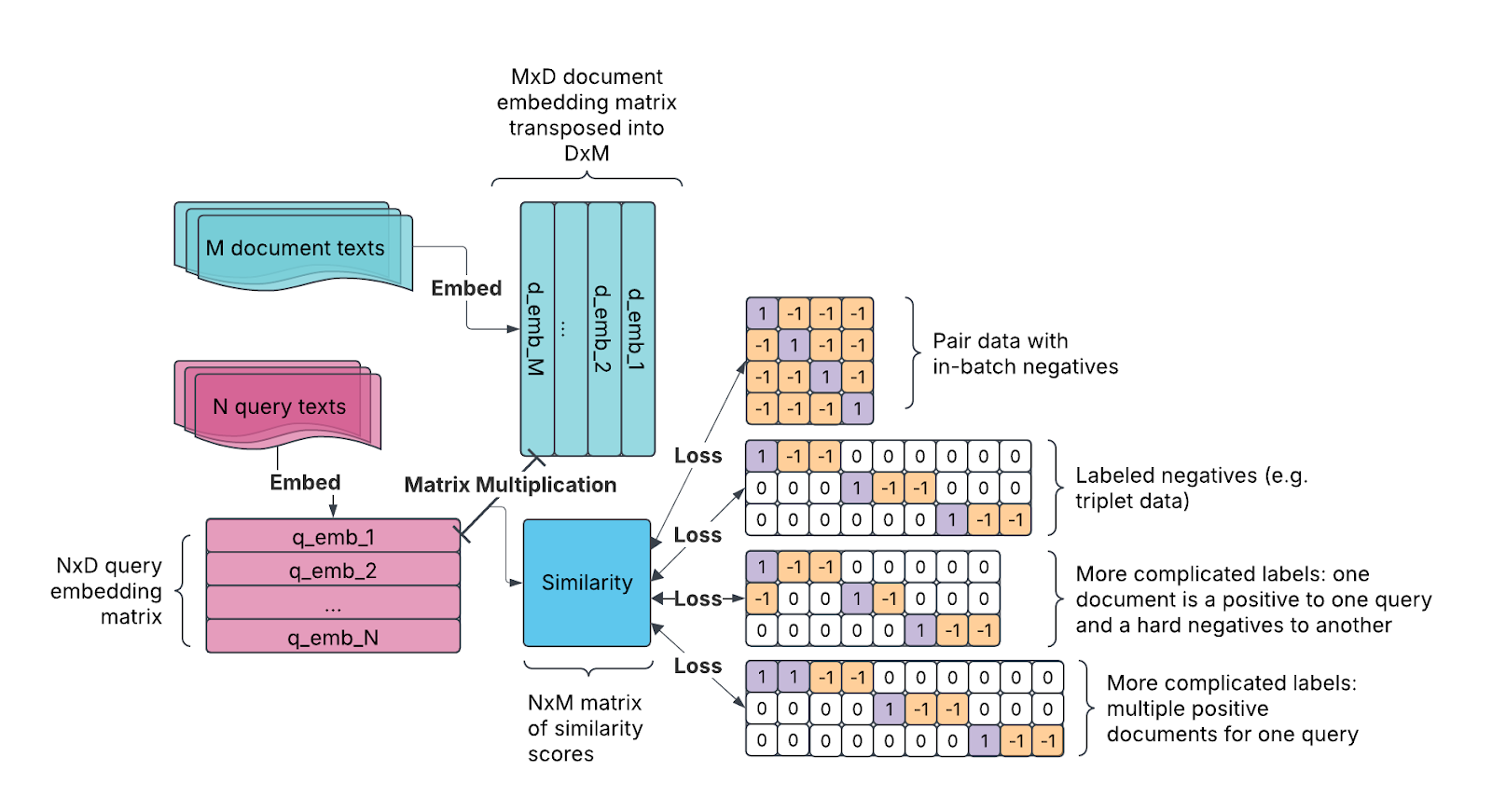
Of all the details we will discuss, Arctic Embed’s most distinctive design decision is its highly generalized formulation of a contrastive data batch. Several other codebases have specialized data formatting conventions, data loading code, and loss functions for large-scale semisupervised contrastive training (often called “pair data”) and for smaller-scale training with explicitly labeled negatives (often termed “triplet data”). Arctic Embed’s training code, on the other hand, centers around a single formulation which not only supports both of these special cases but can also represent other more complicated patterns with ease as well, as seen in Figure 1.
Not only is this formulation highly flexible, but it also makes certain common data mistakes impossible. For example, when we have two labeled positive examples for the same query, the common approach of grouping data into independent triplet examples can accidentally label a known positive as a negative when in-batch negatives are used (e.g., as they are used in the BGE recipe). With the Arctic Embed data representation, it is impossible to use a known-positive document as a negative example for the same query since there is only a single spot in the label matrix for each unique query-document relationship.
Arctic Embed’s data representation is not just flexible and conceptually approachable, it is also efficient, since it deduplicates any possible redundant computation incurred by queries and documents that serve multiple roles within a batch (e.g., some queries have multiple positive documents which lead to duplications in triplet-form data). As the label matrix can be quite large for a large batch of queries and documents, our implementation stays efficient even at large batch sizes by utilizing PyTorch’s built-in sparse matrix support to reduce memory overhead. We also avoid storing unknown query-document relationships on disk in our data storage format, leveraging analogous sparsity to minimize data storage footprint as well.
This new convention comes with batteries included
The power of this generalized data format isn’t completely free. For example, getting our code for data loading, embedding, and loss calculation to cleanly model the underlying mathematical model of contrastive training took more work upfront and required some extra custom code (e.g., we had to implement a custom loss function to avoid memory overhead from performing matrix reindexing inside PyTorch’s autograd computational graph). Luckily for users of Arctic Embed, the heavy lifting has already been done for them.
We also include simple tooling for data preparation to make it easy for users to dive into the Arctic Embed way of handling contrastive training data. While Arctic Embed increases the requirements of data preprocessing, in which all training data must be converted into a batched format prior to running the training loop, there is minimal overhead on the user because this conversion is provided as a native function of the codebase to ensure you can get up and running quickly.
In practice, we have found that our distinctive approach to data set preparation notably improves debuggability and iteration speed by simplifying the training code, so we encourage you to take our approach for a spin.
Getting the details right
Thanks to a collaboration with core DeepSpeed maintainers, Arctic Embed has gone deep to iron out a few details that make for subtle but appreciable quality-of-life improvements. For example, our implementation hooks deep into DeepSpeed to properly rescale gradients in distributed training, adjusting for the unique wrinkles of data-parallel backpropagation of contrastive loss. While in practice improper rescaling does not generally have a large impact on training trajectory, because the ubiquitous Adam optimizer is invariant to gradient rescaling, it does allow us to log and clip gradients accurately, improving visibility into the training process. Other polished details include native Weights & Biases integration, easy toggles for gradient checkpointing, our signature simple-and-quantization-friendly Matryoshka Representation Learning loss function, and support for in-training validation on multiple dev data sets.
Walkthrough: Rejuvenating the original E5 models with modern fine-tuning
In late 2022, the paper Text Embeddings by Weakly-Supervised Contrastive Pre-training introduced the E5 family of retrieval models and established the modern paradigm of large-scale contrastive training for high-quality retrieval models. Though the benchmark scores of the E5 models were quickly eclipsed by follow-up works, like the GTE models from Alibaba’s team, these benchmark comparisons are somewhat skewed. The original E5 models only used two retrieval data sets in their fine-tuning (MSMARCO and NQ), while follow-up works frequently extend to half a dozen or more, drawing upon the training splits of data sets used in common benchmarks like BEIR, making for an unfair comparison. Adding another wrinkle to the story, the recent paper NV-Embed: Improved Techniques for Training LLMs as Generalist Embedding Models has demonstrated that these extra fine-tuning data sets can, in addition to driving “unfair” in-domain performance gains, also deliver impressive improvements out of domain as well.
Given these observations about the generalizable benefits of diverse and extensive fine-tuning for retrieval, we thought it would make for an interesting demonstration to investigate how well the original E5 models can do when fine-tuned with a more modern data recipe in an explanatory walkthrough included within the Arctic Embed code release. Since we have provided all the code for this example in our release (as well as extensive documentation in the corresponding README file), we will focus on the high-level details in this post.
Spoiler alert: The results are great
We find that after upgrading the fine-tuning data, we can use the Arctic Embed training code to fine-tune ourselves an e5-base-arctic-finetune that keeps pace with other leading ~100M-parameter models on the BEIR leaderboard. We also find that when evaluating an out-of-domain news retrieval task (CLEF English), the model continues to do well, scoring nearly as well as Arctic Embed M 2.0 and outperforming a bevy of other BEIR leaderboard-leading models.
| Model | BEIR Score (nDCG@10) | CLEF English Score (nDCG@10) |
|---|---|---|
| e5-base-v2 (original) | 50.19 | 45.38 |
| e5-base-arctic-finetune (new) | 54.70 | 52.77 |
| gte-base-en-v1.5 | 54.02 | 47.91 |
| arctic-embed-m-v1.0 | 54.89 | 47.62 |
| arctic-embed-m-v2.0 | 55.38 | 54.06 |
Table 1. Experimental results. Since we have run evaluation at bfloat16 precision, there may be slight discrepancies between these figures and official MTEB leaderboard numbers.
Modern fine-tuning data
The core idea of this example is to pull together numerous open high-quality retrieval training data sets, mine for hard negatives using a high-quality teacher model, and replace the original E5 fine-tuning step with our own training code. We begin with high-quality retrieval data from five sources: FEVER, HotpotQA, MSMARCO, NQ, and StackExchange. We then use the Arctic-embed-l-v2.0 model to mine high-quality, hard-negative examples, using thresholding to discard potential false-negative examples during mining (see NV-Retriever: Improving text embedding models with effective hard-negative mining for extended discussion of effective hard-negative mining). We end up with a fine-tuning data set of just over 1 million queries, each paired with 1-3 positive documents and 10 negative documents.
We are releasing the full data set, including all intermediate states, on Huggingface. We have also released all the code to run the data processing as part of the walkthrough example in the Arctic Embed codebase.
Simple, scalable training
The core training script drives one epoch of training through our high-quality fine-tuning data set using the industry-standard InfoNCE loss. On eight H100 GPUs, we accomplish the full fine-tuning run in less than an hour. Under the hood, this training script leverages not only ArcticTraining’s configuration validation and ease-of-use figures but also the powerful ZeRO Stage 1 memory optimizations provided by DeepSpeed.
Since all data preparation code, training data, training code, the base model and our final model are openly available, it is easy to get started on your training experiments. If you take the data and/or code for a spin, please share your experience on the Snowflake Community Forums AI Research And Development Community!
The future
Though Arctic Embed has historically focused on a pragmatic tradeoff between efficiency and quality, with the unsurpassed memory efficiency of DeepSpeed under our feet we are now excited to scale up and explore the 1B+ parameter range to explore more quality-focused tradeoffs between compute and retrieval accuracy. The DRAMA models have recently shown some lovely scaling trends in the 0.1B to 0.3B to 1.0B parameter range, and we are excited to explore this frontier ourselves. For both the Arctic Embed team and the broader community, we look forward to continuing our efforts toward putting out great models for search — further empowering the community with the tools needed to fine-tune these models to meet their needs and opening up channels for deeper collaboration.
With that said, we are also excited to see the future endeavors of the open source community, as you all begin to build your own embedding models. To get started, explore the Arctic Embed codebase today and share your experiences in the Snowflake Community Forums AI Research and Development Community.
Contributors
Snowflake AI Research: Michael Wyatt, Jeff Rasley, Stas Bekman, Puxuan Yu, Gaurav Nuti
Authors
