Data Vault Techniques on Snowflake: Streams and Tasks on Views 

Snowflake removes the need to perform maintenance tasks on your data platform and provides you with the freedom to choose your data model methodology for the cloud. When attempting to keep the cost of data processing low, both data volume and velocity can make things challenging. To remedy this, Snowflake introduced streams as a highly scalable data object to track change data capture (CDC) data activity in order to essentially process only new data into one or multiple data pipelines from a single data object. Let’s see how this technology can be used to bring Data Vault closer to a Kappa (streaming first) architecture.
This post is number 5 in our “Data Vault Techniques on Snowflake” series:
- Immutable Store, Virtual End Dates
- Snowsight Dashboards for Data Vault
- Point-in-Time Constructs and Join Trees
- Querying Really Big Satellite Tables
- Streams and Tasks on Views
- Conditional Multi-Table INSERT, and Where to Use It
- Row Access Policies + Multi-Tenancy
- Hub Locking on Snowflake
- Virtual Warehouses and Charge Back
A reminder of the data vault table types:

When enabled, change tracking on a data object in Snowflake records INSERTS, UPDATES, and DELETES at the record level by adding two metadata columns to denote this activity. When a stream object is defined on a table with the change tracking enabled, it acts like a metadata bookmark on the data object.
Imagine the following: If the table object contains 100 records, a stream created on this object with 100 records places the bookmark at the end of the table; now when we read from these objects, we will see the following:

A read from the table will show 100 records, while a read from the stream will show 0 records. If 50 records are added to that table object, a read from the table will show 150 records and a read from the stream will show 50 records:

If we add another 50 records to the table, the read on the table will show 200 records and the stream will show 100 records:

If the stream is used as a source for a data manipulation transformation (DML), thereby ingesting the stream into a target table, then the bookmark advances to the end of the table. A read from the table will show 200 records but a read from the stream will now show 0 records, indicating that the stream was consumed and you can place as many streams on a table object as you want:

The stream object can be used in conjunction with Time Travel to set the offset to a particular point in the past state of the table. Further, a stream can be placed on:
- A standard snowflake table (of course) – append and standard stream types
- An external table – insert stream type
- A data share – append and standard stream types
- A directory table – append and standard stream types
- A snowflake view (for our purposes we will be referring to this object) – append and standard stream types are available, but we will use append only
Stream types:
- Standard – tracks SQL INSERT, UPDATE, and DELETE operations
- Append / Insert – SQL INSERT operation only

Multiple streams on a table object
Each stream can be used as a source to a DML, which in turn can be used as a base for SQL transformations. They are independent and can be processed at any velocity. A brief explanation of the above animation:
- Data A content is landed, DML is executed on Stream 2 to consume Data A into Target 2, which advances Stream 2 to the end of source data table.
- Data B content is added, DML is executed on Stream 1 to consume Data A and B into Target 1, which advances Stream 1 to the end of source data table.
- Data C content is added, DML is executed on Stream 2 to consume Data B and C into Target 2, which advances Stream 2 to the end of source data table; at the same time, DML is executed on Stream 1 to consume Data C into Target 1, which advances Stream 1 to the end of source data table as well.
Now that we’ve covered Snowflake streams, a quick note about tasks. Snowflake tasks are the other Snowflake object often used in conjunction with streams to periodically process stream content that can be orchestrated into a daisy-chained sequence of SQL statements. What’s more, a task can execute a special function to check if there is any data in the stream before it kicks off its scheduled SQL statement, and can either be associated with a virtual warehouse or deployed as serverless tasks.
Now let’s use these objects for Data Vault!
Significance of SQL views in Data Vault
In terms of Data Vault automation, SQL views come into use in three main areas:
1. Views for Virtualizing End Dates: As discussed in the first post in this series, after a satellite table is created, two default views are created over the underlying satellite table.
- Current view returns only the current record per parent key.
- History view adds an End-Date to a satellite table and an optional current-flag (1, 0).
2. Views for Information Marts (IM). As discussed in the third and fourth post of this series, the default position of IM is to deploy them as views over the data vault tables, and if suited, have them based on disposable query assistance tables such as PITs & Bridges.
3. Views for Staging: To virtualize the data vault metadata columns over landed content, let’s break down what some of these are:
- Surrogate hash keys: Durable key based on a business key for a target hub table or the unit of work for a target link table, always defined as of data type binary
- Load date: The timestamp of the record entering the data platform
- Applied date: The timestamp of the record as it was captured from the source system, an extract timestamp
- Record source: Denoting where the record came from
- Record digest, or HashDiff: Used for simplifying delta detection
- Business key collision code: Used sparingly to ensure passive integration
Having a view over the landed content removes the need to copy data for the sake of physically adding these metadata columns. Instead, as data is landed, it already contains the data vault metadata columns. Having a single point where all these metadata columns have been defined benefits the possible multitude of hub, link, and satellite table loaders needed to take the staged content and load it into the modeled target tables. Data movement is the enemy of analytic value; any opportunity to reduce this latency improves the time-to-analytical value (TTAV).
Load data at any velocity
We have streams, tasks, and views for staging, so let’s put them together to illustrate how the above can be combined to simplify Data Vault automation and apply a “set it and forget it” architecture. The problem we’re looking to solve is how to elegantly deal with multiple staged records per business key consolidated into a single load to a target satellite table. That is, a satellite table that is modeled to allow only one current active state per parent key. If we have multiple states of the business key in staging, then how do we solve this without writing a loop into our orchestration to process each staged record one at a time against the target satellite table, and load it before processing the next newer staged record?
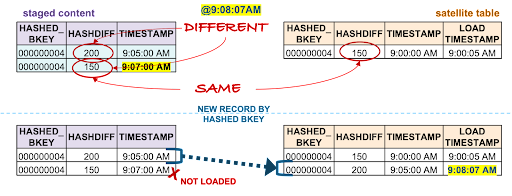
Incorrect load; the record with the highest timestamp must represent the current state of the business object
Without a way to pre-condense the records before loading to the target satellite, the model will suffer data integrity issues. In the example above, the staged record with a 9:07 AM timestamp is discarded because it matches the current active record in the target satellite table. However, because of the multiple states in staging, both staged records are compared against the target satellite table, and only one survives the delta check when in fact in this example both should.
To show that we can process the above scenario in one load, let’s imagine five scenarios by loading five business objects to track. For the sake of simplicity we will process two loads but with three records for each business key: an initial load to the target satellite and the delta load.
At 9 AM, all five business objects have the same object state (for simplicity), because this is the first time the business keys have been seen. All five business keys and their associated descriptive attributes will insert records to the target satellite table.
Now, for each business key we will process different scenarios to illustrate how this implementation deals with change deltas.
Scenario 1: No change to staged content
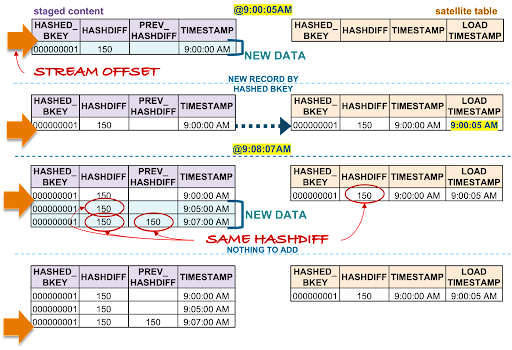
Scenario 1
Let’s use the first scenario to acclimate to the way we are depicting this technique.
On the left is the staged content as a view with a stream offset based on the stream on view, while on the right is the target satellite table. For each scenario example, staging is simplified to process one business object (in reality, there would be many more!) and a limited set of columns. Landed content continues to grow and a satellite-load operation will advance the stream offset the loader is based on.
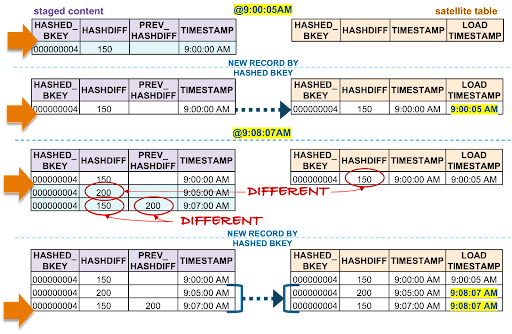
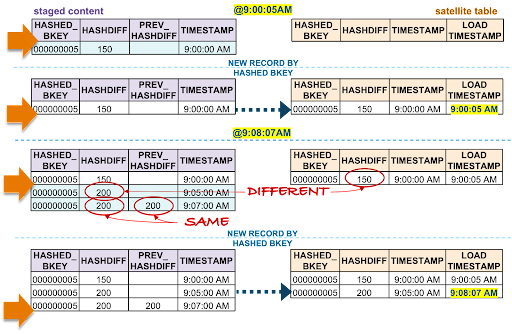
Each record has a hashdiff column and a previous hashdiff column for that record utilizing the SQL LEAD() function by the hashed key. The former column exists on the stage view, the latter column exists in the common table expression (CTE) used in the satellite loader.
Two delta detection operations will occur in one load:
- Discarding duplicate records in staging by comparing each record’s hashdiff to its previous hashdiff
- By comparing the oldest record in the staged stream on view to the current active record in the target satellite table for that hashed business key
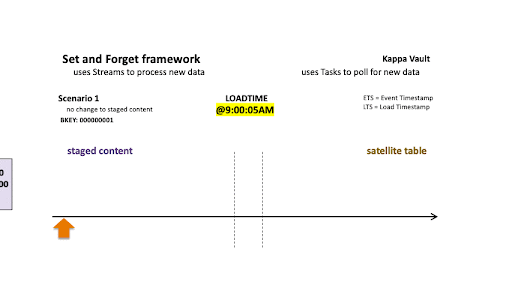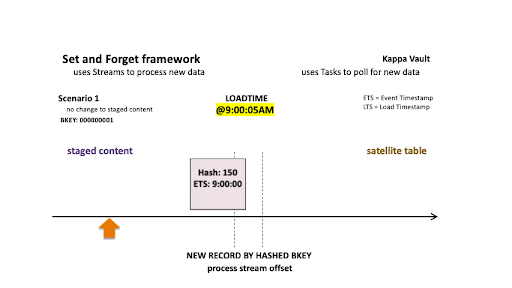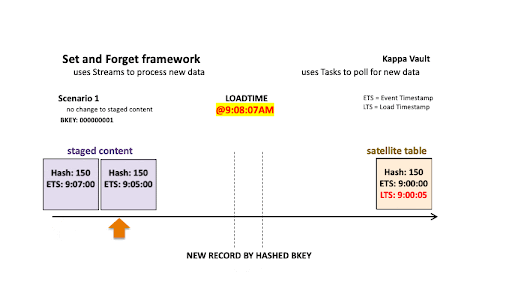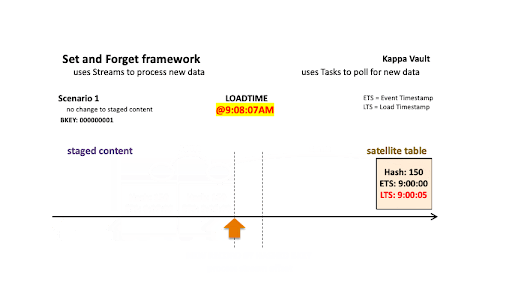
Streams ensure we reduce the volume of records being processed so the above two operations are not processing all the landed content, just the newest data since the last stream ingestion event. For this and all scenarios below, the first record is always inserted because that business object did not exist in the target satellite at the time of load at 9:00:05 AM.
Let’s process the rest of scenario 1:
- @9:00:05 AM: New data is ingested into the target satellite table, the stream offset advances, and the satellite table is populated.
- @9:08:07 AM: New data is landed; note that there are two active states of the business object:
- The staged hashdiff for the newest record is the same as the previous staged hashdiff by key. We will discard this record because it is not a true change.
- The oldest staged record has the same hashdiff as the current record in the target satellite. This record will not be inserted into the target satellite table.
With the aforementioned in mind, no new staged records are inserted to the target satellite table.
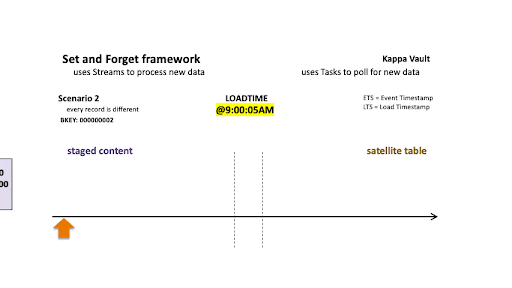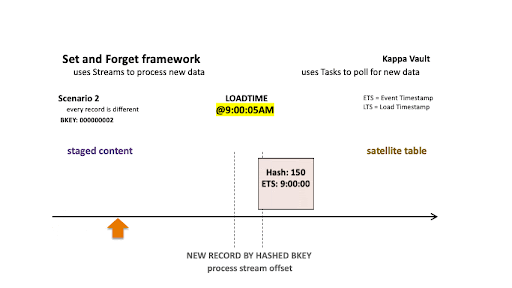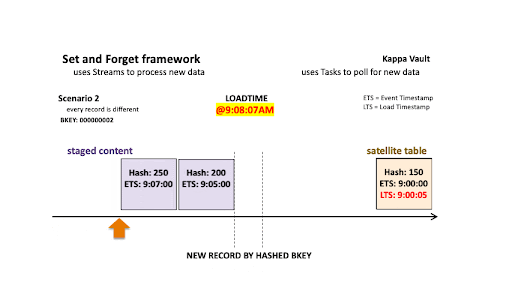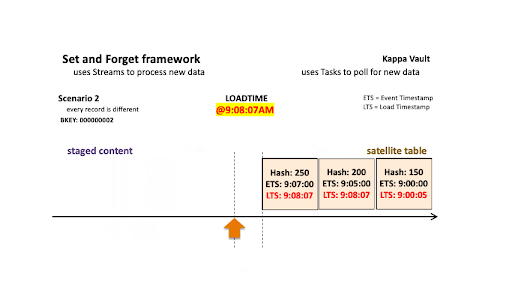
Scenario 2: Every record is different

Scenario 2
As above but for a different business object, scenario 2 depicts:
- @9:00:05 AM: New data is ingested into the target satellite table, the stream offset advances, and the satellite table is populated.
- @9:08:07 AM: New data is landed; note that there are two active states of the business object:
- The staged hashdiff for the newest record is different to the previous staged hashdiff by key. We will keep this record because it is a true change.
- The oldest staged record has a different hashdiff as the current record in the target satellite. This record will be inserted into the target satellite table.
All new staged records are inserted into the satellite table.
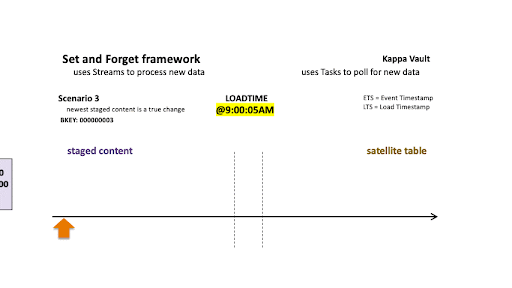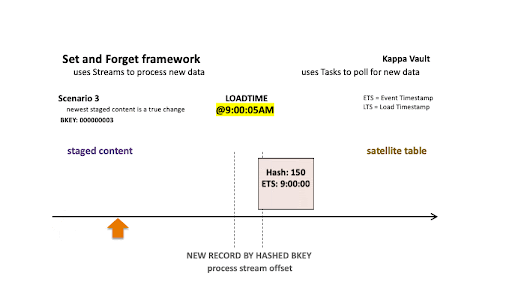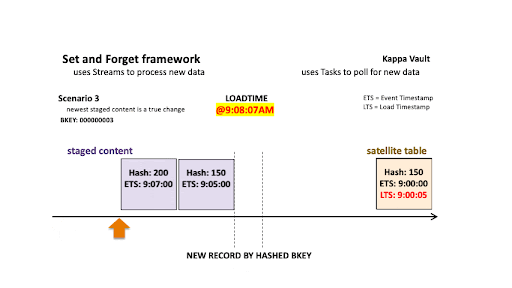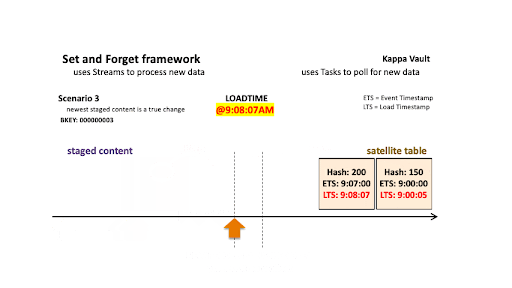
Scenario 3: Newest staged content is a true change

Scenario 3
For scenario 3’s business object:
- @9:00:05 AM: New data is ingested into the target satellite table, the stream offset advances, and the satellite table is populated.
- @9:08:07 AM: New data is landed; note that there are two active states of the business object.
- The staged hashdiff for the newest record is different to the previous staged hashdiff by key. We will keep this record because it is a true change.
- The oldest staged record has the same hashdiff as the current record in the target satellite. This record will not be inserted to the target satellite table.
Only the newest staged record is inserted into the satellite table.
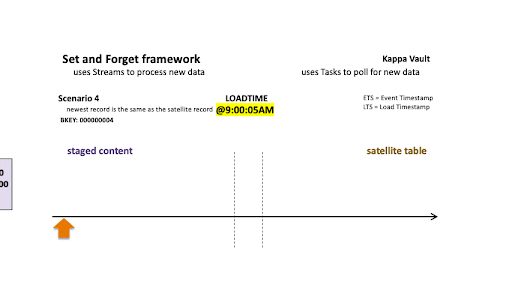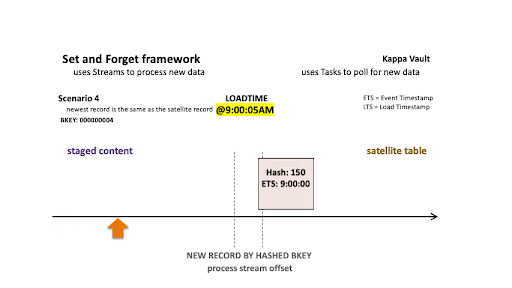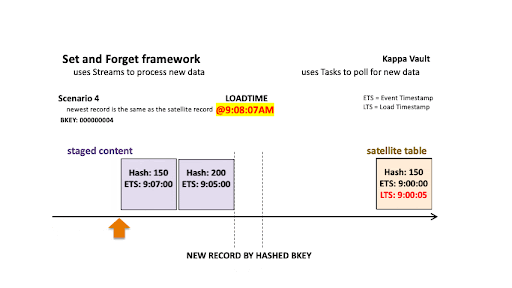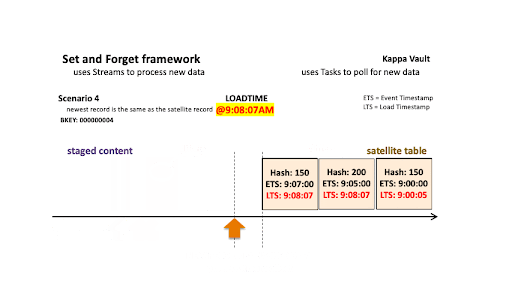
Scenario 4: Newest record is the same as the satellite record
Scenario 4
For scenario 4’s business object:
- @9:00:05 AM: New data is ingested into the target satellite table, the stream offset advances, and the satellite table is populated.
- @9:08:07 AM: New data is landed; note that there are two active states of the business object:
- The staged hashdiff for the newest record is different to the previous staged hashdiff by key. We will keep this record because it is a true change.
- The oldest staged record has a different hashdiff as the current record in the target satellite. This record will be inserted into the target satellite table.
It should be noted that the newest staged record has the same hashdiff as in the target satellite, and this is important—the newest staged record must appear as the current state for that business object. Because we have already validated that this is a true change in staging, there is no need to compare this record to the target satellite—it must be inserted.
All new staged records are inserted into the satellite table.
Scenario 5: Discarding non-true changes
Scenario 5
For scenario 5’s business object:
- @9:00:05 AM: New data is ingested into the target satellite table, the stream offset advances, and the satellite table is populated.
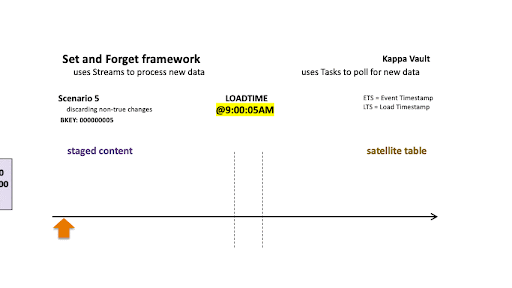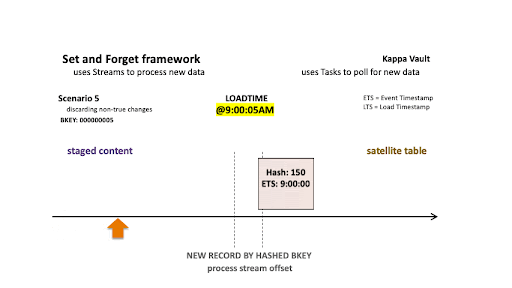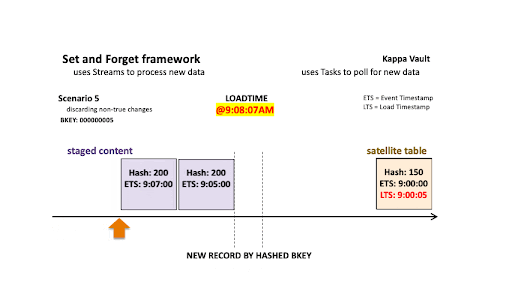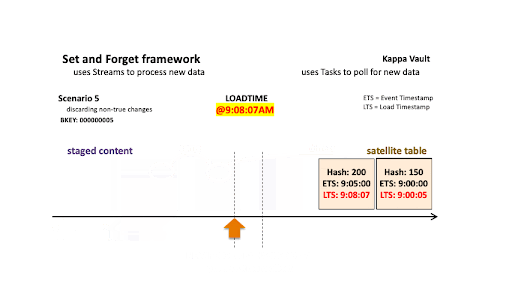
- @9:08:07 am: New data is landed; note that there are two active states of the business object:
- The staged hashdiff for the newest record is the same as the previous staged hashdiff by key. We will discard this record because it is not a true change.
- The oldest staged record has a different hashdiff as the current record in the target satellite table. This record will be inserted into the target satellite table.
Only the oldest staged record is inserted into the satellite table.
To summarize,
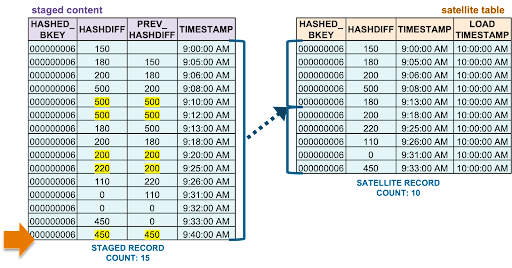
Summary of all inserts
Stream offsets move as new data is consumed by downstream DML operations. As stated earlier, you can have as many stream offsets on a supported data object as you want. This benefit allows for the use of hub, link, and satellite loaders, each with their own stream based on the single stream on view. Notice that by using streams the size of the landed content is virtualized and we never have to truncate the landed data. Streams simplify the need to orchestrate data movement in landing/staging simply by minimizing the volume of data needed for consumption, no matter the velocity of the data coming in.
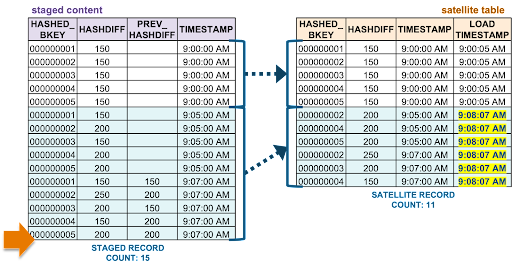
Late-arriving data
If we imagined that for account scenario 6, all 15 of its records were loaded at 10 AM, then this load pattern would be capable of dealing with 15 states of the records in one load, and discarding all duplicates during that load to advance the stream offset.
Streams on test framework
Not only can streams be used on ingestion data pipelines, they can also be used on the target tables to efficiently process data vault metrics into a test framework. We introduced this framework in post 2 of this series.. Where can we use it?
- Count for new hash keys in the hub table
- Count for new records in the satellite table
- Reconcile new hash keys with a satellite table’s parent entity, either a parent hub table or a parent link table
- Count for new hash keys in the link table
- Reconcile new hash keys with a link table’s parent entities, for each parent hub table
Using this “streams on views” framework also means you need test streams based on that same view to measure the record counts that were just inserted into your data vault tables.

Standard tests to answer standard questions
Set it and forget it
Finally, the object that can be used to automate all the above: Snowflake tasks! For each stream, a task is used to execute the load to the target hub, link, or satellite table. One task, one loader, one stream on view. Let’s summarize the Snowflake objects needed:
- Staged view: Defined once with the necessary Data Vault metadata columns to map to the target hub, link, and satellite tables. One landed file, one view.
- Streams on the view: One for each target Data Vault table being populated by this staged content. We will also need streams on the view to gather new statistics to record in our Data Vault test framework.
- Task on streams: One-to-one with the number of streams; streams needed for the test framework will be daisy-chained after the hub, link, or satellite loader tasks respectively to measure what has just been loaded.
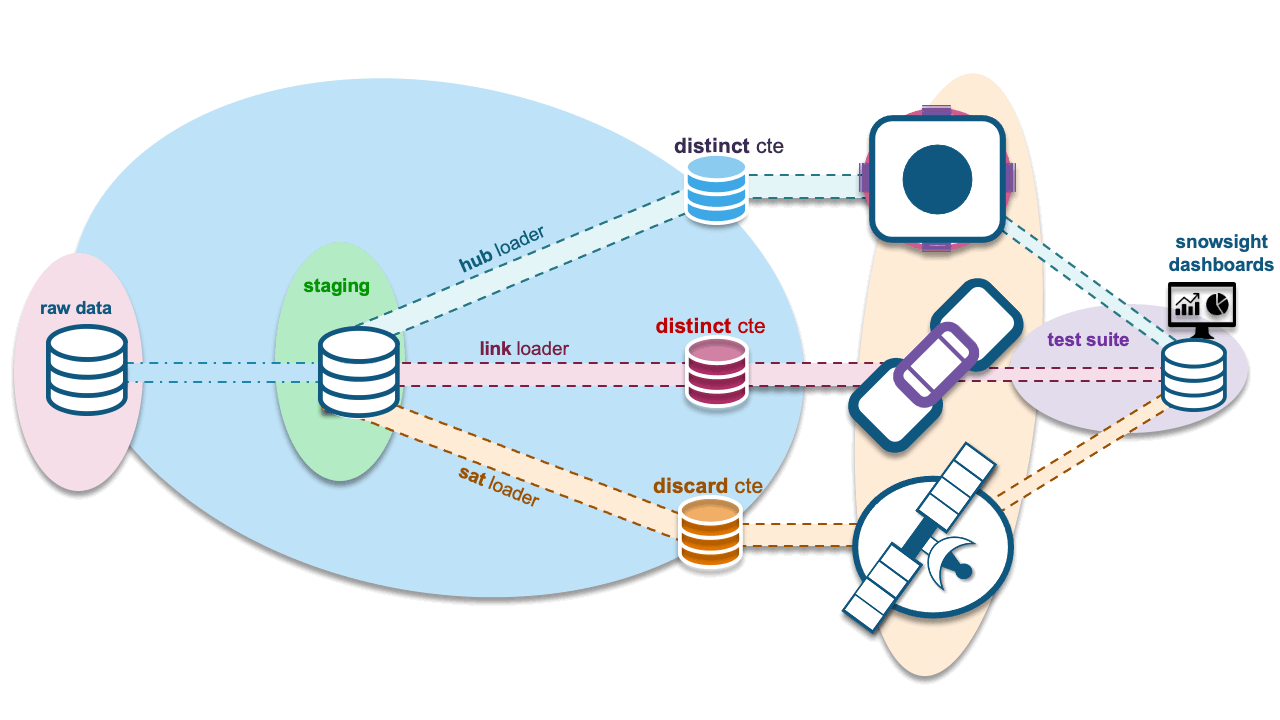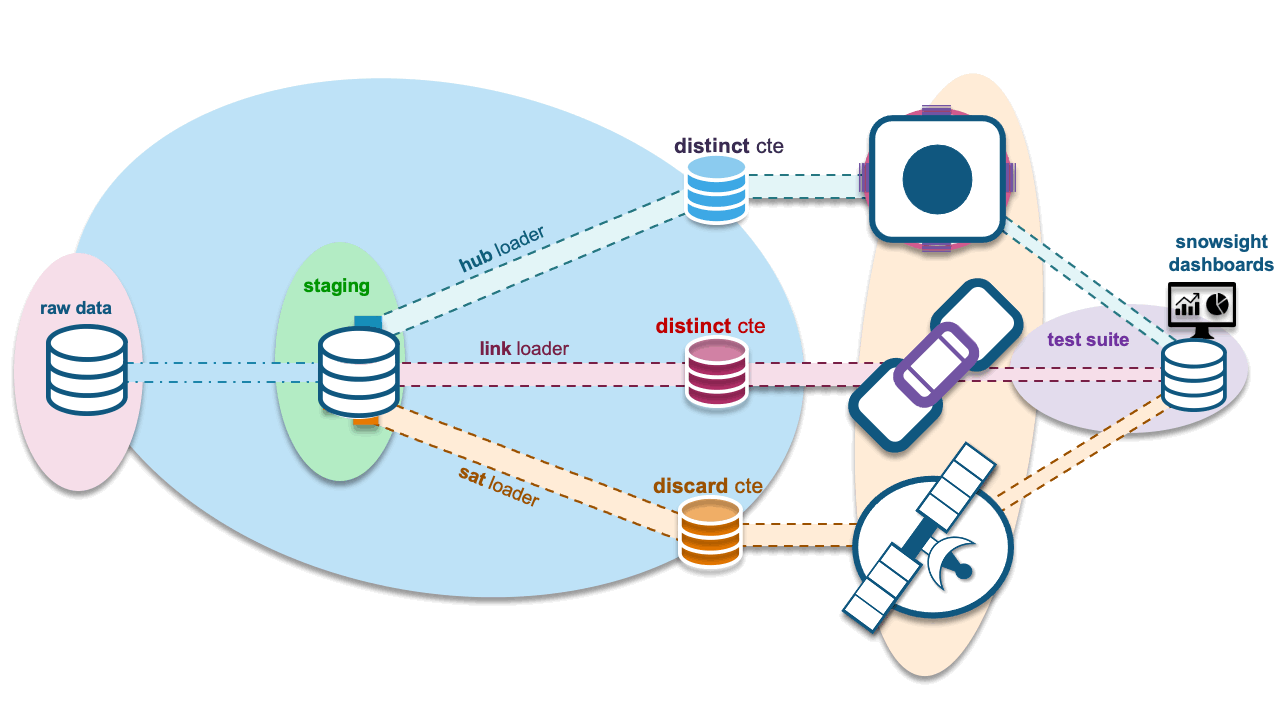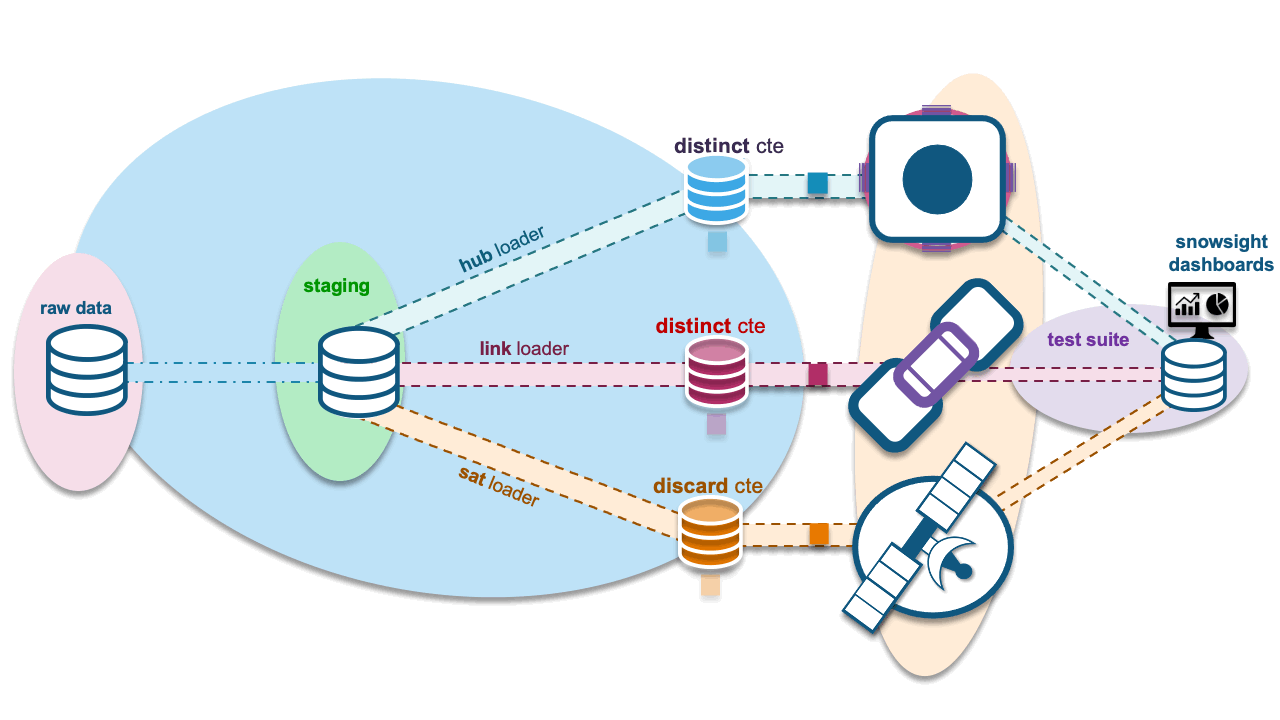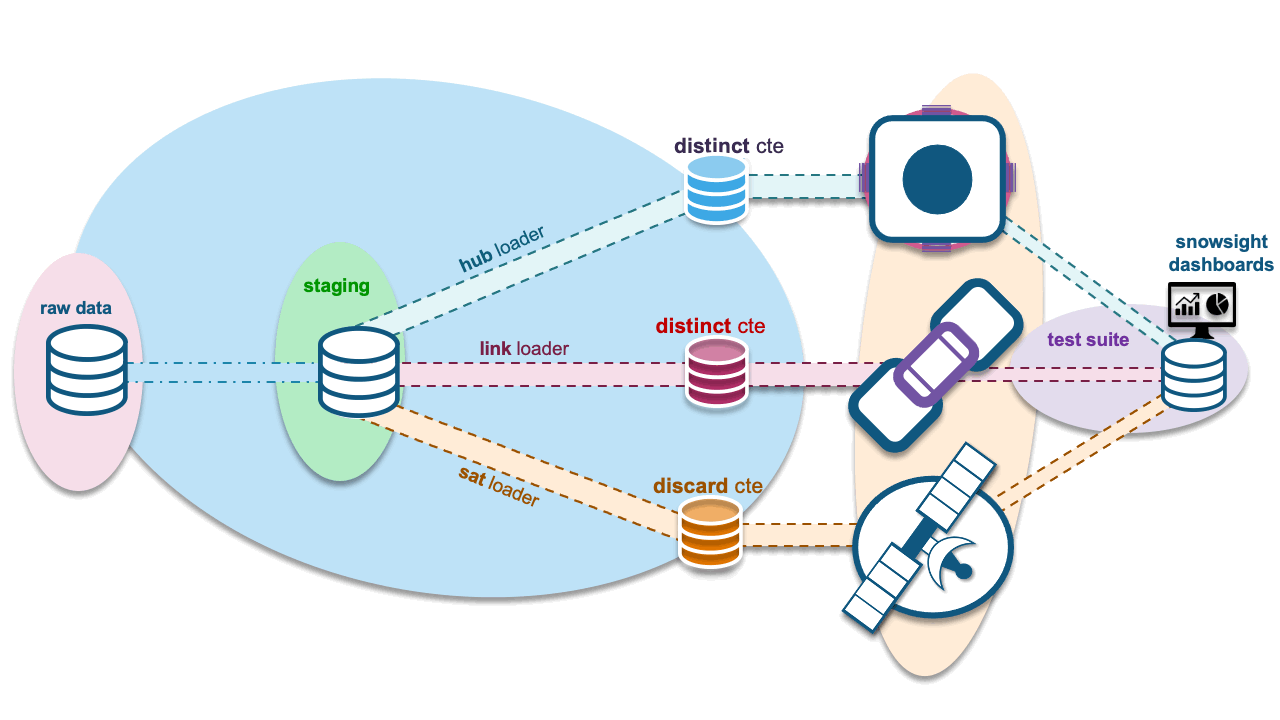
Continuous flow, shedding non-deltas
This all seems very complex, but thankfully it really isn’t. Data Vault only has three table types and therefore only three types of table loaders, and three test patterns per loaded table. The above is a repeatable pattern—it only needs to be configured via parameters once externally and the tasks can be scheduled to run every minute, every five minutes, once a day … you choose. You set the above once and you do not need to use external orchestration and automation tools when everything you need is already in the Snowflake platform.
Some suggested naming patterns for the above Snowflake objects:
- View: stg_${src-badge}_${src-file}
- Stream: str_${src-badge}_${src-file}_to_sat_${sat-name}_${hub-key-name}
- Task: tsk_${src-badge}_${src-file}_to_sat_${sat-name}_${hub-key-name}
Why streams on views?
The answer may surprise you, but it has to do with role-based access control (RBAC) and the scalability offered by applying RBAC to views and tables. Imagine defining a table, and you do not want certain roles to have explicit access to the table itself. Therefore, those roles will not be granted privileges to the tables directly. However, you are prepared to give certain roles privileges, but under the conditions as specified by certain transformations and obfuscations (for example) of the data. You can then define an SQL VIEW over that table and give the role access to the VIEW instead of the table. Optionally, you could secure the transformation itself by deploying the VIEW as a secured VIEW instead, and the role will not have the ability to expose the transformation by issuing a GET_DDL function call. That role does not need explicitly assigned privileges to that table, only the view. The owner of the view would have had privileges to the table in order to define the SQL view.
Snowflake offers the ability to create a VIEW over a table stream, but because the ownership of the table object and the view may differ as described above, applying the stream over a view instead avoids the complexity of ensuring the privileges over the table object (where a stream offset is placed) and SQL view match. Deploying a view over a table stream is therefore an anti-pattern.
The final callout with this pattern is to always design for failure; that is, should an issue occur, be prepared with the operating procedures to reset stream offsets (based on Snowflake Time Travel if you need to).
Lastly, Data Vault satellite table grain is modeled to the understanding of business object state. If a business object can only have one state at any point in time, then that is what this pattern addresses. Do not change the satellite to a multi-active satellite to deal with what could ultimately be a gap in understanding of the data that was modeled, or an error in the process to ingest the data into Snowflake. Also keep in mind that if the target table that was modeled is meant to be a multi-active satellite, then this same proposed framework can be used to load multi-active satellites at any velocity as well.
The dream
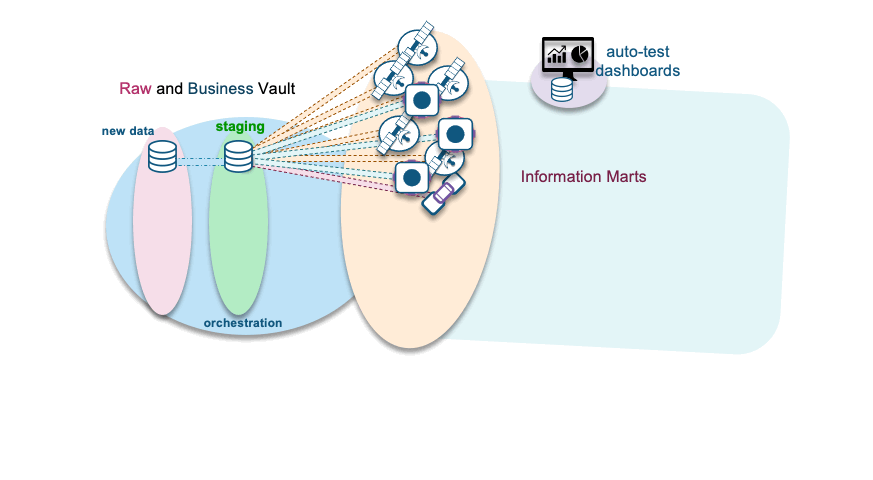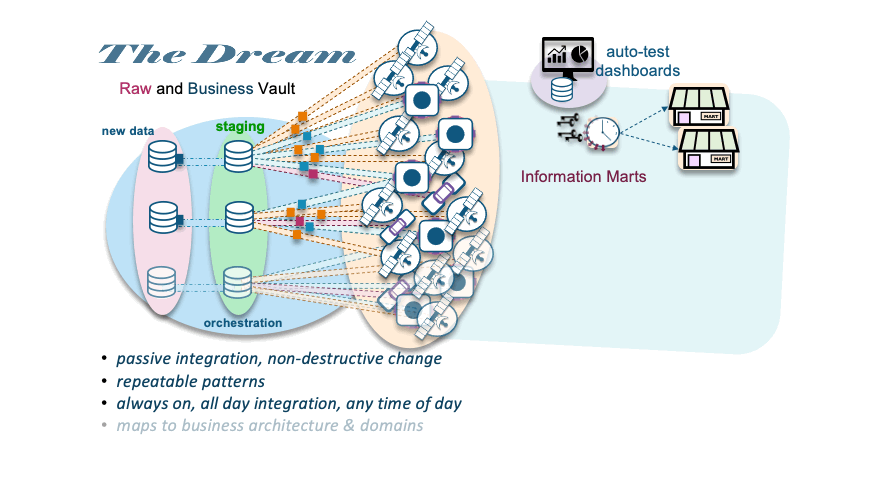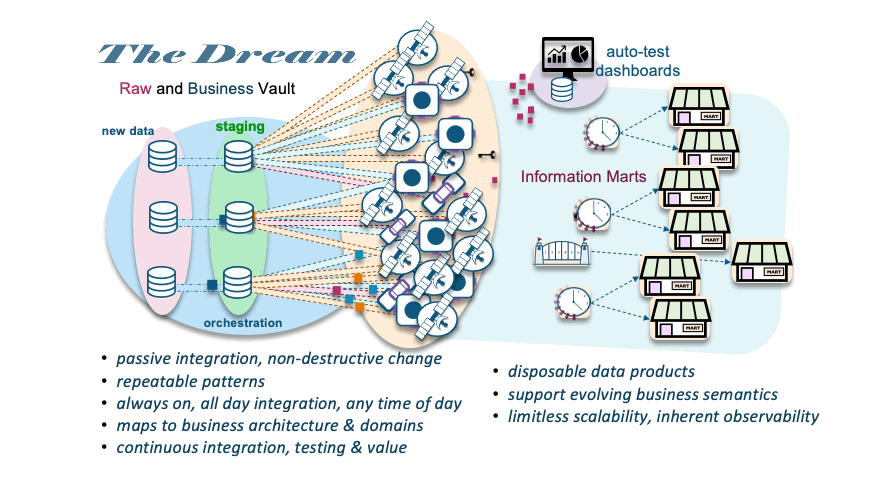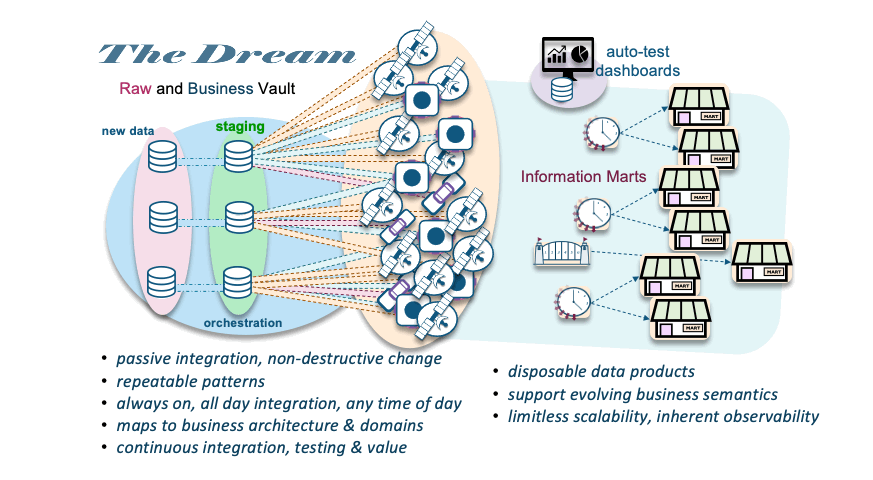
Additional References:
- Introduction to Streams - https://docs.snowflake.com/en/user-guide/streams-intro.html
- Introduction to Tasks - https://docs.snowflake.com/en/user-guide/tasks-intro.html
Authors
