Snowpark Python: Bringing Enterprise-Grade Python Innovation to the Data Cloud

We’re happy to announce that Snowpark for Python is now available in public preview to all Snowflake customers. Python developers can now enjoy the same ease of use, performance, and security benefits of other broadly available Snowpark languages, including Java and Scala, natively integrated into Snowflake’s engine.
In addition to the Snowpark Python API and Python Scalar User Defined Functions (UDFs), as part of the public preview release, we’re thrilled to introduce support for Python UDF Batch API (Vectorized UDFs), Table Functions (UDTFs), and Stored Procedures. These features combined with the Anaconda integration provide the growing Python community of data scientists, data engineers, and developers with a variety of flexible programming contracts and effortless access to open source Python packages to build secure and scalable data pipelines and machine learning (ML) workflows directly within Snowflake.
A quick feature rundown
- Query and process data using familiar syntax with Snowpark Python API
Snowpark is a new developer experience that we’re using to bring deeply integrated, DataFrame-style programming to the languages developers like to use.
Developers can install the Snowpark Python client and use it with their favorite IDEs and development tools of choice to build queries using DataFrames without having to create and pass along SQL strings:
from snowflake.snowpark import Session
from snowflake.snowpark.functions import col
# fetch snowflake connection information
from config import connection_parameters
# build connection to Snowflake
session = Session.builder.configs(connection_parameters).create()
# use Snowpark API to aggregate book sales by year
booksales_df = session.table("sales")
booksales_by_year_df = booksales_df.groupBy(year("sold_time_stamp")).agg([(col("qty"),"count")]).sort("count", ascending=False)
booksales_by_year_df.show()Under the hood, DataFrame operations are transparently converted into SQL queries that get pushed down and benefit from the same high-performance, scalable Snowflake engine you already know! And since the API uses first-class language constructs, you also get support for type checking, IntelliSense, and error reporting from your development environment. As part of the public preview announcement, we’re excited to share that we're open sourcing our Snowpark Python client API. We cannot wait for the Python community to help us expand upon the API, and ultimately make it even better. Check out our Github repository to learn more and to start making contributions.
2. Seamlessly access popular open source packages via the Anaconda integration
While Snowpark allows you to conveniently write DataFrame operations, it is a lot more than just a nicer way to write queries. You can also bring your custom Python logic as UDFs (more on this in a bit), and make use of popular open source packages, pre-installed in Snowflake.
Since the power of Python lies in its rich ecosystem of open source packages, as part of the Snowpark for Python offering we are excited to bring seamless, enterprise-grade open source innovation to the Data Cloud via our Anaconda integration. With Anaconda’s comprehensive set of open source packages and seamless dependency management, you can speed up your Python-based workflows.
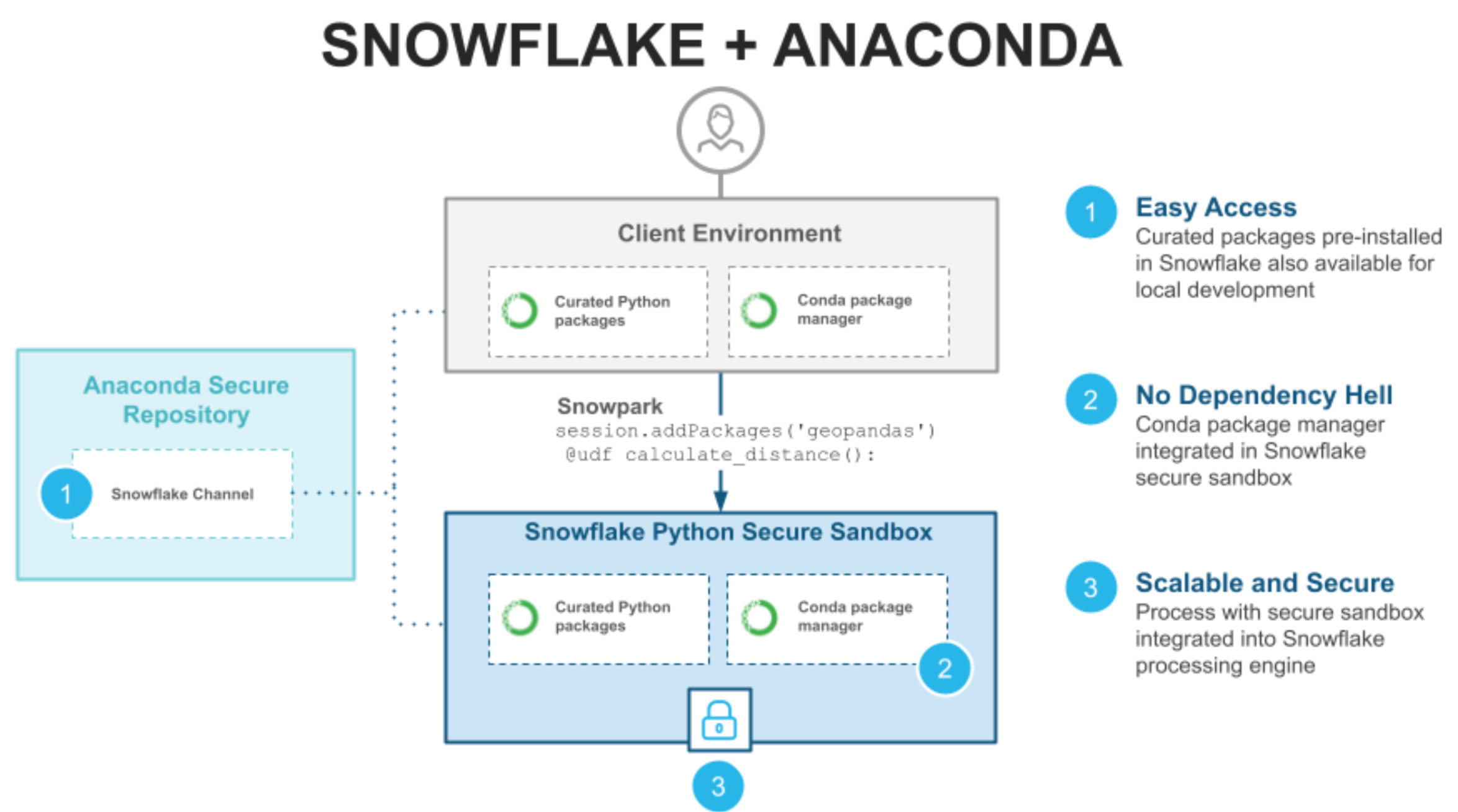
Let me walk you through how you can leverage Anaconda-provided third-party libraries for building your Python workflows:
- Local development: The same set of libraries and versions pre-built in the Snowflake environment are also made available on a Snowflake channel hosted on the Conda repository. When developing locally, you can simply point your local Anaconda installation to the Snowflake channel, which will ensure you are using the same packages and versions available on the Snowflake server side.
- Package management: If your Python function depends on any third-party libraries, you can simply specify which Python packages it needs during UDF declaration. Snowpark will automatically pick up and resolve the dependencies on the server side and install the relevant packages into the Python UDF execution environment using the integrated Conda package manager. With this, you no longer need to spend time resolving dependencies between different packages, eliminating the “dependency hell” that can be a huge time sink.
- Secure and scalable processing: Finally, when the UDF is executed, it is distributed out across Snowflake compute and benefits from the scale and secure processing provided by the Snowflake processing engine.
All of this is made available under Snowflake’s standard consumption-based pricing, with no additional charges for any of the add on features and offerings when used with Snowflake!

“Having the most popular Python libraries—such as NumPy and SciPy—removes another layer of administration from the development process. And with the integrated Conda package manager, there is no need to worry about dependency management.”
—Jim Gradwell, Head of Data Engineering and Machine Learning at HyperGroup
Check out the blog from HyperGroup, to learn more on How HyperFinity Is Streamlining Its Serverless Architecture with Snowpark for Python!
3. Bring along and execute custom code with Python User Defined Functions
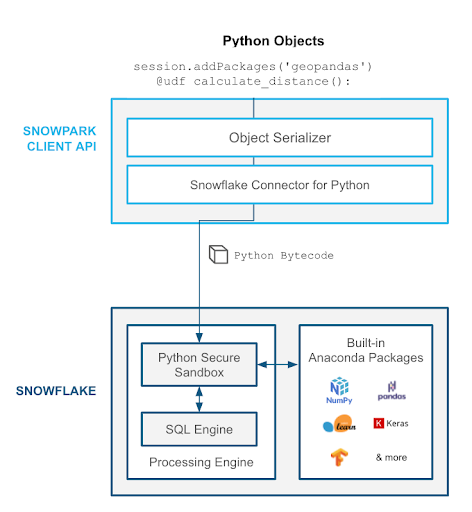
As you might have noted above, Snowpark has the ability to push your custom Python logic into Snowflake, where it can run right next to your data. This is made possible by the secure, sandboxed Python runtime hosted right inside Snowflake’s compute resources. You simply declare that the function is a UDF, and specify any third-party packages your code depends on.
#Given geo-coordinates, UDF to calculate distance between warehouse and shipping locations
from snowflake.snowpark.functions import udf
import geopandas as gpd
from shapely.geometry import Point
@udf(packages=['geopandas'])
def calculate_distance(lat1: float, long1: float, lat2: float, long2: float)-> float:
points_df = gpd.GeoDataFrame({'geometry': [Point(long1, lat1), Point(long2, lat2)]}, crs='EPSG:4326').to_crs('EPSG:3310')
return points_df.distance(points_df.shift()).iloc[1]
# Call function on dataframe containing location coordinates
distance_df = loc_df.select(loc_df.sale_id, loc_df.warehouse_address, loc_df.shipping_address, \
calculate_distance(loc_df.warehouse_lat, loc_df.warehouse_lng, loc_df.shipping_lat, loc_df.shipping_lng) \
.alias('warehouse_to_shipping_distance'))Snowpark takes care of serializing the custom code into Python bytecode, resolves and installs the required dependencies, and pushes down all of the logic to Snowflake. Thus, it runs in a secure sandbox right next to your data. You can call and make use of the UDF as you would with a regular Python function in your DataFrame operations.
Python integration with SQL
As you’ve seen so far, the Snowpark API has the ability to push both DataFrame queries and custom logic into Snowflake. But we also want to make sure that SQL users can get the full benefit of Python functions. To build these functions, when you have something basic to do, you write the code as simple, inline definitions and register the UDF using SQL directly in the Snowflake worksheets.
For more-complex use cases, you can make full use of your existing toolsets—source control, development environments, debugging tools—and develop and test locally. Then you can bring that code to Snowflake. To get it into SQL, all you need to do is package the code as zip files, load it into a Snowflake stage, and specify it as imports when registering it as a Python function. Once the Python UDF is created, any SQL user can use the logic, just as they would any other function, as part of regular queries. This also lets you automate ELT, ML, and CI/CD workflows using Streams and Tasks since Python functions are usable nearly anywhere other functions are used.
Other UDF contracts
In the previous example, we used a scalar UDF, which operates on each row in isolation and produces a single result. While scalar functions are easy to write and address a broad array of problems, additional UDF contracts might come in handy for situations where the scalar contract falls short.
Python UDF Batch API enables defining Python functions that receive batches of input rows as Pandas DataFrames and return batches of results as Pandas arrays or series. Compared to the row-by-row processing pattern with Scalar UDFs, the Batch API provides the potential for better performance, especially if your Python code operates efficiently on batches of rows. In addition to better performance, using the Batch API also means less transformation logic required if you are calling into libraries that operate on Pandas DataFrames or Pandas arrays. As an example, the inference UDF defined below using the Batch API (which loads a pretrained XGBoost model from a stage) has significant performance gains when scoring large tables with a couple of million rows.
–- Using SQL to register a UDF to predict customer propensity score based on historical sales data
create or replace function score_vec(category string, region_code string)
returns double
language python
runtime_version = '3.8'
imports=('@ml_demo/model/model_0_0_0.csv')
packages = ('numpy','pandas','xgboost','scikit-learn')
handler = 'score'
as $$
import pandas as pd
import xgboost as xgb
import sys, pickle, codecs
from _snowflake import vectorized
import_dir = sys._xoptions["snowflake_import_directory"]
with open(import_dir + 'model_0_0_0.csv', 'r') as file:
file_contents = file.read()
pickle_jar = pickle.loads(codecs.decode(file_contents.encode(), "base64"))
bst = pickle_jar[0]
ohe = pickle_jar[1]
bst.set_param('nthread', 1)
@vectorized(input=pd.DataFrame)
def score(features):
dscore = xgb.DMatrix(ohe.transform(features).toarray())
return bst.predict(dscore)
$$;
-- Scoring 20M rows using the Batch API takes about ~8 sec vs ~5 mins for a Scalar UDF on an XL warehouse
select score_vec(category, region_code) from wholesale_customer_salesPython table functions make it possible to return multiple rows for each input row, return a single result for a group of rows, and maintain state across multiple rows that you can’t do with scalar or Batch API. Below is a simple example of how you can use a UDTF and leverage the spaCy library to do named entity recognition. The UDTF takes in a string as input and returns a table of recognized entities and their corresponding labels.
–-UDTF that uses Spacy for named entity recognition
create or replace function entities(input string)
returns table(entity string, label string)
language python
runtime_version = 3.8
handler = 'Entities'
packages = ('spacy==2.3.5')
imports = ('@spacy_stage/spacy_en_core_web_sm.zip')
as $$
import zipfile
import spacy
import os
import sys
import_dir = sys._xoptions["snowflake_import_directory"]
extracted = '/tmp/en_core_web_sm' + str(os.getpid())
with zipfile.ZipFile(import_dir + "spacy_en_core_web_sm.zip", 'r') as zip_ref:
zip_ref.extractall(extracted)
nlp = spacy.load(extracted + "/en_core_web_sm/en_core_web_sm-2.3.1")
class Entities:
def process(self, input):
doc = nlp(input)
for ent in doc.ents:
yield (ent.text, ent.label_)
$$;
select * from table(entities('Hi this is Ryan from Colorado, calling about my missing book from order no 2689.'));
“Protecting our customer environments requires continuous innovation. Sophos has dozens of machine learning models built into our cybersecurity solutions and we roll out additional models all the time. Snowpark for Python enables us to dramatically streamline and scale development and operations of our machine learning models from initial pipeline to the model inference in production.”
—Konstantin Berlin, Sr. Director, AI, Sophos
4. Host and operationalize your code directly in Snowflake using Stored Procedures
As we saw in our previous examples, the Snowpark Python API allows you to write client-side programs to build and run data pipelines using powerful abstractions such as DataFrames. But once you’ve built and tested a pipeline, the next step is to operationalize it. To do that you need to find a home to host and schedule that client program. With Snowpark Python Stored Procedures, you can do exactly that! You can host your Python pipelines directly inside Snowflake, using a Snowflake virtual warehouse as the compute framework, and integrate it with Snowflake features such as Tasks for scheduling. This simplifies the end-to-end story by reducing the number of systems involved and by keeping everything self-contained in Snowflake.
And the best part is that while Snowpark Stored Procedures are incredibly powerful, they’re also very simple to use. Below is a simple example of operationalizing a Snowpark Python pipeline that calculates and applies sales bonuses on a daily basis.
-- Create python stored procedure to host and run the snowpark pipeline to calculate and apply bonuses
create or replace procedure apply_bonuses(sales_table string, bonus_table string)
returns string
language python
runtime_version = '3.8'
packages = ('snowflake-snowpark-python')
handler = 'apply_bonuses'
AS
$$
from snowflake.snowpark.functions import udf, col
from snowflake.snowpark.types import *
def apply_bonuses(session, sales_table, bonus_table):
session.table(sales_table).select(col("rep_id"), col("sales_amount")*0.1).write.save_as_table(bonus_table)
return "SUCCESS"
$$;
--Call stored procedure to apply bonuses
call apply_bonuses('wholesale_sales','bonuses');
– Query bonuses table to see newly applied bonuses
select * from bonuses;
– Create a task to run the pipeline on a daily basis
create or replace task bonus_task
warehouse = 'xs'
schedule = '1440 minuite'
as
call apply_bonuses('wholesale_sales','bonuses');
“Snowpark for Python helps Allegis get ML-powered solutions to market faster while streamlining our architecture. Using Stored Procedures and pre-installed packages, data scientists can run Python code closer to data to take advantage of Snowflake's elastic performance engine.”
—Joe Nolte, AI and MDM Domain Architect, Allegis
Snowpark Accelerated program
We’re also excited by the tremendous interest we’ve seen in our partner ecosystem in building integrations that leverage Snowpark for Python to enhance the experiences they provide to their customers on top of Snowflake.
At the time of this launch, we have dozens of partners in the Snowpark Accelerated program that already have built product integrations and expertise that extend the power of Python in the Data Cloud to their customers.

What’s next?
In the opening keynote at Summit, we also announced a number of other exciting features you can read more extensively about here, that will allow you to do even more with Snowpark for Python, including larger memory warehouses for ML training, native Streamlit integration in Snowflake, and the Native Application Framework for building and deploying applications in the Data Cloud.
Work faster and smarter with Snowpark
Snowpark is all about making it easy for you to do super-impactful things with data, while retaining the simplicity, scalability, and security of Snowflake’s platform. With Snowpark for Python, we cannot wait to see what customers build.
To help you get started, check out these resources:
- Getting Started QuickStart
- Using Snowpark with Streamlit QuickStart
- Advanced ML workflow QuickStart
- Snowpark for Python Examples Repository
And if you want to see Snowpark for Python in action, you can sign up for Snowpark Day.
Happy hacking!
See the latest on Snowpark
Forward Looking Statements
This post contains express and implied forwarding-looking statements, including statements regarding (i) Snowflake’s business strategy, (ii) Snowflake’s products, services, and technology offerings, including those that are under development or not generally available, (iii) market growth, trends, and competitive considerations, and (iv) the integration, interoperability, and availability of Snowflake’s products with and on third-party platforms. These forward-looking statements are subject to a number of risks, uncertainties and assumptions, including those described under the heading “Risk Factors” and elsewhere in the Quarterly Reports on Form 10-Q and the Annual Reports on Form 10-K that Snowflake files with the Securities and Exchange Commission. In light of these risks, uncertainties, and assumptions, actual results could differ materially and adversely from those anticipated or implied in the forward-looking statements. As a result, you should not rely on any forwarding-looking statements as predictions of future events.
© 2022 Snowflake Inc. All rights reserved. Snowflake, the Snowflake logo, and all other Snowflake product, feature and service names mentioned herein are registered trademarks or trademarks of Snowflake Inc. in the United States and other countries. All other brand names or logos mentioned or used herein are for identification purposes only and may be the trademarks of their respective holder(s). Snowflake may not be associated with, or be sponsored or endorsed by, any such holder(s).
Authors
