Snowflake Simplifies Data Architecture, Data Governance and Security to Accelerate Value Across All Workloads

It’s easy these days for an organization’s data infrastructure to begin looking like a maze, with an accumulation of point solutions here and there. While some businesses find ways to stitch together many tools with complex pipelines, wouldn’t it be better if you could remove some of the steps? What if you could streamline your efforts while still building an architecture that best fits your business and technology needs?
Snowflake is committed to doing just that by continually adding features to help our customers simplify how they architect their data infrastructure. Whether it’s unifying transactional and analytical data with Hybrid Tables, improving governance for an open lakehouse with Snowflake Open Catalog or enhancing threat detection and monitoring with Snowflake Horizon Catalog, Snowflake is reducing the number of moving parts to give customers a fully managed service that just works.
At BUILD 2024, we announced several enhancements and innovations designed to help you build and manage your data architecture on your terms. Here’s a closer look.
Streamline data architecture to accelerate value
For hybrid transactional and analytical use cases, along with streaming and unstructured data, you can build solutions with Snowflake that require fewer moving parts, which means you can spend less time and money on manual configurations and silo management and instead route those resources into innovating new ways of putting data to use.
Unify transactional and analytical workloads in Snowflake for greater simplicity
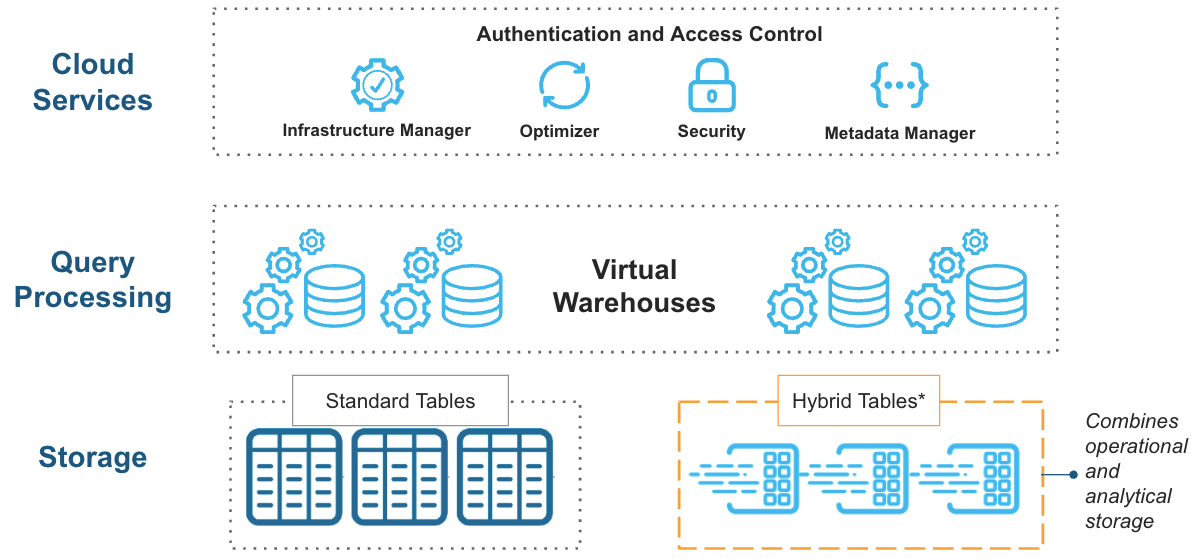
Many businesses must maintain two separate databases: one to handle transactional workloads and another for analytical workloads. Snowflake Unistore consolidates both into a single database so users get a drastically simplified architecture with less data movement and consistent security and governance controls.
Unistore is made possible by Hybrid Tables (now generally available on AWS commercial regions), which enables fast, single-row reads and writes in order to support transactional workloads. With Hybrid Tables’ fast, high-concurrency point operations, you can store application and workflow state directly in Snowflake, serve data without reverse ETL and build lightweight transactional apps while maintaining a single governance and security model for both transactional and analytical data — all on one platform.
Ingest data more efficiently and manage costs
For data managed by Snowflake, we are introducing features that help you access data easily and cost-effectively. With Snowpipe for Apache Kafka (public preview soon in AWS and Microsoft Azure), a “pull” mechanism, rather than the existing “push” connector, allows you to extract and ingest Apache Kafka events into your Snowflake account directly without hosting your own Kafka Connect cluster. This reduces the overall complexity of getting streaming data ready to use: Simply create external access integration with your existing Kafka solution.
SnowConvert is an easy-to-use code conversion tool that accelerates legacy relational database management system (RDBMS) migrations to Snowflake. In addition to free assessments and free table conversions, SnowConvert now supports accurate conversion of database views from Teradata, Oracle or SQL Server for free.
New storage lifecycle policies (private preview) provide another opportunity to cut costs by automatically deleting records or archiving them to a low-cost tier when matching your custom policy condition. This helps you optimize storage while maintaining regulatory compliance in an easy, scalable way.
Unlock value of unstructured documents with AI-enabled automated data extraction and integration
Businesses of all kinds are flooded with documents every day — invoices, receipts, notices, forms and more — and yet getting and using the information therein remains manual, time-consuming and error-prone. With Document AI (generally available on AWS and Microsoft Azure), a fully managed Snowflake workflow that transforms unstructured documents into structured tables using a built-in LLM, Arctic-TILT, you can process documents intelligently and at scale. With the option to fine-tune through an easy-to-use UI, business users and subject matter experts with no AI expertise can be heavily involved in creating and refining models before calling data engineers to operationalize pipelines. Florida State University has been using Document AI to efficiently extract data from PDFs and third-party sources, which simplifies data auditing and eliminates weeks’ worth of manual effort.
Better protect and understand your accounts and data assets with Snowflake Horizon Catalog
Among Snowflake’s greatest benefits are the industry-leading, built-in compliance, security, privacy, discovery and collaboration capabilities that are part of the Horizon Catalog. These help protect and preserve the privacy of your account, users and data assets. We are constantly enhancing our platform to help our customers stay on top of potential threats.
Prevent threats before they occur with enhanced security features and Trust Center innovations
In another key step toward eliminating password-only sign-ins, Snowflake is enforcing multi-factor authentication (MFA) by default for all newly created human users in any Snowflake account. We are also enabling Leaked Password Protection (generally available soon), which will verify and automatically disable user passwords discovered on the dark web. This provides built-in protection against leaked passwords and helps limit the potential for data exfiltration. Compromised users can contact account administrators to reset their passwords.
For API authentication, Snowflake supports developer-friendly, versatile Programmatic Access Tokens (in private preview soon) to simplify the developer experience for application access while enhancing security by including scope and expiration for such tokens. And new Outbound Private Link Connectivity (External Access is generally available on AWS and Azure; External Stage is in public preview on Azure and public preview soon on AWS; External Function is generally available on Azure) connects to external services for cloud service providers and keeps data traffic always within the CSP network, never traversing to the public internet, to minimize the risk of data exposure and other cyberthreats.
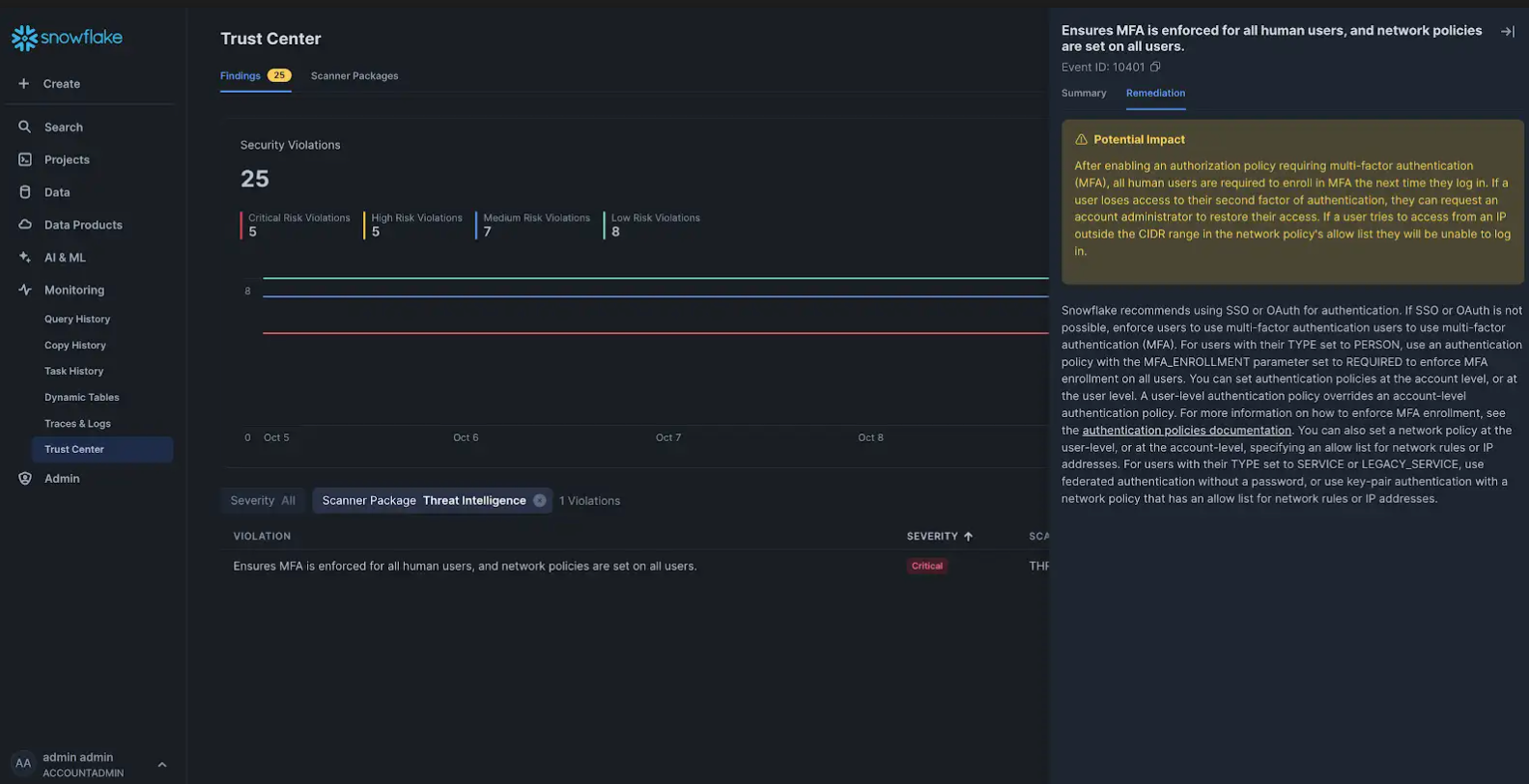
Enhancements to Trust Center, an interface that helps you assess and monitor your Snowflake account's security posture, include a new Threat Intelligence Scanner Package (generally available) to detect which users — either human or service — pose a risk, with clear mitigation on how to address those vulnerabilities. Looking to the future, Trust Center Extensibility (private preview soon) will allow customers to add custom scanner packages to Trust Center from our partners, which are available as Snowflake Native Apps in Snowflake Marketplace.
Implement better data governance by easily tracking and handling sensitive data
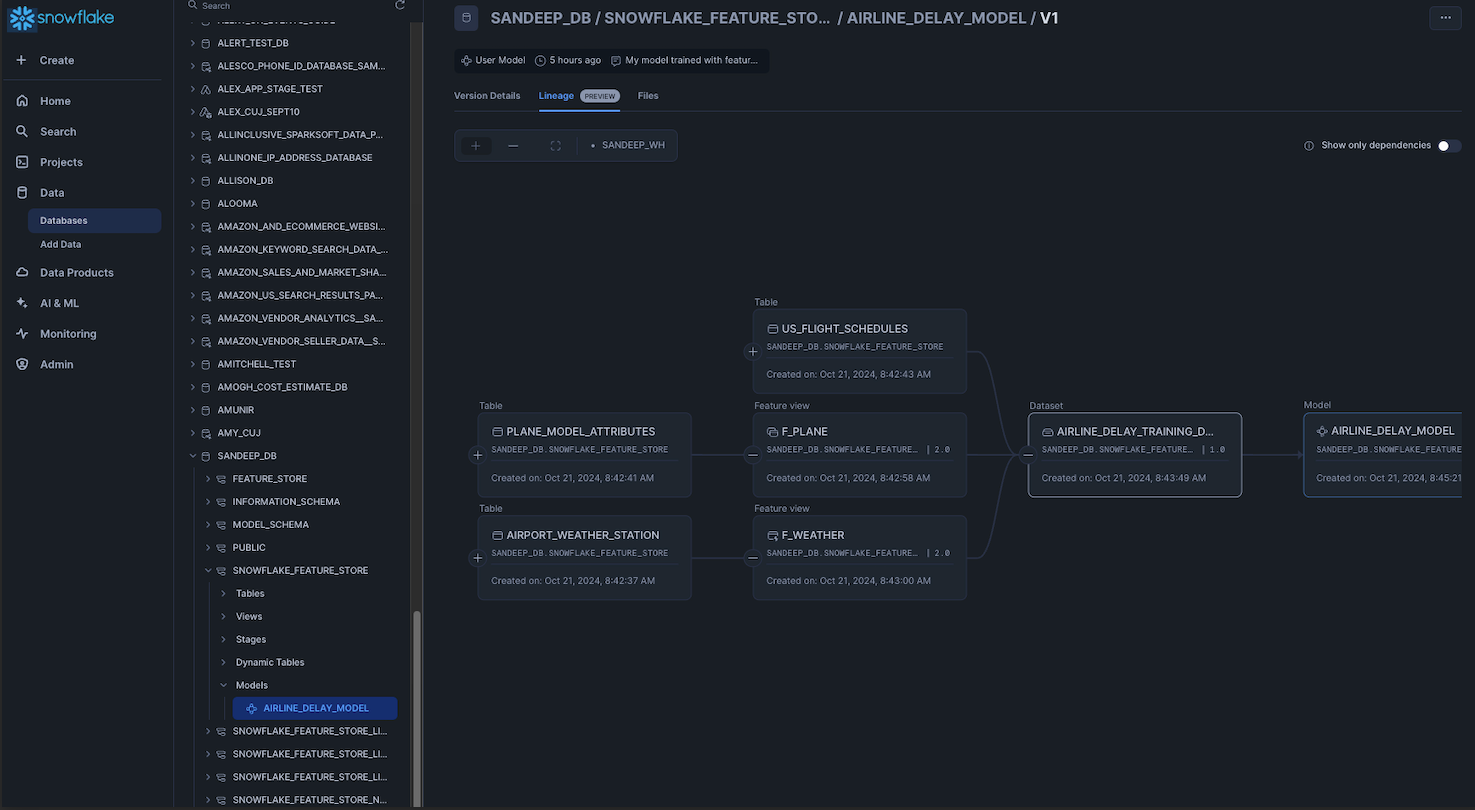
The Lineage Visualization Interface (public preview) allows customers to easily track the flow of data and ML assets with an interactive interface in Snowsight. For data assets, customers can easily see how downstream objects may be impacted by modifications that happen upstream. In addition, governors can take bulk action to propagate tags and policies to protect downstream columns. For ML assets, customers can trace end-to-end feature and model lineage from data to insight for reproducibility, stronger compliance and simplified observability.
Users can also easily automate classification, tagging and masking of sensitive data in any schema with Sensitive Data Auto-Classification (public preview soon) through out-of-the-box classifiers or custom classifiers created using SQL.
Sensitive data can have enormous value but is oftentimes locked down due to privacy requirements. What if you could allow more people access to collaborate with the data, extending the breadth and depth of sensitive data that can be analyzed? Snowflake makes this possible with differential privacy policies (generally available), which reduce risk of identification or re-engineering of sensitive data, and synthetic data generation (public preview), which uses original production data to create a close replica for testing and analysis.
A new view for organization-wide access history (public preview soon) gives data stewards and governors who share sensitive data across accounts within the same organization a centralized record of who accessed which sensitive data, making it simpler to generate audit reports and provide the granular visibility needed to demonstrate compliance with regulatory requirements. Data stewards can also set up Request for Access (private preview) by setting a new visibility property on objects along with contact details so the right person can easily be reached to grant access.
Simplify data engineering and data governance in an open lakehouse
From ingestion and integration to transformation and security, the process of managing a data lake can be overwhelming and costly. For organizations with lakehouse architectures, Snowflake has developed features that simplify the experience of building pipelines and securing data lakehouses with Apache Iceberg™, the leading open source table format.
Simplify bronze and silver pipelines for Apache Iceberg
We are making it even easier to use Iceberg tables with Snowflake at every stage.
For data ingestion, you can use Snowpipe Streaming to load streaming data into Iceberg tables cost-effectively with either an SDK (generally available) or a push-based Kafka Connector (public preview). For batch and microbatch use cases adding Iceberg into existing data lakes, we’re introducing new load modes to COPY and Snowpipe (generally available) that add Apache Parquet files to Iceberg tables as-is without rewriting files. Previously known as Parquet Direct during the private preview stage, this new parameter for COPY and Snowpipe helps you improve performance of legacy data lakes while lowering switching costs. Snowflake’s Delta Lake Direct (public preview) allows you to access your Delta Lake tables as Iceberg tables for “bronze” and “silver” layers without all of the requirements of Universal Format (UniForm). Support for auto-refresh and Iceberg metadata generation is coming soon to Delta Lake Direct.
While there are other tools in the Iceberg ecosystem that support change data capture (CDC) pipelines, they entail orchestration complexity in order to meet freshness requirements. Snowflake’s Dynamic Apache Iceberg Tables (generally available this week) substantially simplify CDC pipelines for Iceberg with a declarative approach: Write the query of the desired result, specify a lag, and let Snowflake handle the rest. In private preview soon, you can use Iceberg tables from external catalogs as the source for Dynamic Iceberg Tables. While Snowpark Python has supported reading from and writing to Iceberg tables, you can also now create Iceberg tables with Snowpark Python (generally available). Lastly, you can clone Iceberg tables (public preview) without duplicating storage, allowing you to experiment with Iceberg tables safely and cost-effectively during testing and development.
Integrating Snowflake and Iceberg tables into your data lakehouse is made simpler with a bevy of tools, including support for writing to Microsoft Fabric OneLake (public preview) as the storage location. Use this step-by-step quickstart guide to see how joint customers can now utilize both platforms on a single copy of data, which can help reduce storage and pipeline costs. Snowflake also allows users to easily query Iceberg tables from any Iceberg REST catalog (generally available) or any externally managed Iceberg tables that use merge-on-read (private preview). To help ensure that you are querying the latest versions of your tables, you can add an auto-refresh setting (generally available soon) to your Iceberg table and catalog integration definitions in SQL.
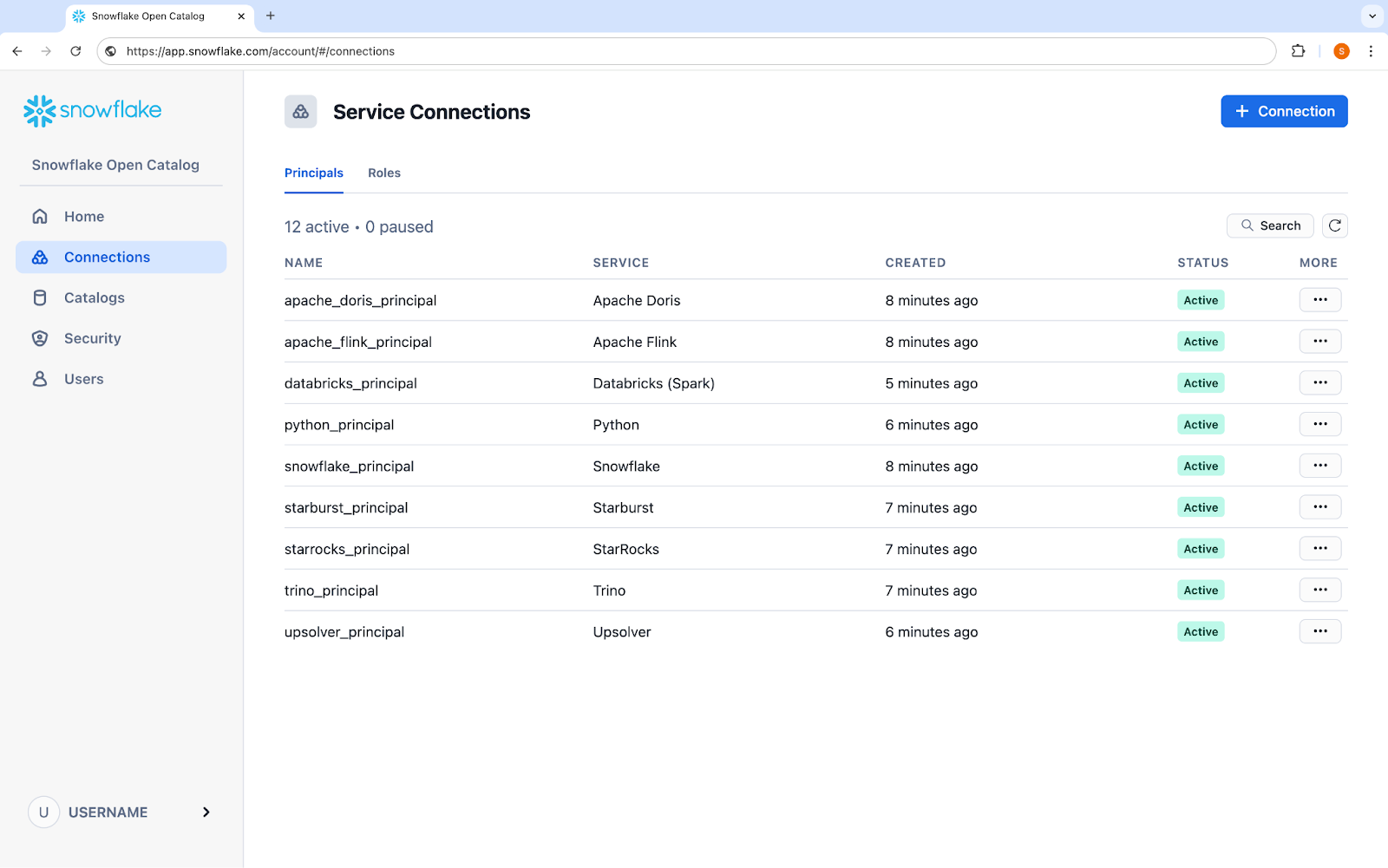
Easily and securely collaborate with Snowflake Open Catalog, a Snowflake managed service for Apache Polaris
In July 2024, Snowflake open sourced a catalog for Apache Iceberg, now known as Apache Polaris™ (incubating), that allows interoperability across many engines on a single copy of data, without superfluous data copies or movement. Snowflake Open Catalog, a fully managed service for Apache Polaris, is now generally available, giving users all of the benefits of Polaris — no vendor lock-in, flexibility of engines, cross-engine security — along with the reliability, security, scalability and support that make it easy to get started and secure to use. Teams in your organization can now collaborate on data lakes in a secure manner with consistent access controls for many engines — readers and writers — such as Apache Flink™, Apache Spark™, Presto and Trino.
To further support collaboration and business continuity, we have also introduced Iceberg support to features like replication (private) and cross-cloud auto-fulfillment (private preview). You can replicate Snowflake-managed Iceberg tables from source to target account(s) with your own object storage by adding its parent database and external volume to a failover group. And by simply configuring a listing containing a Snowflake-managed Iceberg table to be available in multiple regions, customers can share these tables with consumers in other clouds and regions.
Learn more
Data architecture doesn’t have to be a labyrinth of point solutions that not only bog down productivity but threaten security and governance. With these improvements to our unified platform, Snowflake aims to further simplify the complex while still providing flexibility for allowing customers to build architectures that best suit their needs.
To learn more about these announcements and how Snowflake helps organizations use data on their terms, don’t miss the opening keynote of BUILD 2024 or the What’s New sessions:
Author
