Accelerate Your Machine Learning Workflows in Snowflake with Snowpark ML

Many developers and enterprises looking to use machine learning (ML) to generate insights from data get bogged down by operational complexity. We have been making it easier and faster to build and manage ML models with Snowpark ML, the Python library and underlying infrastructure for end-to-end ML workflows in Snowflake. With Snowpark ML, data scientists and ML engineers can use familiar Python frameworks for preprocessing and feature engineering as well as training models that can be managed and executed entirely in Snowflake without any data movement, silos or governance trade-offs. Many customers have already seen the performance benefits of Snowpark ML, including Fidelity, Spark New Zealand, and Swire Coca Cola, USA.
To further accelerate ML use cases for Snowflake customers, we are thrilled to announce that Snowpark ML Modeling for model development is now generally available, and Snowpark Model Registry for model management is in public preview.
Snowpark ML Modeling: Feature engineering, preprocessing and model training
The Snowpark ML Modeling API enables the use of popular Python ML frameworks, such as scikit-learn and XGBoost, for feature engineering and model training without the need to move data out of Snowflake.
Benefits of Snowpark ML Modeling:
- Feature engineering and preprocessing: Improve performance and scalability with distributed execution for common scikit-learn preprocessing functions.
- Model training: Accelerate model training for scikit-learn, XGBoost and LightGBM models without the need to manually create stored procedures or user-defined functions (UDFs), and leverage distributed hyperparameter optimization (now in public preview).
Behind the scenes, Snowpark ML parallelizes data processing operations by taking advantage of Snowflake’s scalable computing platform.
# import packages
from snowflake.ml.modeling.xgboost import XGBRegressor
# create test and training dataframe
train_df, test_df = session.table(input_tbl).drop('ROW').random_split(weights=[0.9, 0.1], seed=0)
# define feature and label columns
CATEGORICAL_COLUMNS = ["CUT", "COLOR", "CLARITY"]
CATEGORICAL_COLUMNS_OE = ["CUT_OE", "COLOR_OE", "CLARITY_OE"]
NUMERICAL_COLUMNS = ["CARAT", "DEPTH", "TABLE_PCT", "X", "Y", "Z"]
LABEL_COLUMNS = ["PRICE"]
OUTPUT_COLUMNS = ["PREDICTED_PRICE"]
# train and test xgboost regression model
regressor = XGBRegressor(
input_cols = CATEGORICAL_COLUMNS_OE + NUMERICAL_COLUMNS,
label_cols = LABEL_COLUMNS,
output_cols = OUTPUT_COLUMNS
)
regressor.fit(train_df)
result = regressor.predict(test_df)
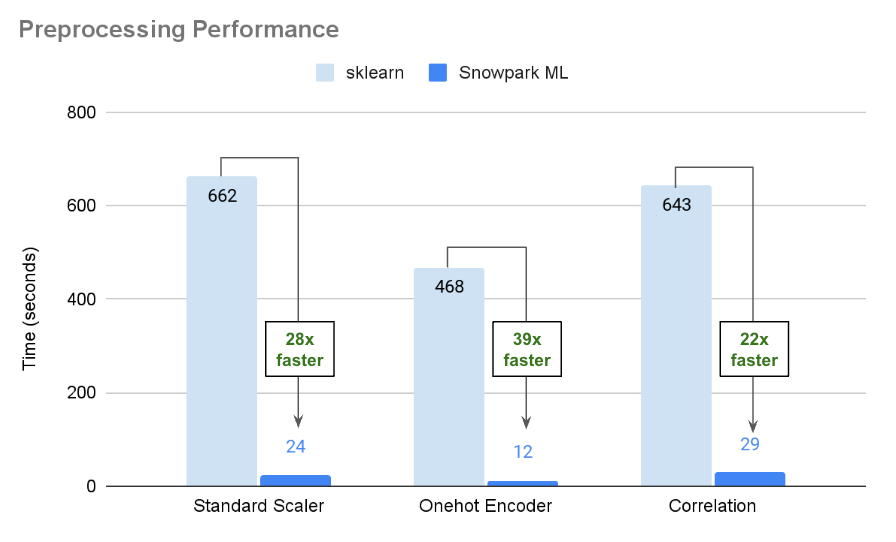
Snowpark ML Modeling API provides performant and scalable distributed implementations of many common preprocessing functions. Internal benchmarks on a large data set show significant speedup achievable compared to running with data transformation functions such as StandardScaler and OneHotEncoder and on compute-intensive data processing such as pairwise-correlation.
Snowpark ML also provides distributed execution of hyperparameter optimization using scikit-learn’s GridSearchCV and RandomSearchCV to accelerate model development on both single node and multiple-node warehouses.
In addition to these custom implementations, Snowpark ML provides coverage for the majority of scikit-learn, XGBoost, and LightGBM algorithms by providing built-in wrappers for these classes that run in Snowflake. This simplifies the model development workflow by abstracting away the manual creation of stored procedures and UDFs to bring these Python libraries into Snowflake.
Snowpark ML Operations: Model management
The path to production from model development starts with model management, which is the ability to track versioned model artifacts and metadata in a scalable, governed manner. For Snowpark ML Operations, the Snowpark Model Registry allows customers to securely manage and execute models in Snowflake, regardless of origin.
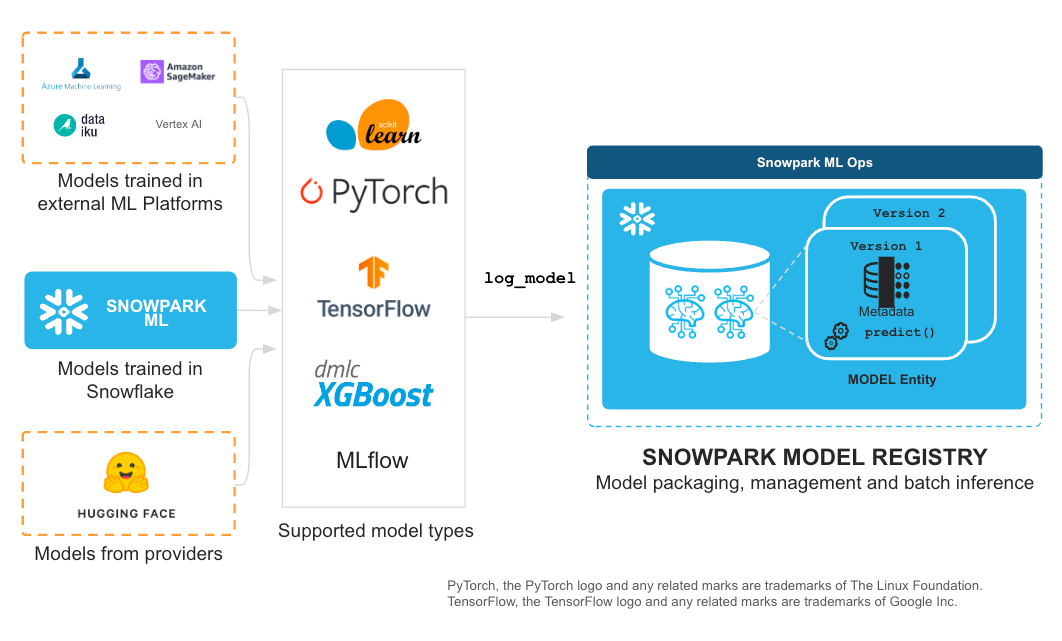
Snowpark Model Registry and the MODEL object
The foundation of Snowpark Model Registry is a new MODEL entity, which allows users to register, manage and use several types of ML models created both within and outside Snowflake. This is a first-class, schema-level Snowflake object that provides a versioned container of ML model artifacts with full role-based access control (RBAC) support, and APIs for Python and SQL.
Through a simple, uniform log_model interface, users can register several model types for management in Snowflake, including:
- Scikit-learn
- Snowpark ML Modeling
- XGBoost
- Pytorch
- Tensorflow
- MLFlow (any model flavor in MLFlow that supports the pyfunc interface)
- HuggingFace pipelines
For all the above supported model types, log_model provides sensible defaults but can be configured with framework-specific parameters as well at the time of model registration.
Here’s an illustration of how to register a scikit-learn model:
from sklearn import datasets, ensemble
iris_X, iris_y = datasets.load_iris(return_X_y=True, as_frame=True)
model = ensemble.RandomForestClassifier(random_state=42)
model.fit(iris_X, iris_y)
model_verson = registry.log_model(
model_name="RandomForestClassifier",
model_version="v1",
model=model,
sample_input_data=iris_X,
)In addition to using Python with the Snowpark Model Registry, users can use SQL to perform basic catalog operations on ML models.
Using the Snowpark Model Registry, multiple model artifacts representing different versions of a model can now be managed in Snowflake as a single logical unit (that is, a single MODEL instance), along with structured metadata and model metrics from training. The Snowpark Model Registry API provides simple catalog and retrieval operations on models.
from snowflake.ml.registry import registry
registry = registry.Registry(session, database_name='my_db', schema_name='schema_name')
#List models in the registry
registry.show_models()
#Retrieve an existing model from registry by name
model = registry.get_model(model_name)
#Delete an existing model from the registry, together with all its versions
registry.delete_model(model_name)Model management operations
Within the new MODEL entity, model artifacts are stored as versioned objects, with each version capable of storing metadata and metrics, and version-specific functions (for example, predict or complete). This allows users to logically organize their models specific to a use case or project in a single entity, while also eliminating the need to create standalone UDFs for the purpose of inference.
#Show all model versions
model.show_versions()
#Retrieve an existing version by name
model_verson = model.version(version_name)
#Set a specific model version as default
model.default = version_nameUsers can also provide and manage structured metadata at the level of both models and versions. Note that this can also be done at the time a model or version is registered, as part of the Snowpark Model Registry’s log_model API call.
#Metadata can be attached at the version level
model_verson.description = "A SKLearn model for fraud prediction"
#Metrics can also be added and retrieved for each version
model_verson.set_metric(metric_name="confusion_matrix",value=test_confusion_matrix.tolist())
model_verson.get_metric(metric_name="confusion_matrix")
model_verson.delete_metric(metric_name="confusion_matrix")
model_verson.show_metrics()Inference
The new MODEL entity enables batch inference use cases through its native function support, and eliminates the need to create and manage UDFs specifically for inference.
A model version can have multiple prediction functions (for example, predict() and predict_proba()) and users can interact with them directly.
#Use the model for inference
model_verson=registry.get_model(model_name='RandomForestClassifier', version='Model version abcd').
#Model versions can have multiple functions associated with them
model_verson.show_functions()
#The most commonly used one is likely the predict function from each framework
remote_prediction = model_verson.run(test_features, function_name="predict")
model_verson.run(data=iris_X[-10:], function_name='predict_proba')Equivalently, models can also be run against data from a table in SQL.
-- Call a model function against its default version
SELECT my_model!predict_proba(c1, c2, c3) FROM t;Please refer to the Snowpark Model Registry documentation for additional details, and code examples for each supported model type.
Success stories
Using Snowpark ML’s capabilities, many Snowflake customers and partners have already started deriving real value from Snowpark ML’s capabilities for their AI/ML workflows.
Spark New Zealand, a telecommunications and digital services company, utilizes Snowpark ML to better understand its customers’ needs and preferences for Skinny Mobile, a prepay mobile provider.
“Skinny Mobile, a division of Spark New Zealand, has adopted an end-to-end Snowflake unified analytics platform that ingests over a billion rows of data daily,” says Eric Bonhomme, Cloud Architect and Product Owner at Spark New Zealand. “The platform includes Snowpark ML to train machine learning models and run inference using Snowflake’s compute power. Using Snowpark ML alongside Snowpark Optimized Warehouses has streamlined the model development and operations process—eliminating long-running queries and unnecessary data transfers, and enhancing efficiency, security and data governance resulting in cost and time savings."
In addition to customers, many partners have seen the benefits of Snowpark ML and have built integrations with it, including Astronomer, Dataiku, Fosfor, Hex and Infostrux.
Fosfor is a Snowflake partner that has integrated Snowpark ML with Refract, an enterprise AI platform that brings together the best AI frameworks and templates to prepare, build, train and deploy ML models.
“At Fosfor, we’ve witnessed firsthand the transformative power of Snowpark ML,” says Gireesh Puthumana, Associate Director at Fosfor. “What truly stands out is its capacity to efficiently scale ML model training and inference on expansive data sets right within Snowflake. This presents an impressive blend of swift training and deployment coupled with impressive compute performance. A familiar experience reminiscent of scikit-learn is simplifying the learning journey of the data scientists. Snowpark ML on Fosfor reaffirms the future of efficient and secure machine learning by driving rapid experimentation and end-to-end model governance while safeguarding data privacy.”
Get started with Snowpark ML
You can learn more about Snowpark ML by referencing our developer documentation and jumping into our step-by-step quickstart using any IDE of choice, including open source solutions such as Jupyter and VS Code or managed services such as Hex.
Ready to see Snowpark ML in action? Join us at Snowpark Day to check out product demos and attend our webinar to hear how Snowpark ML can easily integrate with your existing AI/ML notebook and platform.
Authors


