SwiftKV von Snowflake AI Research senkt Inferenzkosten von Meta-Llama-LLMs um bis zu 75 % auf Cortex AI
Large Language Models (LLMs) bilden das Fundament der Transformation generativer KI (GenAI) und treiben branchenübergreifend Lösungen voran – von effizienter Kundenbetreuung bis hin zu vereinfachten Datenanalysen. Unternehmen benötigen leistungsstarke, kostengünstige und latenzarme Inferenzen, um ihre GenAI-Lösungen zu skalieren. Die Komplexität und der Rechenaufwand der LLM-Inferenz stellen jedoch eine Herausforderung dar. Inferenzkosten bleiben bei vielen Workloads immens. Hier kommen SwiftKV und Snowflake Cortex AI ins Spiel.
SwiftKV-Optimierungen, die vom Snowflake AI Research-Team entwickelt und in vLLM integriert wurden, verbessern den LLM-Inferenzdurchsatz erheblich und senken so die Kosten. SwiftKV-optimierte Llama 3.3 70B und Llama 3.1 405B-Modelle, die als Snowflake-LLama-3.3-70B und Snowflake-Llama-3.1-405B bezeichnet werden, sind jetzt für die serverlose Inferenz in Cortex AI verfügbar. Die Inferenzkosten sinken dabei um bis zu 75 % im Vergleich zu den Meta-Llama-Basismodellen in Cortex AI, die nicht SwiftKV-optimiert sind. Kunden können auf diese in Cortex AI über die Complete-Funktion zugreifen. Damit Unternehmen ihre KI-Apps auch weiterhin effizient und kostengünstig in Produktion bringen können, überlegen wir, dieselben Optimierungen auch für andere Modellfamilien in Snowflake Cortex AI zu implementieren.
SwiftKV im Überblick
Schauen wir uns an, wie SwiftKV diese Performance erreicht. Unternehmensanwendungsfälle beinhalten oft lange Eingabeaufforderungen mit minimalem Output (fast 10:1). Das bedeutet, dass der Großteil der Rechenressourcen während der Eingabe- (oder Prefill-Phase) der Key-Value-Cache-Erstellung (KV) verbraucht wird. SwiftKV verwendet die versteckten Zustände früherer Transformer-Schichten wieder, um einen KV-Cache für spätere Schichten zu generieren. Dadurch entfallen redundante Berechnungen in der Prefill-Phase und der rechnerische Aufwand wird erheblich reduziert. Dadurch erreicht SwiftKV eine Reduzierung der Prefill-Rechenressourcen um bis zu 50 % bei gleichzeitiger Einhaltung der von Unternehmensanwendungen geforderten Genauigkeit. Diese Optimierung verbessert den Durchsatz und sorgt für einen kostengünstigeren Inferenzstack.
SwiftKV erreicht eine höhere Durchsatzleistung bei minimalem Genauigkeitsverlust (siehe Tabellen 1 und 2). Dies wird durch die Kombination von Parameter Preserving Model Rewiring und leichtem Fine-Tuning erreicht, um die Wahrscheinlichkeit zu minimieren, dass dabei Wissen verloren geht. Durch Selbstdestillation repliziert das „rewired“ Modell das ursprüngliche Verhalten und erreicht dabei nahezu identische Performance. Genauigkeitsverluste sind auf etwa einen Punkt im Durchschnitt mehrerer Benchmarks begrenzt (siehe Tabellen 1 und 2). Dieser chirurgische Optimierungsansatz stellt sicher, dass Unternehmen von der Recheneffizienz von SwiftKV profitieren können, ohne Kompromisse bei der Qualität ihrer GenAI-Ausgaben einzugehen.


Basierend auf unserem Benchmarking übertrifft SwiftKV konstant die Standard-KV-Cache-Implementierungen und traditionellen KV-Cache-Komprimierungsmethoden in realen Produktions-Anwendungsfällen. So erreicht SwiftKV beispielsweise in Produktionsumgebungen mit High-End-GPUs wie NVIDIA H100s einen bis zu zwei Mal höheren Durchsatz (siehe Abbildung 1) für Modelle wie den Llama-3.3-70B. Diese Verbesserungen führen zu einer schnelleren Auftragserfüllung, niedrigeren Latenzzeiten für interaktive Anwendungen (siehe Tabelle 3) und erheblichen Kosteneinsparungen für Unternehmen, die in großem Umfang arbeiten.
Performance nach Anwendungsfall
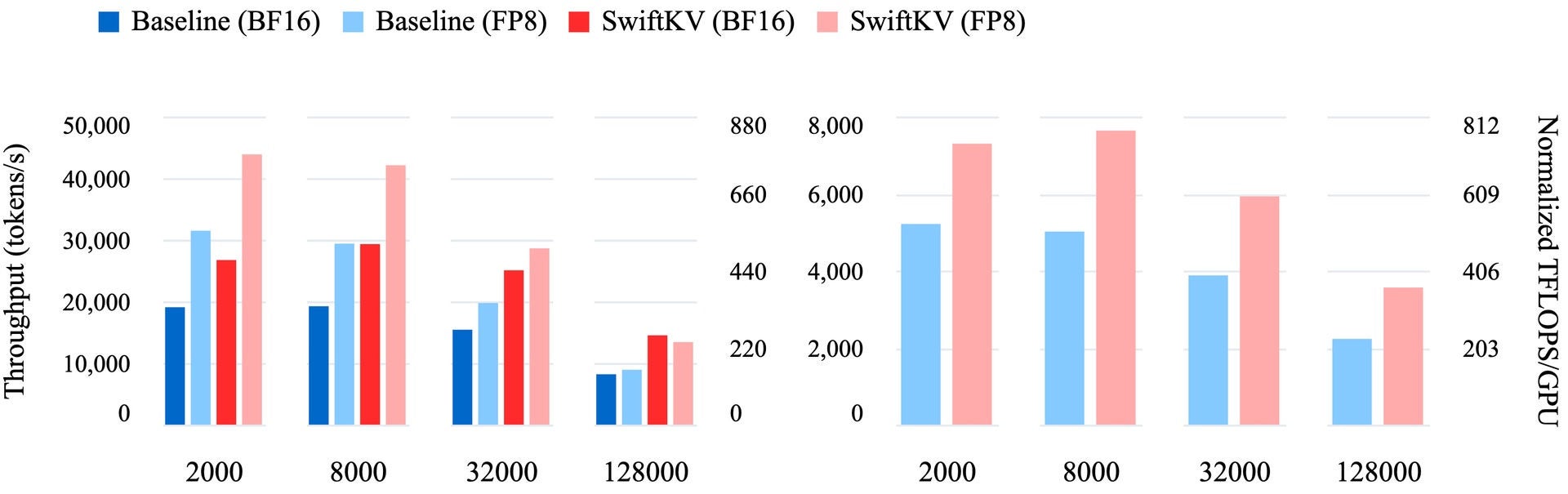
SwiftKV ermöglicht Performance-Optimierungen für eine Reihe von Anwendungsfällen. Bei großen Inferenzaufgaben, wie z. B. der Verarbeitung unstrukturierter Texte (z. B. Zusammenfassung, Übersetzung oder Stimmungsanalyse), verbessert SwiftKV den kombinierten Durchsatz (siehe Abbildung 1), sodass Unternehmen mehr Daten in kürzerer Zeit verarbeiten können. In latenzsensiblen Szenarien, wie z. B. Chatbots oder KI-Assistenten, reduziert SwiftKV die Zeit bis zum ersten Token um bis zu 50 % (siehe Tabelle 4) und sorgt so für eine schnellere und reaktionsschnellere Benutzererfahrung. Darüber hinaus lässt sich SwiftKV ohne größere Änderungen nahtlos mit vLLM integrieren, um eine breite Palette ergänzender Optimierungstechniken zu ermöglichen, darunter Aufmerksamkeitsoptimierung und spekulative Entschlüsselung. Diese Integration macht SwiftKV zu einer vielseitigen und praktischen Lösung für Unternehmens-Workloads.


SwiftKV auf Snowflake Cortex AI
Die Einführung von SwiftKV kommt zu einem entscheidenden Zeitpunkt für Unternehmen, die LLM-Technologien nutzen. Angesichts der wachsenden Zahl von Anwendungsfällen benötigen Unternehmen Lösungen, die sowohl sofortige Performance-Steigerungen als auch langfristige Skalierbarkeit ermöglichen. Indem SwiftKV die Computing-Engpässe bei der Inferenz direkt angeht, bietet es Unternehmen einen neuen Weg nach vorn, das volle Potenzial ihrer LLM-Produktionsbereitstellungen auszuschöpfen. Wir freuen uns, die SwiftKV-Innovation für die Llama-Modelle mit der Markteinführung von Snowflake-Llama-3.3-70B und Snowflake-Llama-3.1-405B mit Inferenz zu einem Bruchteil der Kosten (75 % bzw. 68 % niedrigere Kosten) anbieten zu können. Die von Snowflake abgeleiteten Llama-Modelle sind ein Gamechanger für Unternehmen, die Herausforderungen der Skalierung von GenAI-Innovationen in ihrem Unternehmen einfach und kostengünstig bewältigen möchten.
SwiftKV Open Source
Erste Schritte: Führen Sie ein eigenes SwiftKV-Training durch, indem Sie diesem Quickstart folgen.
Da SwiftKV vollständig Open Source ist, können Sie es auch selbst bereitstellen, mit Modell-Checkpoints auf Hugging Face und optimierter Inferenz auf vLLM. Weitere Informationen finden Sie in unserem SwiftKV-Forschungsblogbeitrag.
Wir entwickeln auch Wissensdestillations-Pipelines über das ArcticTraining-Framework Open Source, damit Sie Ihre eigenen SwiftKV-Modelle für Ihre Unternehmens- oder akademischen Anforderungen entwickeln können. Das ArcticTraining-Framework ist eine leistungsstarke Bibliothek zur Optimierung von Forschung und Entwicklung. Es soll die Forschung erleichtern und Prototypen für neue Ideen für die Weiterbildung ermöglichen, ohne durch komplexe Abstraktionsebenen oder Generalisierungen überfordert zu werden. Es bietet eine hochwertige, benutzerfreundliche synthetische Datengenerierungs-Pipeline und ein skalierbares, anpassungsfähiges Trainingsframework für algorithmische Innovationen sowie ein gebrauchsfertiges Rezept für das Training Ihrer eigenen SwiftKV-Modelle.
Fazit
GenAI-Innovationen nehmen über Branchen und Anwendungsfälle hinweg immer weiter zu. Optimierungen wie SwiftKV sind also entscheidend, um KI kostengünstig und leistungsfähig an Endnutzende zu bringen. Heute als Open Source verfügbar, macht SwiftKV GenAI auf Unternehmensebene schneller und kostengünstiger auszuführen. Wir gehen jedoch noch einen Schritt weiter und führen außerdem Llama-Modelle ein, optimiert mit SwiftKV in Snowflake Cortex AI. Mit den Modellen Snowflake-Llama-3.3-70B und Snowflake-Llama-3.1-405B erzielen Kunden bis zu 75 % niedrigere Inferenzkosten. Wir helfen ihnen bei der Entwicklung von GenAI-Lösungen, die nicht nur kosteneffizient, sondern auch leistungsstark sind.
Authors




