Part I: Making Schema-on-Read a Reality

(Note: This the the first in a two-part series discussing how we handle semi-structured data in Snowflake)
Schema? I don’t need no stinking schema!
Over the last several years, I have heard this phrase schema-on-read used to explain the benefit of loading semi-structured data into a Big Data platform like Hadoop. The idea being you could delay data modeling and schema design until long after the data was loaded (so as to not slow down getting your data while waiting for those darn data modelers).
Every time I heard it, I thought (and sometimes said) – “but that implies there is a knowable schema.” So really you are just delaying the inevitable need to understand the structure in order to derive some business value from that data. Pay me now or pay me later.
Why delay the pain?
So even though folks are able to quickly load this type of data into Hadoop or NoSQL, there is still more work ahead to actually pull the data apart so it can be analyzed. The person writing the query often has the burden of figuring out the schema and writing code to extract it. Additionally there may be a query performance penalty in this process (over that of querying columns in a relational database).
Not so with the Snowflake Elastic Data Warehouse (#ElasticDW)! With Snowflake, you can load your semi-structured data directly into a relational table, then query the data with a SQL statement, join it to other structured data, all while not fretting about future changes to the “schema” of that data. Snowflake actually keeps track of the self-describing schema so you don’t have to. No ETL or fancy shredding required.
One of the key differentiators which really attracted me to Snowflake is our built in support to load and query semi-structured data such as JSON, XML, and AVRO. In most conventional data warehouse and Big Data environments today, you have to first load this type of data to a Hadoop or NoSQL platform, then shred it (using for example MapReduce) in order to then load it into columns in a relational database (that is if you want to then run SQL queries or a BI/Analytics tool against that data).
How did we do it?
Simple – we invented a new data type called VARIANT that allows us to load semi-structured data (i.e., flexible schema) as-is into a column in a relational table.
Read that again – we load the data directly into a relational table.
Okay, so that means no Hadoop or NoSQL needed in your data warehouse architecture just to hold semi-structured data. Just an RDBMS (in the cloud) that uses SQL that your staff already knows how to write.
But that is only half the equation. Once the data is in, how do you get it out?
Our brilliant founders and excellent engineering team (#DataSuperStars) have created extensions to SQL to reference the internal schema of the data (it is self-describing after all) so you can query the components and join it to columns in other tables as if it had been shredded into a standard relational table. Except there is no coding or shredding required to prep the data. Cool.
That also means that as the data source evolves and changes over time (e.g., new attributes, nesting, or arrays are added), there is no re-coding of ETL (or even ELT) code required to adapt. The VARIANT data type does not care if the schema varies.
What does it really look like?
Enough of the theory – let’s walk through an example of how this all works.
1 - Create a table
I have a Snowflake account, database and virtual warehouse set up already so just like I would in any other db, I simply issue a create table DDL statement:
create or replace table json_demo (v variant);Now I have a table with one column (“v”) with a declared data type of VARIANT.
2 - Load some data
Now I load a sample JSON Document using an INSERT and our PARSE_JSON function. We are not simply loading it as text but rather storing it as an object in the VARIANT data type while at the same time converting it to an optimized columnar format (for when we query it later):
insert into json_demo
select
parse_json(
'{
"fullName": "Johnny Appleseed",
"age": 42,
"gender": "Male",
"phoneNumber": {
"areaCode": "415",
"subscriberNumber": "5551234"
},
"children": [
{ "name": "Jayden", "gender": "Male", "age": "10" },
{ "name": "Emma", "gender": "Female", "age": "8" },
{ "name": "Madelyn", "gender": "Female", "age": "6" }
],
"citiesLived": [
{ "cityName": "London",
"yearsLived": [ "1989", "1993", "1998", "2002" ]
},
{ "cityName": "San Francisco",
"yearsLived": [ "1990", "1993", "1998", "2008" ]
},
{ "cityName": "Portland",
"yearsLived": [ "1993", "1998", "2003", "2005" ]
},
{ "cityName": "Austin",
"yearsLived": [ "1973", "1998", "2001", "2005" ]
}
]
}');3 - Start pulling data out
So let’s start with just getting the name:
select v:fullName from json_demo;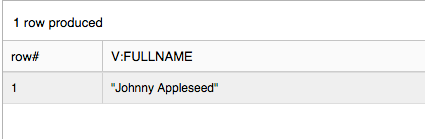
Where:
v = the column name in the json_demo table
fullName = attribute in the JSON schema
v:fullName = notation to indicate which attribute in column “v” we want to select.
So, similar to the table.column notation all SQL people are familiar with, in Snowflake we added the ability to effectively specify a column within the column (i.e., a sub-column) which is dynamically derived based on the schema definition imbedded in the JSON string.
4 - Casting the Data
Usually we don’t want to see the double quotes around the data in the report output (unless we were going to create an extract file of some sort) , so we can format it as a string and give it a nicer column alias (like we would do with a normal column):
select v:fullName::string as full_name
from json_demo;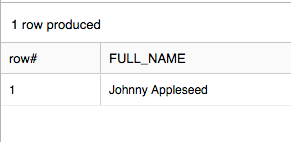
Next let’s look at a bit more of the data using the same syntax from above:
select
v:fullName::string as full_name,
v:age::int as age,
v:gender::string as gender
from json_demo;
Again, simple SQL and the output looks like the results from any table you might have built in your traditional data warehouse.
Safe to say at this point, with what I have already shown you, you could look at a table in Snowflake with a VARIANT column and quickly start “shredding” the JSON with SQL.
How long did that take to learn?
This is why I love Snowflake! I can now query semi-structured data and I did not have to learn a new programming language or framework or whatever over in Big Data land – yet I have the same capabilities as if I did.
Much lower learning curve for sure.
Let’s get a little more complex
Yes, those examples are very simple, so let’s dive deeper. Notice in the original string there is some nesting of the data:
{
"fullName": "Johnny Appleseed",
"age": 42,
"gender": "Male",
"phoneNumber": {
"areaCode": "415",
"subscriberNumber": "5551234"
},
...How do we pull that apart? With a very familiar table.column dot notation:
select
v:phoneNumber.areaCode::string as area_code,
v:phoneNumber.subscriberNumber::string as subscriber_number
from json_demo;So just as fullName, age, and gender are sub-columns, so to is phoneNumber. And subsequently areaCode and subscriberNumber are sub-columns of the sub-column. Not only can we pull apart nested objects like this, you might infer how easily we can adapt if the schema changes and another sub-column is added.
What happens if the structure changes?
Imagine in a subsequent load the provider changed the specification to this:
{
"fullName": "Johnny Appleseed",
"age": 42,
"gender": "Male",
"phoneNumber": {
"areaCode": "415",
"subscriberNumber": "5551234",
"extensionNumber": "24"
},
...They added a new attribute (extensionNumber)! What happens to the load?
Nothing – it keeps working because we ingest the string into the VARIANT column in the table.
What about the ETL code?
What ETL code? There is no ETL so there is nothing to break.
What about existing reports?
They keep working too. The previous query will work fine. If you want to see the new column, then the SQL needs to be refactored to account for the change:
select
v:phoneNumber.areaCode::string as area_code,
v:phoneNumber.subscriberNumber::string as subscriber_number,
v:phoneNumber.extensionNumber::string as extension_number
from json_demo;In addition, if the reverse happens and an attribute is dropped, the query will not fail. Instead it simply returns a NULL value. In this way we insulate all the code you write from these type of dynamic changes.
Next time
This post has looked at the basics of how Snowflake handles semi-structured data, using JSON as a specific example. In Part 2, I will show you how we handle more complex schema structures like arrays and nested arrays within the JSON document as well as give you a brief example of an aggregation and filtering against the contents of a VARIANT data type.
Additional Links
Authors
