Modern Reference Architectures for Application Builders

For every data application use case, there is a modern data stack architecture with built-in scalability, connectivity, and support for all data.
Only a cloud data platform can deliver the performance and nearly infinite autoscaling that application builders need to launch and scale apps quickly and cost-effectively. Snowflake Cloud Data Platform provides:
- High performance and unlimited concurrency: Through a multi-cluster, shared data architecture, Snowflake spins up dedicated compute clusters that support a nearly unlimited number of concurrent workloads on shared tables.
- Scalability with true elasticity: Snowflake compute resources scale up and down automatically to deliver on-demand high performance that’s cost effective.
- SQL for all data: Snowflake ingests JSON, Avro, Parquet, and other data without transformations or requiring pipeline fixes every time the schema changes. With ANSI SQL, Snowflake enables your teams to query semi-structured data just as easily as structured data.
- No Site Reliability Engineering/DevOps burden: As a near-zero management platform, Snowflake automatically handles provisioning, availability, tuning, data protection, and other operations, which enables you to focus on your own application rather than on maintenance.
Snowflake also ensures seamless connections to third-party platforms and APIs, easily fitting in with your existing environment.
A SNOWFLAKE IOT REFERENCE ARCHITECTURE
Modern data architectures can deliver a highly performant service for data-intensive applications. As an example, here is a Snowflake reference architecture for IoT applications that analyze large volumes of time-series data from devices and respond in real time.
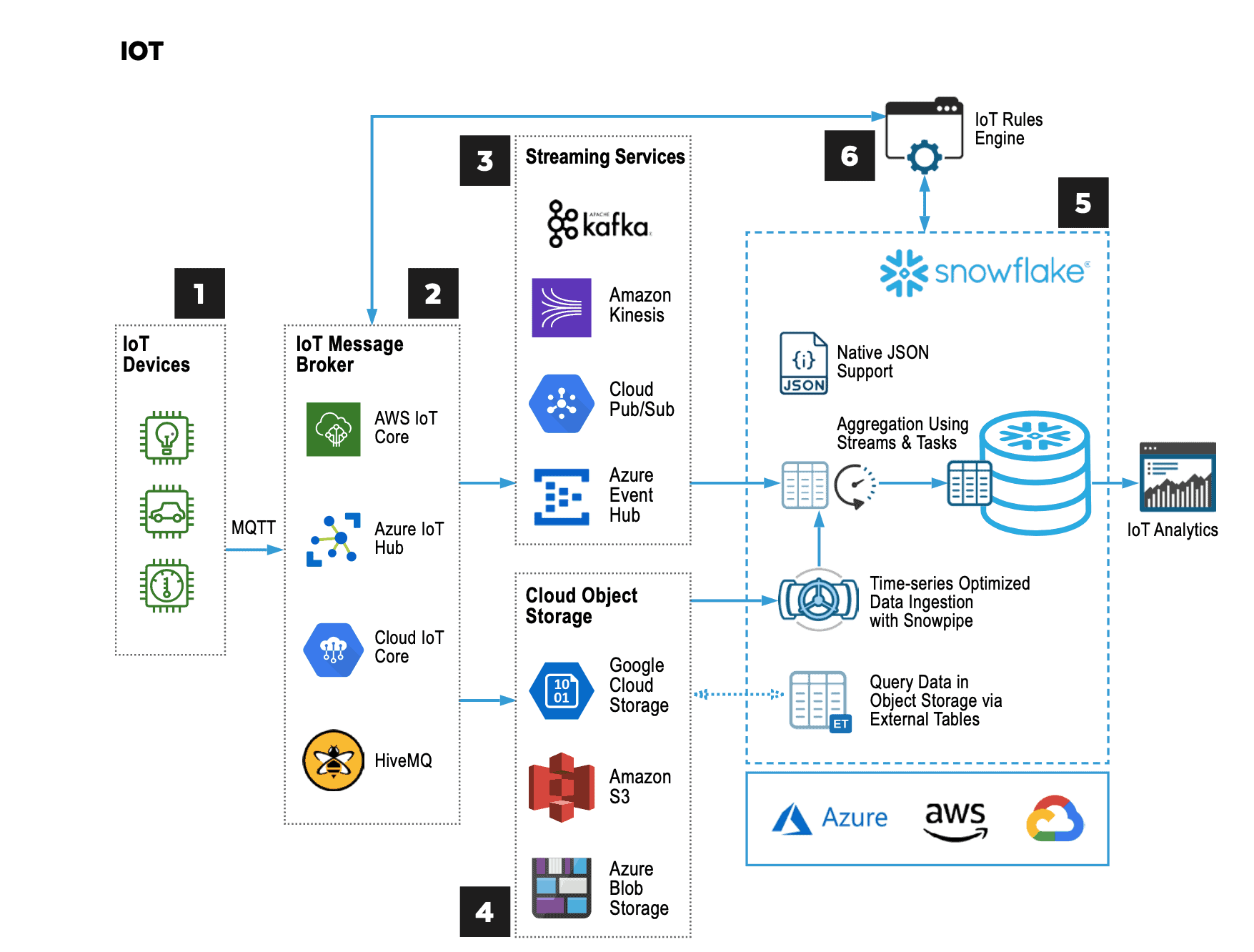
In this reference architecture, data generated by smart devices, sensors, and other IoT devices is communicated through an IoT message broker to a streaming service, ensuring reliable ingestion and delivery to a staging table in Snowflake. In cases where the application requires it, cloud object storage is used to stage batch data prior to ingestion.
Snowflake offers native support for JSON and other semi-structured data formats for easy ingestion of device data. Snowpipe automatically optimizes time-series queries by ingesting data chronologically. Snowflake’s Streams and Tasks features automate the workflows required to ingest and aggregate incoming data.
Finally, an IoT rules engine hosts the business logic required by the application and operates on data available in Snowflake and in the message broker. The rules engine sends messages back to control devices.
Reference architectures such as this one demonstrate the importance of a cloud data platform that can deliver high performance and nearly infinite autoscaling.
FUTURE-PROOF YOUR APPLICATIONS
The key is to build an architecture that will evolve with your scalability needs, rather than spend valuable development time rearchitecting your data stack over and over again. A cloud data platform lets you focus on what you do best: building and improving your application to entice new customers.
Download our ebook, 7 Snowflake Reference Architectures for Application Builders, to access more detailed reference architectures for six more use cases and design patterns, including serverless and streaming data stacks, machine learning and data science, application health and security analytics, customer-360, and embedded analytics.
Authors
