注:本記事は(2023年6月29日)に公開された(Snowflake’s ML-Powered Functions Enhance Speed and Quality of Decisions)を翻訳して公開したものです。この記事の翻訳には機械翻訳を使用しています。
データアナリストは厳しい仕事をしている。組織内のデータの爆発的な増加に歩調を合わせるためには、正確な洞察を得るために必要な作業と、迅速な意思決定の必要性とのバランスを取らなければならない。
彼らが異常を迅速に理解し説明しようとするとき、彼らのデータを深く掘り下げるには貴重な時間と労力が必要である。そして、一般的な分析のための既存のツールは、生活を楽にすることを意味しており、日々直面するデータ量に常に追いつくことはできない。アナリストは、高度な分析で使用するデータが安全に処理されていることを確認しながら、このすべてを管理するのに苦労しています。
機械学習(ML)アルゴリズムは、これらの課題のいくつかを解決することができる。しかし、プログラミングとデータサイエンスの知識ギャップと複雑なコンピューティングインフラストラクチャは、アナリストがMLを採用することを妨げます。
Snowflakeでは、MLフレームワークの複雑さの一部を抽象化できれば、アナリストはMLの利点を活用できると考えています。
そのため、Summit 2023 では、パブリックプレビューでいくつかのML-Powered Functionsを発表しました。これらの使い慣れたSQL 関数は、ML を使用して、アナリストがより高い品質の意思決定を迅速に行うのに役立ちます。このブログでは、これらのML-Powered Functionsがどのように実行されるかを正確に説明します。
Forecasting
アナリストは、新しいForecasting関数を使用して、季節性やスケーリングなどの自動処理により、より正確な時系列予測を構築できるようになりました。
// This shows training & prediction for revenues in daily_revenue_v
create snowflake.ml.forecast revenue_projector(
input_data => SYSTEM$REFERENCE('VIEW', 'daily_revenue_v'),
timestamp_colname => 'ts',
target_colname => 'revenue'
);
// The model is now ready for prediction.
call revenue_projector!forecast(
forecasting_periods => 30, // how far out to project!
config_object => {'prediction_interval': 0.9} // optional range of values with this probability
); この機能を使用すると、アナリストは何度も予測を生成するために使用できるML モデルをトレーニングできます。Forecastingでは、予測間隔と呼ばれる予測の範囲だけでなく、予測された見積もりも生成できます。これらは、予測が下がる可能性の高い範囲を浮き彫りにしている。
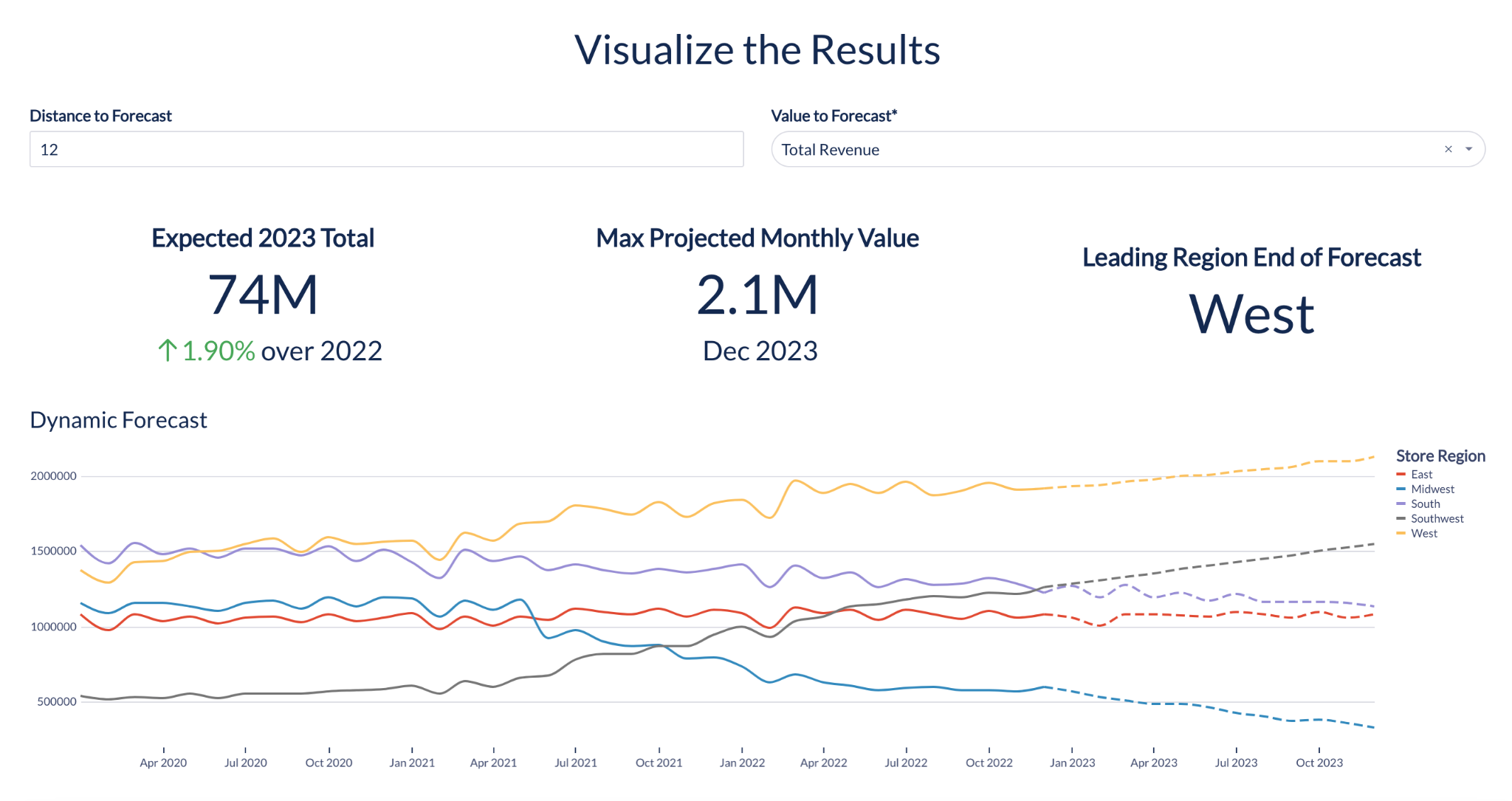
この機能により、たとえば将来の収益を見積もり、店舗ごとの売上高の正確な予測を求めているアナリストは、データサイエンスチームに頼らずに生活を楽にすることができます。
Forecastingでは、アナリストは単一の時系列または単一の時系列内の複数のカテゴリの予測を生成できます。たとえば、小売店にいる場合、店舗間のアイテムの総売上を予測するのではなく、店舗あたりの売上を予測できます。このForecasting関数を使用すると、予測ごとに細分性を高めることができます。追加の単純なコード行を1 行だけ使用することができます。
// Add series_colname to predict sales by category.
create snowflake.ml.forecast revenue_projector_by_store(
input_data => SYSTEM$REFERENCE('VIEW', 'daily_revenue_v'),
timestamp_colname => 'ts',
target_colname => 'revenue',
series_colname => 'store_id'
);
// The model is now ready for prediction.
call revenue_projector_by_store!forecast(
forecasting_periods => 30, // Predict sales for one month.
);外生変数(数値かカテゴリかにかかわらず)を含めることで、予測の質をさらに向上させることができます。したがって、例えば、公休日が、外生変数としての休日を含め、小売販売数量に大きな影響を与えることがわかっている場合は、予測の精度を向上させる必要があります。
Forecastingでは、4 時間、1 日、7 日などのカスタム時間軸の予測を生成することもできます。この柔軟性が、データサイエンスチームに頼らずに、特定のニーズや時間枠に合わせた予測を得るのに役立つことを願っています。
Anomaly Detection
アナリストがMLを使用して異常値を識別し、アラートをトリガーできる場合はどうでしょうか。これで、新しいAnomaly Detection 機能を使用できます。アナリストは、これを利用して、疑わしい活動について調査すべき異常事象を見つけたり、将来の分析から除外すべき、再び起こりそうにない状況を見つけたりすることもできます。
Anomaly Detectionは、単一の時系列または1つの時系列内の複数のカテゴリの異常を特に予測します。このMLパワーの異常検出方法は、外れ値を識別するための静的しきい値を置き換え、代わりにデータのスマートで動的なベースラインを作成するモデルに依存する場合に役立ちます。
この関数サーフェスで誤検出の数を制御できるようにするため、この関数では異常をフラグするために使用される予測間隔のサイズを調整できます。次に示すように、Snowflake Tasks and Emails を使用して、異常がフラグされたときに自動的に通知を受け取ることができます。
-- Set up a task to train your model on a weekly basis.
create or replace task train_anomaly_detection_task
warehouse = LARGE_WAREHOUSE
SCHEDULE = 'USING CRON 0 0 * * 0 America/Los_Angeles' -- Run at midnight every Sunday.
as EXECUTE IMMEDIATE
$$
begin
create or replace snowflake.ml.ANOMALY_DETECTION my_model(input_data => SYSTEM$REFERENCE('VIEW', 'view_of_your_input_data'),
timestamp_colname => 'ts',
target_colname => 'y',
label_colname => '');
end;
$$;
-- Start your task's execution.
alter task train_anomaly_detection_task resume;
-- Create a table to store your anomaly detection results.
create or replace table anomaly_detection_results (
ts timestamp_ntz,
y float,
forecast float,
lb float,
ub float,
is_anomaly boolean,
percentile float,
distance float
);
-- Call your model to detect anomalies on a daily basis.
create or replace task detect_anomalies_task
warehouse = LARGE_WAREHOUSE
SCHEDULE = 'USING CRON 0 0 * * * America/Los_Angeles' -- Run at midnight, daily.
as EXECUTE IMMEDIATE
$$
begin
call my_model!detect_anomalies(
input_data => SYSTEM$REFERENCE('VIEW', 'view_of_your_data_to_monitor'),
timestamp_colname =>'ts',
target_colname => 'y',
config_object => {'prediction_interval': 0.99});
insert into anomaly_detection_results (ts, y, forecast, lb, ub, is_anomaly, percentile, distance)
select * from table(result_scan(last_query_id()));
end;
$$;
-- Start your task's execution.
alter task detect_anomalies_task resume;
-- Setup alert based on the results from anomaly detection
CREATE OR REPLACE ALERT anomaly_detection_alert
WAREHOUSE = LARGE_WAREHOUSE
SCHEDULE = 'USING CRON 0 1 * * * America/Los_Angeles' -- Run at 1 am, daily.
IF (EXISTS (select * from anomaly_detection_results where is_anomaly=True and ts > dateadd('day',-1,current_timestamp()))
THEN
call SYSTEM$SEND_EMAIL(
'SNOWML_ANOMALY_DETECTION_ALERTS',
'[email protected]',
'Anomaly Detected in data stream',
concat(
'Anomaly Detected in data stream',
'Value outside of confidence interval detected'
)
);
-- Start your alert's execution.
alter alert anomaly_detection_alert resume;Contribution Explorer
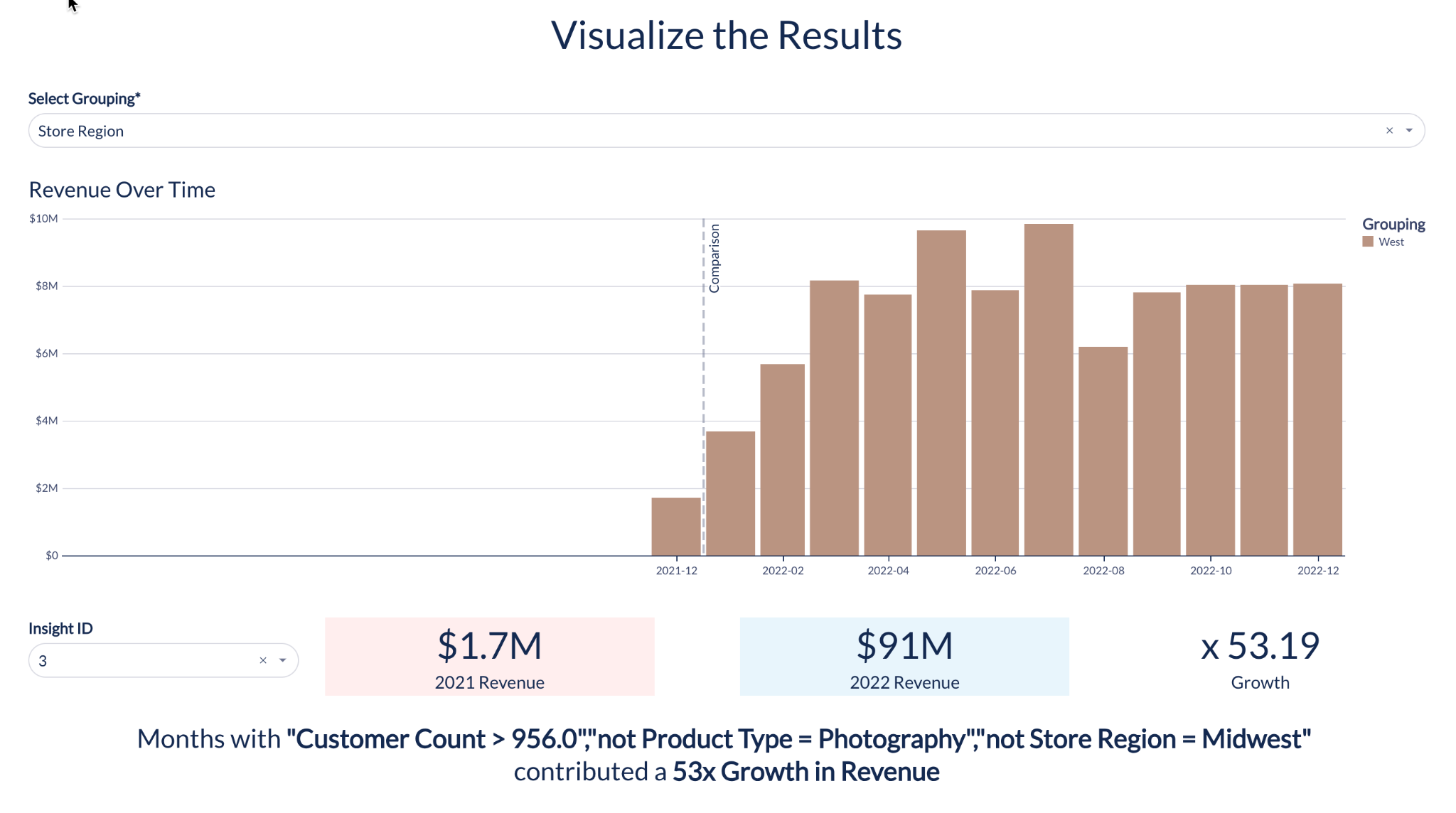
これで、アナリストはML を使用して、2 つの異なるユーザー定義の時間間隔にわたる特定のメトリクスの変更に寄与するディメンションをすばやく識別できます。売上や使用量などの主要なビジネスメトリクスに異常がある場合は、その異常の原因を把握し、根本原因を見つける必要があります。Contribution Explorerは、次元とその値を何百万もの組み合わせてマイニングし、最も驚くべき「セグメント」と呼ばれる次元とその値を見つけます。たとえば、特定の地域の特定の顧客が突然製品の使用を停止したことがあります。
実際、Contribution Explorer を使用すると、アグリゲートレベルに明白な異常がない場合でも、定期的にメトリクスを分析して隠れたgem を見つけることができます。たとえば、売上が異常ではないことがわかっても、2つの異なる顧客への売上が同時に成長し、減少した可能性がある。
with input as (
select
// Select dimensions to "mine"
{ 'country': input_table.dim_country,
'vertical': input_table.dim_vertical
} as categorical_dimensions,
{
} as continuous_dimensions, // less common but available
// This is the metric for comparison
input_table.kpi,
// Label control & test periods for comparison
iff(ds between '2020-08-01' and '2020-08-20', TRUE, FALSE) as label
from input_table
where (ds between '2020-05-01' and '2020-05-20')
or (ds between '2020-08-01' and '2020-08-20')
)
// Now use the above data to compare contributions of dimension segments
select res.* from input, table(
snowflake.ml.top_insights(
input.categorical_dimensions,
input.continuous_dimensions,
CAST(input.kpi as float),
input.label
)
over (partition by 0)
) res order by res.relative_change desc;SnowflakeのML-Powered Functionsは何がユニークですか?
弾力性、ニアゼロのオペレーション、データガバナンスなど
SnowflakeのML-Powered Functionsを使用すると、次元-値の組み合わせを1つから数百万個まで簡単にスケーリングできます。Snowflakeのエンジンの弾力性とニアゼロの操作で可能です。さらに、Forecasting、Anomaly Detection、およびContribution Explorerの呼び出しを、他のSQL 関数と同様にデータパイプラインに統合できます。Snowflake Tasks and Alerts でこれらの機能を使用すると、新しいデータの取得時に毎週新しいモデルを自動的にトレーニングし、毎日または毎時(必要に応じて)予測を生成し、異常を検出し、調査する必要がある場合にアラートを受け取ることができます。
ML-Powered Functionsの使用方法に関係なく、関数の入出力間でSnowflakeの一貫したデータガバナンスが得られます。
ML 機能の範囲
ML-Powered Functions は、データサイエンスに焦点を当てたSnowpark ML 関数 を完全に補完します。前者は、モデルのトレーニング、評価、さらには、分析者や多忙な意思決定者のための最小限の努力で、後者は、データ科学者が自分のモデルをまとめるための豊富で柔軟なツールボックスを提供する。
一緒に、問題の性質や、問題を解決するために入力したいデータサイエンスの労力に応じて、選択できるさまざまなオプションを提供します。
SigmaのようなBIツールからの機械学習のための洞察の抽出
SnowflakeのML-Powered Functionsをサポートし、ビジネスユーザーがMLから洞察を抽出するためのユーザーフレンドリーなインターフェイスを提供するBIツール、Sigmaとの提携を誇りに思っています。これは、SnowflakeのTime Series ForecastingおよびContribution Explorerのフロントエンドサポートを提供します。
Snowflake アカウントでこれらの関数を有効にし、Sigma の役割へのアクセス権を付与することで、Sigma データセットを使用できます。これにより、表形式と視覚的分析の両方の簡略化された開始点が提供されます。Time Series ForecastingまたはContribution Explorerを使用するには、目的のテーブルまたはデータセットを識別し、優先される粒度に基づいてデータをグループ化し、探索のための集約メトリクスを作成します。テーブルを準備し、ウェアハウスビューを作成し、それに対してCustomSQL を使用してDatasetを定義し、提供された構文を使用して対応する関数を適用します。
Time Series Forecastingは、時間ベースの予測のセットを出力します。Contribution Explorer は、キーメトリクスの増加に最も大きく貢献したセグメントのソート済みリストを提供します。どちらのデータセットもワークブックにシームレスに統合でき、ビジュアライゼーション、探索、および他のウェアハウステーブルとの結合を可能にします。インタラクティブ性を強化するには、Custom SQL の静的変数をパラメータに置き換え、ユーザーがワークブック内の関数を変更できるようにします。
Forecasting
Contribution Explorer

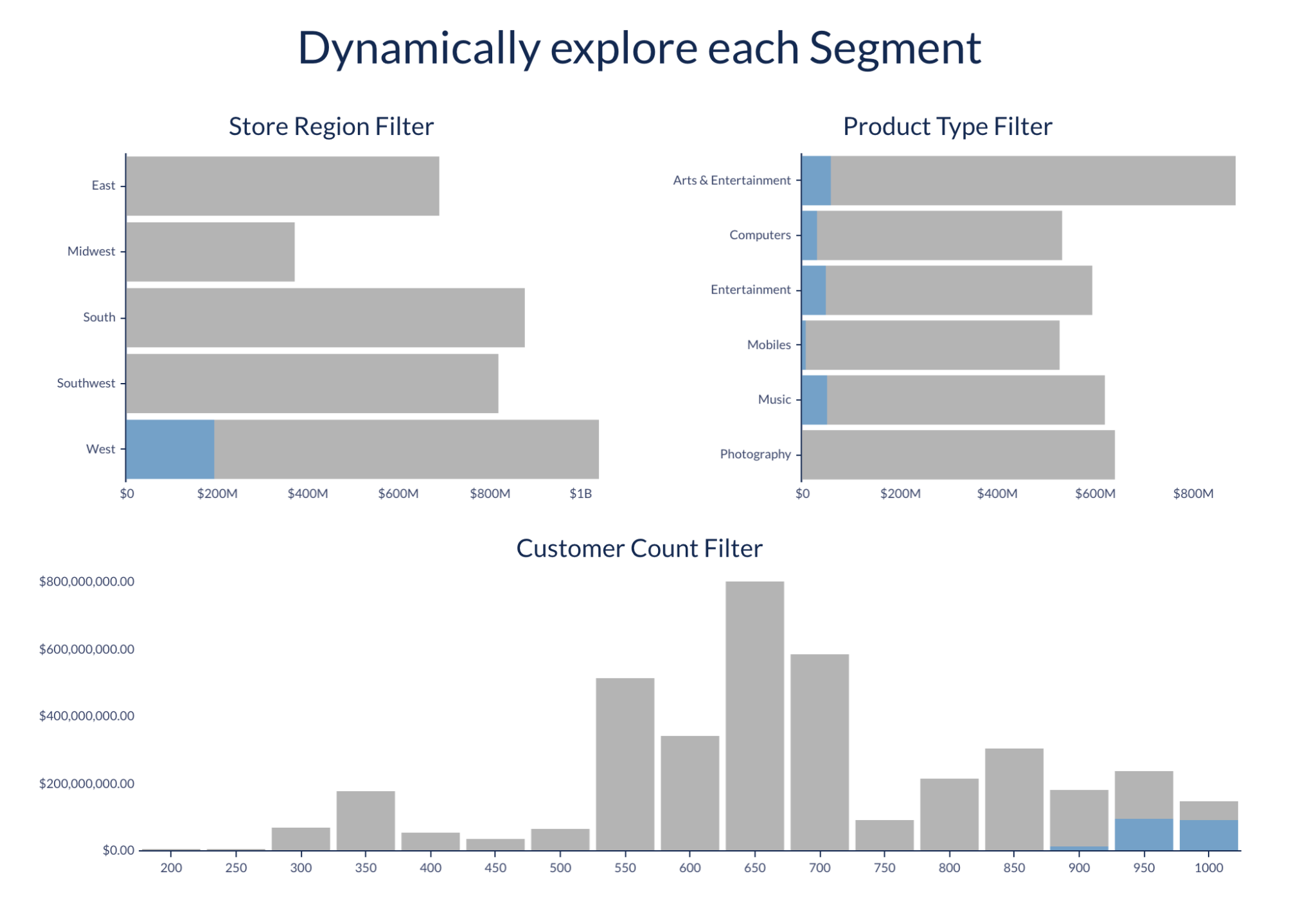
このデータセットは、任意のワークブックでシームレスに使用でき、簡単なビジュアライゼーション、探索、およびウェアハウス内の他のテーブルとの結合を提供し、今後予想されるメトリクスを包括的に理解することができます-自分で試してみてください。
What’s next?
初期の顧客フィードバックにより、前述の機能を拡張し、新しくエキサイティングな方法で一連の機能を拡張する作業が可能になりました。Anomaly DetectionおよびContribution Explorer は時系列データで始まりますが、そこで停止する必要はありません。また、他のデータにも適用され、顧客間の外れ値を見つけたり、ユーザのコホートを比較して、コホート間の差異に寄与する最も興味深いセグメントを見つけることができます。実際、ML-Powered Functions でカバーされるデータを広げることに取り組んでいます。
これらの機能をさらに進化させていく中で、お客さまを選んでスピンさせ、フィードバックをしていただくことを求めています。チューニングを維持し、アカウントチームと話して、今後のプレビューが利用可能になったときにアクセスします。そして、あなたのユースケースをここで共有してください。MLでできることの未来はほとんど無限です ー ML-Powered Functionsは、拡大を続けるML研究に追いつかなくても、より良いビジネス成果のためにアクセスできる能力を成長させる計画です。
ML-Powered Functions の詳細については、 Snowflake documentationをご覧ください。