
OCT 21, 2020|5 min read

Snowflake is a powerful platform for data warehousing workloads. With increasing demands for data within the enterprise, Snowflake handles existing workloads from previous data warehousing solutions while enabling new data projects and new data demands. It improves data governance, provides granular data security, and enables Cisco (and our customers and partners) to harness the power of data to deliver big business impact.
As Anupama Rao shared in our blog post about our migration, Snowflake significantly surpassed performance expectations for reporting and transformations. She explained, “Transformation jobs that would take 10 or more hours to run are now completing within an hour, a 10x performance improvement. This provides our business teams more current data on their dashboards, allowing for more accurate insights based on the latest data. Reports are now on average 4 times faster with a 4x concurrency improvement, which gives our analysts the flexibility to run reports in parallel based on business needs.”
Snowflake’s pay-per-use pricing model enables organizations to shift their cost management focus from planning to monitoring and optimizing. Snowflake comes with checks and balances to optimize the cost right out of the box, but further optimizations are possible if you understand some fundamentals of how Snowflake works. Concurrency and scalability along with optimal performance are the core moto of any data warehouse environment. In this two-part series, we’ll review core architectural components of Snowflake and recommend best practices for how you can optimize performance on Snowflake for your workloads.
Snowflake’s architecture, shown in Figure 1, includes:

Figure 1: Snowflake architecture
The Snowflake platform provides a consistent experience across cloud regions and providers. The complexity of different cloud infrastructure and management tasks is often invisible with Snowflake optimizing storage. The muscle of the system is driven by virtual warehouses, which are elastic clusters of virtual machines. Finally, the brain of the system is a collection of services at the Snowflake cloud services layer that manage virtual warehouses, queries, and all the metadata that goes along with it.
Optimizing parameters for caching can increase performance and reduce costs.
The metadata cache optimizes the performance of Snowflake’s cloud services layer. User queries need to be validated both syntactically as well as semantically. To do this, Snowflake’s execution engine accesses the cache in the metadata layer to find the information for the account. Parsed query plans are cached, so subsequent, similar queries can compile faster. Snowflake maintains and optimizes the metadata cache, so it requires no user intervention.
In Snowflake, virtual warehouses are inside the compute (middle) layer. Almost every query execution in Snowflake needs an active virtual warehouse (with the exception being metadata-driven queries like SHOW TABLES and precomputed aggregate queries like SELECT COUNT(*) or SELECT MIN(COL).
A virtual warehouse (much like any other compute server) is provisioned with predefined CPU, memory, and storage. Whenever a query is executed, the associated data is retrieved from the cloud storage layer. This data is in turn stored on a high-speed SSD associated with the provisioned warehouse. The next time a query needs the same data, it reuses the data from the local disk cache (called warehouse cache). The data that is not available in the warehouse cache will result in remote I/O. Remote I/O is time-consuming and costly, so using the warehouse cache enables faster and more cost-effective query responses.
In Snowflake, the size of the warehouse cache is directly proportional to the size of a warehouse used. For example, a cache associated with an XS-sized warehouse would be 128 times smaller than a corresponding cache associated with a 4XL-sized warehouse. This is one of the reasons you should pick the size of the warehouse most suited to your needs.
You can set a warehouse to suspend automatically based on parameters you enter. Whenever a warehouse is suspended, the corresponding cache gets cleared immediately, so you should consider the tradeoff between cost and performance when setting warehouse suspension parameters. If the warehouse is suspended too frequently, data may need to be cached again and again.
Consider the following points when designing a warehouse suspension time:
Figure 2 shows the difference in query time between a suspended warehouse and a running warehouse.
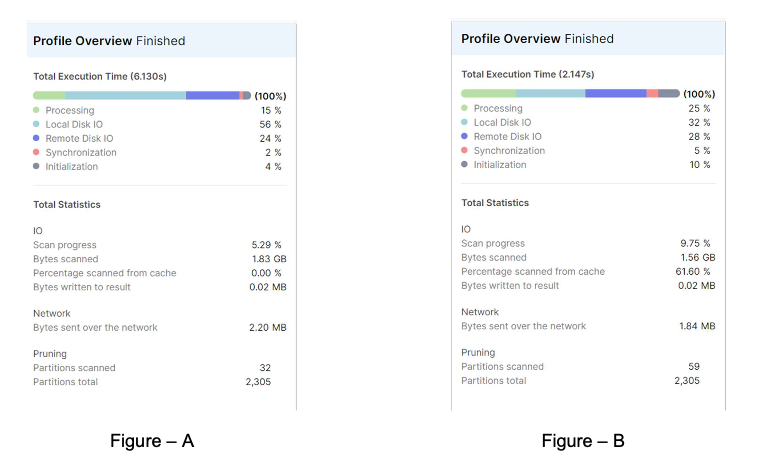
Figure 2: Query times displayed in the Query Profile between suspended and running warehouses, reflecting use of cached data
The query on the suspended warehouse (shown on the left) took 6 seconds and 80% of time was spent on I/O operation. The percentage scanned from cache shows 0% which means no warehouse cache was used. The query on the running warehouse (shown on the right) was completed in just 2 seconds. More than 60% of the data was scanned from cache, which resulted in a 66% faster query response time. An increase of the cache efficiency percentage was directly proportional to an increase in query response time.
Snowflake stores results in the result cache, and reuses persisted results when the same query is submitted. Figure 3 shows statistics for the original query, which took 4.5 seconds to be completed. When the same query was run again within the next 24 hours, it returned the results in a couple of milliseconds and the query profile shows the result cache was used.

Figure 3: Query results stored in the result cache as displayed in the Query Profile
Results are persisted for 24-hours up to a maximum of 31 days. However, the result cache works only if the queries submitted are identical (except for white space and new line characters). If there is a case difference between the queries, the result cache will not be leveraged. For instance, select col1 from tab1 is not the same as SELECT COL1 FROM TAB1.
The result cache can be used across users and roles as long as different roles querying data have access to all the underlying tables and are submitting identical queries. For example, if user A queries data X through Role R, within 24 hours if user B queries the same data X through Role S, the result cache will still be used and results will be returned without actually executing the query.
In Snowflake, every query needs a virtual warehouse—compute resources that include CPU, memory, and storage. Snowflake virtual warehouses come in “t-shirt sizes. The table below depicts the size of warehouses, associated resource availability, and the credits consumed per second when in use:

Figure 4: Table from Snowflake Documentation on Warehouse Size (subject to changes in sizing in the future, visit Snowflake documentation)
Larger warehouse sizes provide more resources. However, depending on the workload, increased resources do not necessarily provide better query response.
When designing a warehouse for a specific workload, consider the following:
With the multi-cluster warehouse feature, each virtual warehouse can become a set of clusters. The cluster size (one to 10) determines how many instances of similar warehouses can run in parallel (horizontal scaling). This comes in handy when the system is expected to process large concurrent loads, because it enables Snowflake to start additional clusters to handle the increased demands. When the load decreases, Snowflake automatically suspends the added clusters to a minimum cluster size, based on the auto-suspend setting.
Executing complex queries, which involve large data sets or a large number of joins, might need more compute resources. This will require upsizing the virtual warehouse (vertical scaling) with the ALTER WAREHOUSE command. However, every time you scale up a warehouse, the associated cache will get deleted, so it's better to size your warehouse based on the workload and leave it to run on the same size until significant changes in the workload occur.
This will ensure performance that enables you to meet SLAs, but be aware of cost tradeoffs, and use auto-suspend to manage uptime based on activity. Note that whenever a warehouse gets started, a minimum of one minute will be billed. Thereafter, it is billed for every second the warehouse runs, so setting a suspension time of less than a minute does not make any sense.
Clustering plays a crucial role when it comes to query optimization. Every table in Snowflake is partitioned by default into micro-partitions, each designed to store between 50 MB to 500 MB of uncompressed data. When a table has no explicit partition key, called a clustering key, defined, it is partitioned based on a natural key or the order of insertion.
You can define a clustering key based on a single column or more than one column (composite columns). Also, you can use functions when defining a clustering key. If you are defining a composite column-based clustering key, choose the order of columns from least cardinality to most cardinality. To evaluate the health of a clustering key on a table, invoke SYSTEM$CLUSTERING_INFORMATION.
When choosing a clustering column, consider the query pattern. Choose a column that is often used in filters and joins.
You can determine the efficiency of a clustering key from the associated query profile as shown in Figures 4 and 5.

Figure 5: Queries run back to back, before and after clustering
Figure 5 shows the query profile before and after clustering. The post-clustering response time came down from 5.3 seconds to milliseconds. Notice the difference between Partitions scanned and Partitions total fields at the bottom of the profile. This shows the results of partition pruning. A query without a clustering key scanned 52% of partitions, whereas with a clustering key it scanned only 7.5% of partitions. With the use of a clustering key, there was a 134% boost in query performance.

Figure 6: Query profiles showing query statistics before clustering (left) and after clustering (right)
Although clustering can improve performance, there are reclustering costs to consider. Once a clustering key is defined on a table, every DML that happens on the table will require a reclustering operation, which uses compute resources. Snowflake has an automatic clustering service that scans for changes and does the recluster in the background. The cost for these operations is charged as a service. To minimize this cost, check if inserted data can be added in the same order as that of clustering key definition. And if the table undergoes many changes in a day, consider suspending automatic clustering by using the ALTER TABLE command and resuming once a day to do cumulative clustering after those changes occur.
A materialized view is a physical structure that stores precomputed and aggregated data from a physical table. Whenever the underlying physical table undergoes a DML, Snowflake refreshes the associated materialized view to ensure data consistency. This service incurs an associated compute cost. Materialized views must be one-to-one (currently Snowflake does not support materialized views involving joins). Snowflake recently released a new feature, query rewrite, which automatically reroutes a query to use a materialized view (if one exists) instead of the base table if the query logic or aggregations exactly match the materialized view definition.
Before you use a materialized view:
Snowflake’s QUERY_HISTORY is a view shared from Snowflake’s internal metadata database. It has entries for every query that runs against a Snowflake system, and it is a great resource to optimize cost based on query pattern and history. It can be queried either from SNOWFLAKE.INFORMATION_SCHEMA or SNOWFLAKE.ACCOUNT_USAGE_SCHEMA.
The following columns from this view provide useful insights that can help to improve query performance and reduce associated cost at the system level:
By understanding Snowflake’s architecture and optimization capabilities, you can improve your performance and discover inefficiencies. Part 2 of this series will dive into best practices from our team at Cisco on optimizing performance.
At the time of writing this blog, Manickaraja Kumarappan was an Architect for Data & Analytics at Cisco.


