Now in Private Preview: Using On-Premises Data in Place with Snowflake


There continues to be a surge of companies moving more and more data to the cloud. Despite this rapid migration to public cloud storage, for a variety of reasons many organizations still have data stored on premises or in a private cloud. In this blog post, we’ll describe what’s been added in private preview to Snowflake’s External Tables to help you use data in place while still getting great benefits of the cloud and Snowflake.
Overview of External Tables
Snowflake External Tables were introduced in January 2021 to enable two main use cases, both without moving data to Snowflake:
- Performing analytics on data stored in cloud object storage
- Evaluating data sets before ingesting to Snowflake
External Tables come with important native Snowflake features to assist with security and governance, including column-level security, row-level security, tagging, and access history. This means customers can easily ensure that External Tables are used as they should be with a single pane of glass in Snowflake.
Also, External Tables are a shareable object in Snowflake. Paired with Snowflake’s cross-cloud capabilities, customers’ data doesn’t have to be confined to a particular cloud or region. This is very desirable in industries where cross-company collaboration is already very prevalent such as financial services, media and entertainment, and healthcare. For example, Customer A running Snowflake on AWS with External Tables on data stored in Amazon S3 can share revocable access to those tables with Customer B, who runs Snowflake on Azure in a different region.
And since the initial release, we’ve continued to make improvements for customers using External Tables. Earlier this year, the vectorized parquet scanner was improved to scan row groups in parallel along with predicate pushdown, both resulting in faster scans and queries.
Expanding to on-premises storage
A reality for many organizations is that some data can’t be moved to the public cloud, or at least some data is still in the process of being moved. Despite these constraints, these organizations still seek the ability to integrate all of their data to one place regardless of where it resides.
Announced at Summit, we’ve added (in private preview) the ability to create External Stages and External Tables on software and devices, on premises or in a private cloud, that expose a highly compliant S3 API. With these new capabilities, customers can use Snowflake to access data in those storage devices while getting the ease of use, elasticity, governance, resilience, and connectivity that Snowflake provides out of the box.
External Stages and External Tables against on-premises storage offer a number of benefits:
- Customers can make Snowflake their self-service platform for working with data without having to worry about concurrency issues or the effort of managing compute infrastructure.
- Data governors can apply consistent policies to tables and monitor usage regardless of where the data is physically stored.
- Analysts and data scientists have a full view of all relevant data, whether it’s on premises or in the cloud, including first-party or even shared, third-party data sets.
How it works
We have added a new URL prefix s3compat for creating External Stages; when used, the new endpoint parameter specifies the URL of an S3 API.
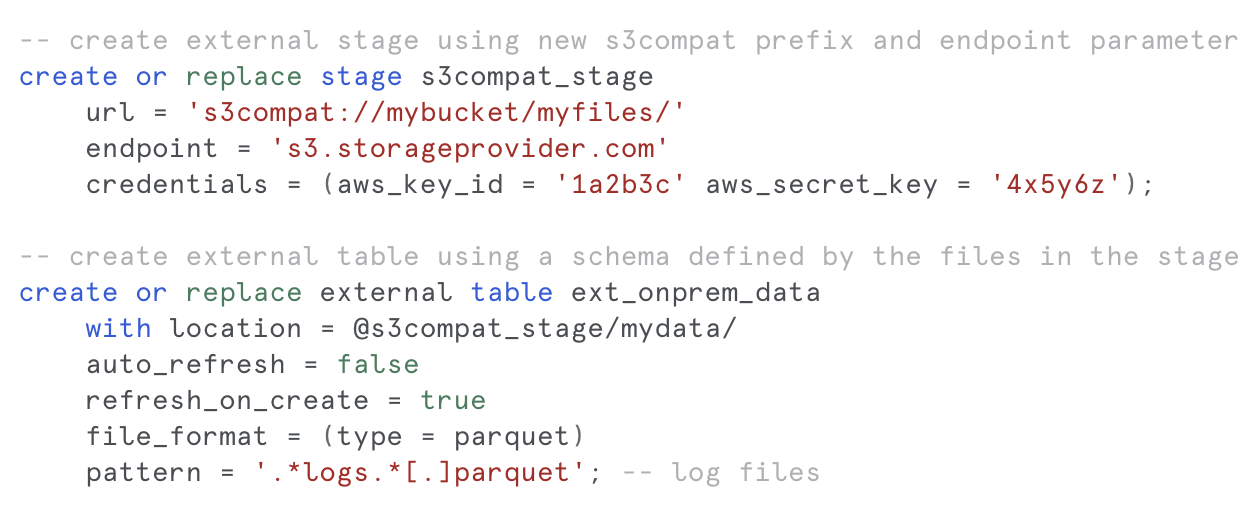
With an External Stage and Table defined against an on-premises device, you can use them as you normally would any other external stage and external table. For instance, you can query the table, refresh the table, and copy data into and out of the External Stage.

Snowflake treats the endpoint just as it would if the device were Amazon S3, but to be clear, the data remains in the specified device—no additional hop or routing through AWS.
Since Amazon S3 is commonly used, many vendors and customers have adopted the S3 API, such as Dell, Pure Storage, MinIO, and many more. This is why we’ve chosen the S3 API in our design: It is standard across a number of vendors. The vendor-provided storage device must provide a highly compliant S3 API. Some vendors and software may not work because their S3 API isn’t well conformed. To allow vendors to self-certify their work with Snowflake to their customers, we published a public test suite.
Although in the next section we’ll talk more about different table types designed for different use cases, there are some things you can do to maximize performance:
- Networking will impact latency and performance. Therefore, we recommend storage networking is as close to the cloud as possible.
- Create materialized views over External Tables, which will store a copy of the materialized view in Snowflake for high-performance analytics.
Since on-premises support works with the existing External Tables and External Stages features, powerful use cases are automatically supported without additional setup or installation, such as:
- Query JSON, Avro, ORC, or Parquet data using Schema-on-Read with Snowflake’s VARIANT data type in an External Table.
- Use Snowpark or External Functions to process unstructured data stored on premises without any movement of files to the cloud.
- Join an External Table of data stored on premises with a table acquired from the Snowflake Marketplace.
Picking the right storage for the job
We want to give our customers the flexibility to build architectures that best suit their needs and use cases. With that in mind, we provide options by building different storage products to support different patterns and use cases.
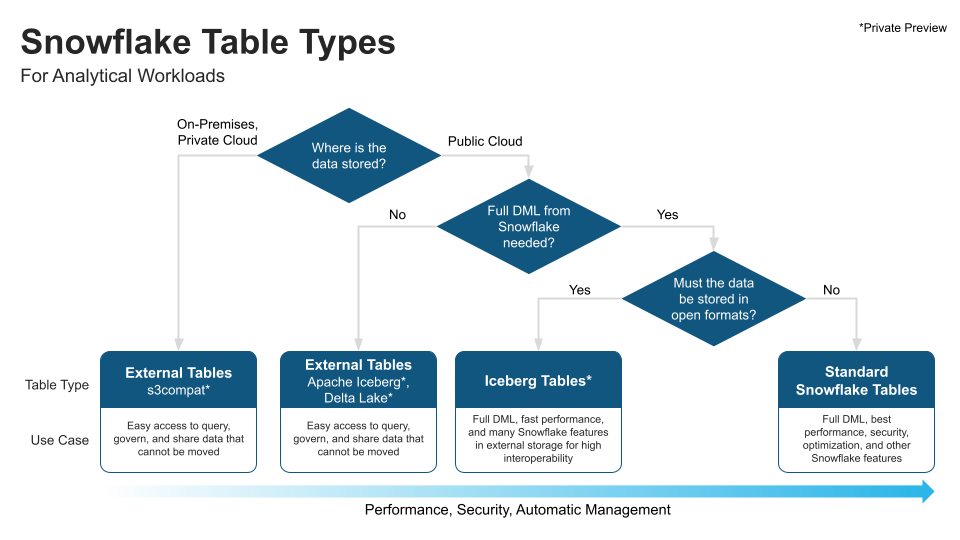
For example, in the context of data mesh, if a domain team wants the data for their product to be stored in Snowflake for best performance, security, full DML, and automatic management, they can do that. At the same time, another data set from another domain team has JSON data stored in an S3-compliant on-premises device where performance isn’t as important, but the data can’t be moved to the cloud due to regulatory reasons. In that case, an External Table is a great option. Regardless of the storage pattern, both data sets can be shareable, discoverable, and governed.
Get started
Creating External Tables and External Stages pointing to S3-compatible storage devices is available in private preview for Snowflake accounts in any cloud or region. To gain access to the private preview, please talk with your account team.
If you have a storage device you would like to use with Snowflake and are interested in knowing whether it will work, you can talk with your storage vendor or run our publicly available tests against your device. If your device does not work, or you are unsure if it will work, we recommend you talk with your storage vendor, or consider vendors who have announced support for Snowflake External Tables for on-premises storage.

Millisecond Latency at Scale: Why Our ML Feature Store Runs on Snowflake Postgres

Governing the Agentic Enterprise: What Marketing Leaders Need to Know Now

How Snowflake's Marketing AI Council Helped Turn a Global Org into an AI-Native Team
