Dynamic Tables: Delivering Declarative Streaming Data Pipelines with Snowflake

Companies that recognize data as the key differentiator and driver of success also know that a high-quality data pipeline infrastructure is a minimum requirement to effectively compete in the market. While a high-quality data pipeline infrastructure is difficult to achieve, especially when looking to bring together streaming data with existing reference or batch data, the data engineering community is close to having data pipelines that work well for analytical workloads.
To make the next generation of seamless and powerful pipelines a reality, we are launching Dynamic Tables, a new table type in Snowflake—now available in private preview! Dynamic Tables automate incremental data refresh with low latency using easy-to-use declarative pipelines to simplify data engineering workloads.
In this blog post, we’ll first cover the background of modern data architectures and the reasons data pipelines have become hard to manage and even harder to scale. We’ll then dive deep into why we built Dynamic Tables and how their usage can enable you and your team to rethink data pipelines to make them more resilient and efficient.
Overview of modern data pipelines
The process of building data pipelines is complex and time-consuming. Data lives in many different systems, is stored in many different formats, is messy and inconsistent, and is queried and transformed with many different tools and technologies. This includes the wide range of tools available for data replication, ETL/ELT, libraries and APIs management, orchestration, and transformation.
Among all these data engineering tools, the one shared characteristic is the move toward automation. For example, the modern approach to data ingestion is to leverage data replication tools that automate all the complex and time-consuming work of extracting data from source systems and landing it in your enterprise data lake.
The next step in data engineering is data transformation. Building data transformation pipelines with traditional ETL/ELT tools has historically been complex and involved a lot of manual effort. While these traditional tools are better than custom-coded solutions, they leave much to be desired. Recently, declarative pipelines have emerged as a solution to these problems.
Declarative pipelines are the modern approach to transforming data, and the tools involved automate much of the manual effort that was traditionally required. The data engineer is freed from the time-consuming task of creating/managing database objects and DML code, and can instead focus on the business logic and adding business value.
Another major benefit of declarative pipelines is that they allow batch and streaming pipelines to be specified in the same way. Traditionally, the tools for batch and streaming pipelines have been distinct, and as such, data engineers have had to create and manage parallel infrastructures to leverage the benefits of batch data while still delivering low-latency streaming products for real-time use cases.
With Snowflake, you can run data transformations on both batch and streaming data on a single architecture, effectively reducing the complexity, time, and resources needed. While this unification of batch and streaming pipelines is helping companies across industries to create a more sustainable and future-proof data architecture on Snowflake, the story doesn’t end there. Even with this unified pipeline architecture, data transformation can still be challenging.
Data pipeline challenges
Data engineers have various tool options to transform data in their pipelines when new data arrives or source data changes, but this typically results in a full refresh of the resulting tables. At scale, this can be incredibly cost-prohibitive. The single biggest technical challenge in data engineering is incrementally processing only the data that is changing, which creates a steep learning curve for data engineers. However, incremental processing is critical to building a scalable, performant, and cost-effective data engineering pipeline.
As the name suggests, data must be processed incrementally. There are essentially two approaches to processing data: a full refresh (also known as truncate/reload or kill/fill) or an incremental refresh. The full refresh approach will always break down at scale because as data volumes and complexity increase, the duration and cost of each refresh increase proportionally. Incremental refreshes allow costs to scale with the rate of change to the input data. However, incremental refreshes are challenging to implement because engineers need to be able to reliably identify the data that has changed and correctly propagate the effects of those changes to the results.
The next big challenge is managing dependencies and scheduling. A typical data pipeline has multiple tables that progressively transform the data until it’s ready for consumers. This requires coding the logic that drives data through the pipeline, including what transformations need to be run on which intermediate tables, how often they should be run, and how the intermediate tables relate to each other. It also requires creating an efficient schedule that takes into account the dependencies and desired data freshness.
So how does this relate to declarative pipelines and Snowflake Dynamic Tables? Solving these challenges is the core value provided by declarative pipelines. Dynamic Tables automatically process data incrementally as it changes. All of the database objects and DML management is automated by Snowflake, enabling data engineers to easily build scalable, performant, and cost-effective data pipelines on Snowflake.
What are Dynamic Tables?
Dynamic Tables are a new table type in Snowflake that lets teams use simple SQL statements to declaratively define the result of your data pipelines. Dynamic Tables also automatically refresh as the data changes, only operating on new changes since the last refresh. The scheduling and orchestration needed to achieve this are also transparently managed by Snowflake.
In short, Dynamic Tables significantly simplify the experience of creating and managing data pipelines and give teams the ability to build production-grade data pipelines with confidence. We announced this capability during Summit ’22 under the name "Materialized Tables" (since renamed). Now, we’re pleased to announce that Dynamic Tables are available in private preview. Previously, a data engineer would use Streams and Tasks along with manually managing the database objects (tables, streams, tasks, SQL DML code) to build a data pipeline in Snowflake. But with Dynamic Tables, data pipelines get much easier. Check out this diagram:
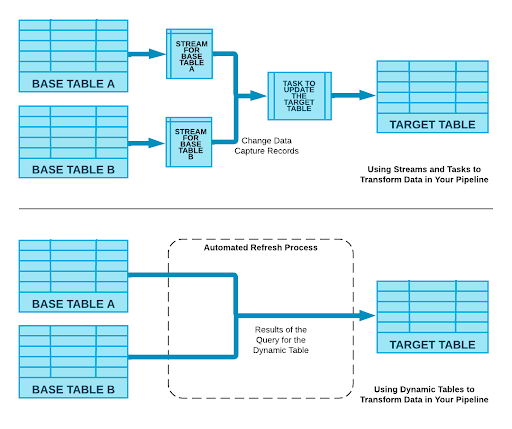
Here’s another view—the following example compares the SQL required to build a very simple pipeline with Streams and Tasks to the SQL required with Dynamic Tables. Look at how much easier this is!
SQL Statements for Streams and Tasks
-- Create a landing table to store
-- raw JSON data.
create or replace table raw
(var variant);
-- Create a stream to capture inserts
-- to the landing table.
create or replace stream rawstream1
on table raw;
-- Create a table that stores the names
-- of office visitors from the raw data.
create or replace table names
(id int,
first_name string,
last_name string);
-- Create a task that inserts new name
-- records from the rawstream1 stream
-- into the names table.
-- Execute the task every minute when
-- the stream contains records.
create or replace task raw_to_names
warehouse = mywh
schedule = '1 minute'
when
system$stream_has_data('rawstream1')
as
merge into names n
using (
select var:id id, var:fname fname,
var:lname lname from rawstream1
) r1 on n.id = to_number(r1.id)
when matched and metadata$action = 'DELETE' then
delete
when matched and metadata$action = 'INSERT' then
update set n.first_name = r1.fname, n.last_name = r1.lname
when not matched and metadata$action = 'INSERT' then
insert (id, first_name, last_name)
values (r1.id, r1.fname, r1.lname);Versus SQL Statements for Dynamic Tables
- Create a landing table to store
-- raw JSON data.
create or replace table raw
(var variant);
-- Create a dynamic table containing the
-- names of office visitors from
-- the raw data.
-- Try to keep the data up to date within
-- 1 minute of real time.
create or replace dynamic table names
lag = '1 minute'
warehouse = mywh
as
select var:id::int id, var:fname::string first_name,
var:lname::string last_name from raw;But not every data engineering pipeline can be built with Dynamic Tables. Data engineers will still need to pick the right Snowflake tool for the job. Here’s a handy guide to choosing between the options:
- Choose Materialized Views if…
- - You’re building visualizations in BI tools needing different levels of aggregations (query rewrite).
- - You want to improve the performance of external tables.
- - You have simple aggregation needs on a single table.
- - You need the data always refreshed as soon as possible.
- Choose Dynamic Tables if…
- - You’re building SQL-based transformation pipelines.
- - Your transformation requires complex SQL, including Joins, Aggregates, Window Functions, and more.
- - You’re building a pipeline of transformations vs. aggregations on a single table.
- - You need more control over when tables are refreshed.
- Choose Streams and Tasks if…
- - You need to incorporate UDFs/UDTFs, Stored Procedures, External Functions, and Snowpark transformations written in Python, Java, or Scala.
- - You need flexibility around scheduling and dependency management.
- - You need full control over incremental processing.
How do Dynamic Tables work?
CREATE [ OR REPLACE ] DYNAMIC TABLE
LAG = ' { seconds | minutes | hours | days }'
WAREHOUSE =
AS SELECT Through the use of Dynamic Tables for data pipelines, data transformations are defined using SQL statements, the results of which are automatically materialized and refreshed as input data changes. Dynamic Tables support incremental materialization, so you can expect better performance and lower cost compared to DIY data pipelines, and tables can be chained together to create a DAG pipeline of 100s of tables. Here’s how Dynamic Tables help data engineers do more with less:
1. Declarative data pipelines: You can use SQL CTAS (create table as select) queries to define how the data pipeline output should look. No need to worry about setting up any jobs or tasks to actually do the transformation. A Dynamic Table can select from regular Snowflake tables or other Dynamic Tables, forming a DAG. No more having to manage a collection of Streams and Tasks—Dynamic Tables manage the scheduling and orchestration for you.
2. SQL-first: Use any SQL query expression to define transformations, similar to the way users define SQL views. It’s easy to lift and shift your current pipeline logic because you can aggregate data, join across multiple tables, and use other SQL constructs. (During the private preview period some restrictions apply, details below).
3. Automatic (and intelligent) incremental refreshes: Refresh only what’s changed, even for complex queries, automatically. Processing only new/changing data can save costs significantly, especially as data volume increases. No need to track scheduling for dependent tables, as Dynamic Tables can intelligently fall back to full refresh in cases when it is cheaper (or more sensible). Dynamic Tables will also intelligently skip any refreshes in cases where there is no new data to process or if dependent tables are still refreshing without any user intervention. (During the private preview period some restrictions apply, details below.)
4. User-defined freshness: Controlled by a target lag for each table, Dynamic Tables are allowed to lag behind real time, with queries returning results up to a user-specific limit for the sake of reduced cost and improved performance. Deliver data to consumers as fresh as 1 minute (during preview; we plan to reduce the minimum lag target) from when data arrives.
5. Snapshot isolation: Works across your entire account. All DTs in a DAG are refreshed consistently from aligned snapshots. A DT will never return inconsistent data—its content is always a result that the defining query would have returned at some point in the past.
Check out the “What's New in Data Engineering” session at Snowday to see Dynamic Tables in action!
Private preview
Dynamic Tables are now available in private preview. To participate in the preview, please contact your account representative and let them know of your interest. We love customer feedback!
During private preview, some constraints apply. For customers using the private preview, please refer to the product documentation to read about our current limits, which we are working on improving through the preview period.
We hope you enjoyed learning about Dynamic Tables and are as excited as we are about the potential for them to transform your data pipelines with easy, create-and-forget semantics.
For more, check out the on-demand Snowday session.
Forward-Looking Statements
This post contains express and implied forward-looking statements, including statements regarding (i) Snowflake’s business strategy, (ii) Snowflake’s products, services, and technology offerings, including those that are under development or not generally available, (iii) market growth, trends, and competitive considerations, and (iv) the integration, interoperability, and availability of Snowflake’s products with and on third-party platforms. These forward-looking statements are subject to a number of risks, uncertainties and assumptions, including those described under the heading “Risk Factors” and elsewhere in the Quarterly Reports on Form 10-Q and Annual Reports of Form 10-K that Snowflake files with the Securities and Exchange Commission. In light of these risks, uncertainties, and assumptions, actual results could differ materially and adversely from those anticipated or implied in the forward-looking statements. As a result, you should not rely on any forward-looking statements as predictions of future events.
© 2022 Snowflake Inc. All rights reserved. Snowflake, the Snowflake logo, and all other Snowflake product, feature and service names mentioned herein are registered trademarks or trademarks of Snowflake Inc. in the United States and other countries. All other brand names or logos mentioned or used herein are for identification purposes only and may be the trademarks of their respective holder(s). Snowflake may not be associated with, or be sponsored or endorsed by, any such holder(s).
Authors

