Data Vault Techniques on Snowflake: Immutable Store, Virtual End Dates

Snowflake continues to set the standard for data in the cloud by eliminating the need to perform maintenance tasks on your data platform and giving you the freedom to choose your data model methodology for the cloud. Through this and more posts, we will discuss some Snowflake features you should consider that will enable your Data Vault to scale as dynamically as Snowflake scales.
Over the next few months, we will be publishing additional blog posts covering:
- Immutable store, virtual end dates
- Snowsight dashboards for Data Vault
- Point-in-time constructs and join trees
- Querying REALLY big satellite tables
- Streams and Tasks on views
- Conditional multi-table INSERT, and where to use it
- Row access policies and multi-tenancy
- Hub locking on Snowflake
- Virtual warehouses and charge-back
A reminder of the data vault table types:

An immutable versus a mutable object is the difference between an object that cannot be changed and an object that can be changed. To Snowflake these are the compressed and encrypted immutable 16MB micro-partitions that make up Snowflake mutable tables. Snowflake micro-partitions immutable files that are not visible to the Snowflake user; rather, the table acts as a container of micro-partitions and that is what the user will interact with. Some of the interactions are:
- A SQL INSERT operation that will load new records as new micro-partitions
- A SQL DELETE operation that will commit records and their micro-partitions to Time Travel
- A SQL UPDATE operation that will INSERT new records to the table and commit the old state of that record to Time Travel
More on Time Travel in a bit…

Simplified data representation, hash key will be a deterministic digest value on a parent key
A data vault satellite table contains the descriptive state of a business object (based on a hub table), or the descriptive state of a unit of work (based on a link table). A satellite table appears as a Kimball Slowly Changing (SCD) Type 2 dimension complete with start and end dates, and each SQL UPDATE by the parent key (hash-key) will in fact INSERT two records into the table. As demonstrated above, HASH KEYs 3, 5 and 6 have updates to an existing record and therefore we need the new state of these records to reflect what they look like once the SQL UPDATE has completed. And remember, micro-partitions are immutable.
A SQL SELECT query before the update on January 4 returns:
- HashKey 1, StartDate: 01-JAN-2022, EndDate: 31-DEC-9999
- HashKey 2, StartDate: 01-JAN-2022, EndDate: 31-DEC-9999
- HashKey 3, StartDate: 01-JAN-2022, EndDate: 31-DEC-9999
- HashKey 4, StartDate: 02-JAN-2022, EndDate: 31-DEC-9999
- HashKey 5, StartDate: 02-JAN-2022, EndDate: 31-DEC-9999
- HashKey 6, StartDate: 03-JAN-2022, EndDate: 31-DEC-9999

Satellite table as a Snowflake Base Table with Time Travel and Fail-Safe
At rest, the pre- and post-SQL UPDATE records exist on disk at the same time; however, the pre-SQL UPDATE records are only available by using Time Travel. Time Travel is not the same as an SCD Type 2 dimension; rather, think of Time Travel as a live backup of the satellite table. Time Travel can be set from 0 to 90 days and retrievable using Snowflake-extended SQL Time Travel syntax. Once the records fall out of the Time Travel period, they are set to the 7-day Fail-Safe period and only retrievable by contacting Snowflake support. Beyond those seven days those records are purged from Snowflake and unretrievable.
- Permanent tables can have Time Travel set from 0-90 days, 7 Fail-Safe cannot be changed.
- Transient tables can have 0-1 days of Time Travel and does not have Fail-Safe.

Time Travel is a live backup of your data you configure using Snowflake extended SQL
Querying the table after the update returns the current state of the records within that table, while querying using Time Travel returns the previous state of the table. Note the storage needs for HASH KEYS 3, 5, and 6. Therefore a SQL SELECT query on January 18 returns:
- HashKey 1, StartDate: 01-JAN-2022, EndDate: 31-DEC-9999
- HashKey 2, StartDate: 01-JAN-2022, EndDate: 31-DEC-9999
- HashKey 3, StartDate: 01-JAN-2022, EndDate: 15-JAN-2022
- HashKey 3, StartDate: 16-JAN-2022, EndDate: 31-DEC-9999
- HashKey 4, StartDate: 02-JAN-2022, EndDate: 31-DEC-9999
- HashKey 5, StartDate: 02-JAN-2022, EndDate: 16-JAN-2022
- HashKey 5, StartDate: 17-JAN-2022, EndDate: 31-DEC-9999
- HashKey 6, StartDate: 03-JAN-2022, EndDate: 16-JAN-2022
- HashKey 6, StartDate: 17-JAN-2022, EndDate: 31-DEC-9999
- HashKey 7, StartDate: 16-JAN-2022, EndDate: 31-DEC-9999
- HashKey 8, StartDate: 16-JAN-2022, EndDate: 31-DEC-9999


Data Vault 2.0 Satellite tables has no END-DATE column
Data Vault 2.0 recognized the expense in executing SQL UPDATE operations for some years now, and with the advancement of the SQL language itself, Data Vault 2.0 as a practice has deprecated the END-DATE column on the satellite table. Using SQL LEAD Analytical function, the end date of a parent key is now virtualized by defining an SQL VIEW over that satellite table right after the satellite table has been created.


As the data is a SQL INSERT operation with no SQL UPDATE operations needed, this means that table updates are only ever inserts of new records. This also means it does not matter at what velocity the data arrives in, Snowflake is not rapidly or slowly churning new micro-partitions trying to keep the table up to date. Nor is it creating a huge number of micro-partitions in Time Travel and Fail-Safe storage as if it were a high-churn table It also means that the Snowflake table does not need to have column clustering set, as the satellite table will naturally cluster by START-DATE. Most analytics are based on the current-date by parent-key anyway and therefore there is no need to recluster the table at all.
Cloning and Time Travel

Zero-Copy Cloning
Finally, a clone of a satellite table can be created across environments within a Snowflake account. A clone is a snapshot of the table at that point in time, and any new data added to PROD is not accessible by DEV (where the clone exists) and any new data added to DEV is not accessible by PROD. This patented Snowflake capability accelerates your DevOps processes by making instant copies of production-quality data available to develop on and no storage is replicated, only the metadata is.

Cloning can be extended to cloning entire schema or even entire databases, and you can even perform a schema swap for blue/green testing!
For example:
STEP 1: Clone schema to a DEV schema, perform changes

STEP 2: Catch up data loads to Dev clone

STEP 3: Swap Dev and Prod Schema

In summary
Separation of compute and storage and managing micro-partitions based entirely on metadata accelerates your DevOps processes, and with Data Vault 2.0 being an INSERT-ONLY methodology, it naturally fits and scales as Snowflake scales. There isn’t a need to track the previous state of a record when none is persisted to Time Travel.
However, you can indeed use Snowflake’s Time Travel feature to take a clone of your Data Vault at a snapshot point in time to accelerate your DevOps development and testing—or whatever your heart desires!
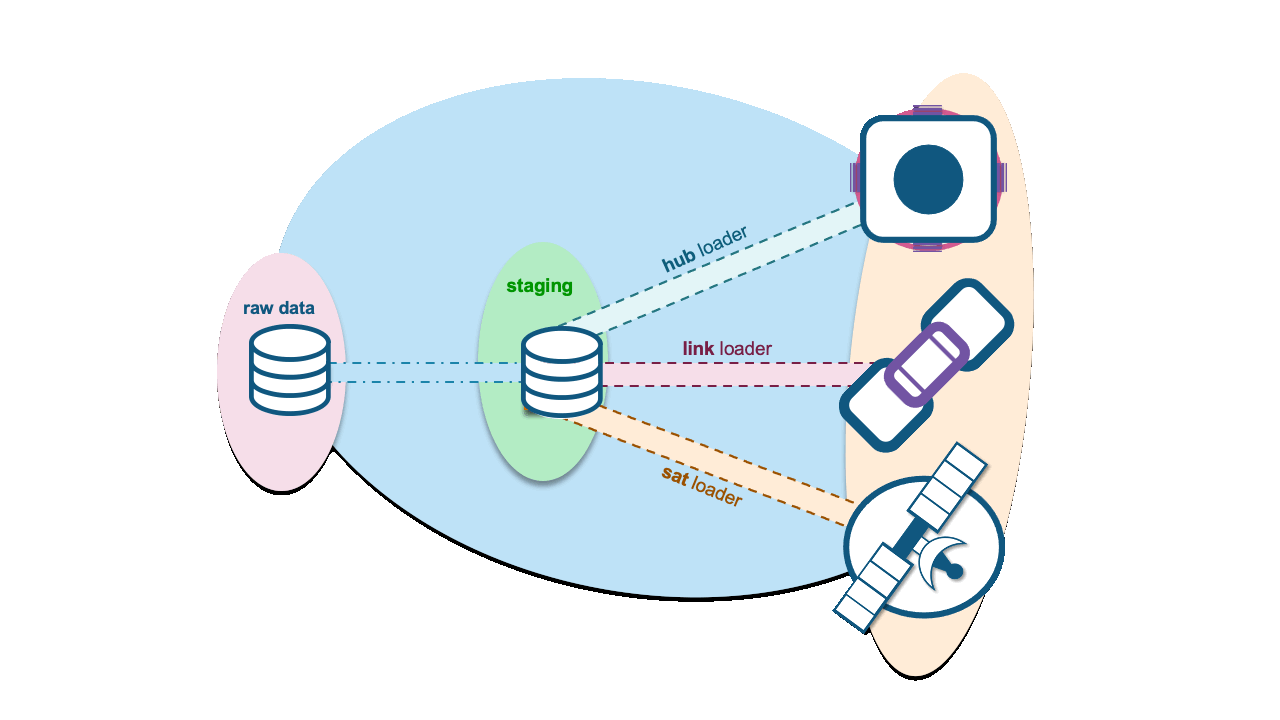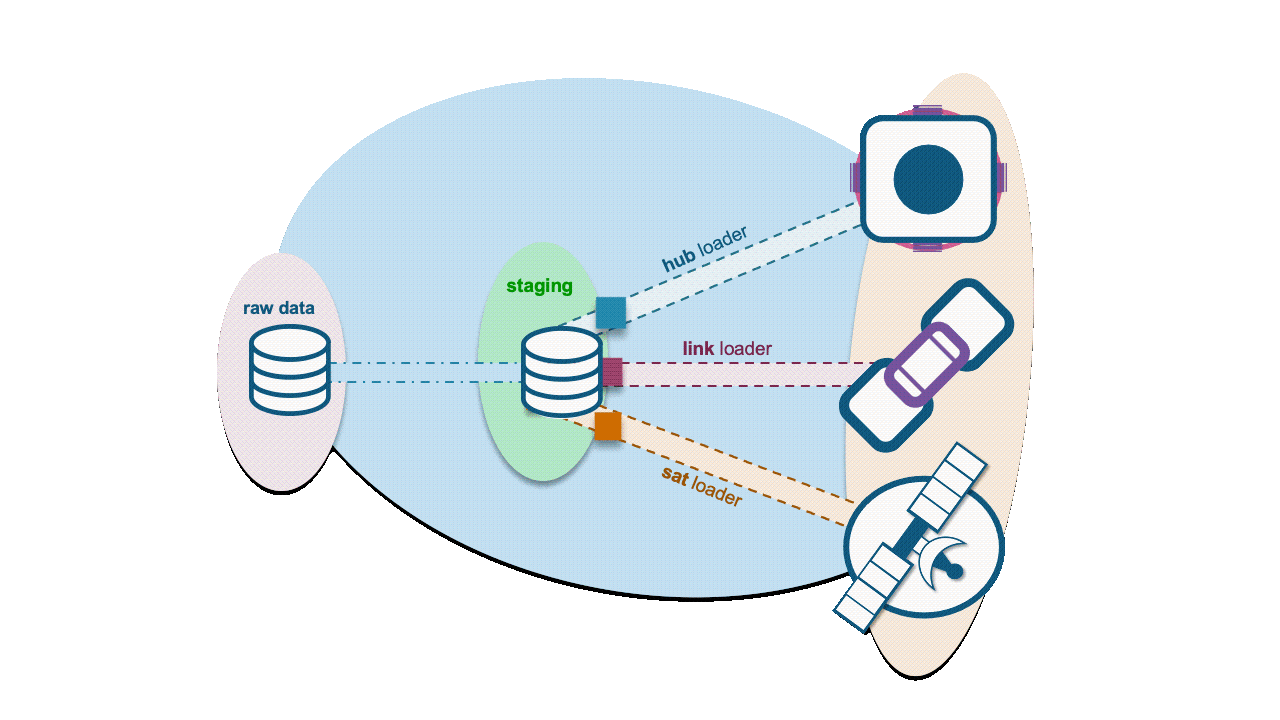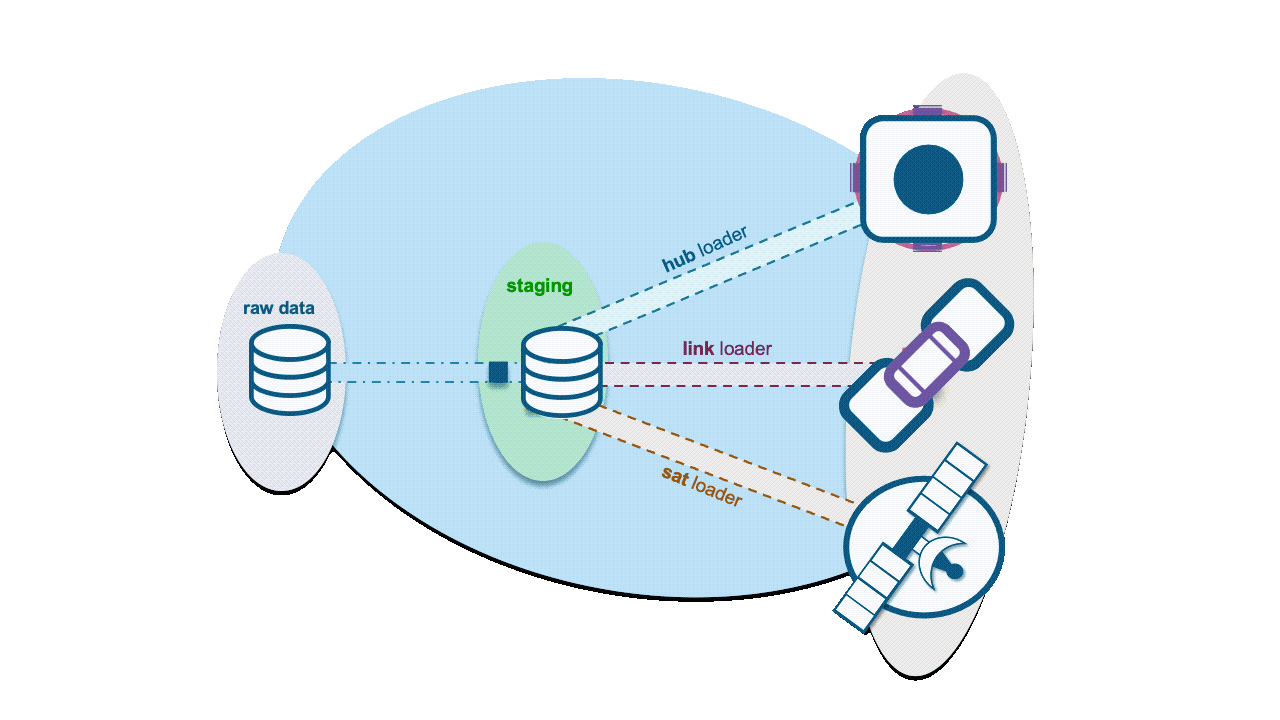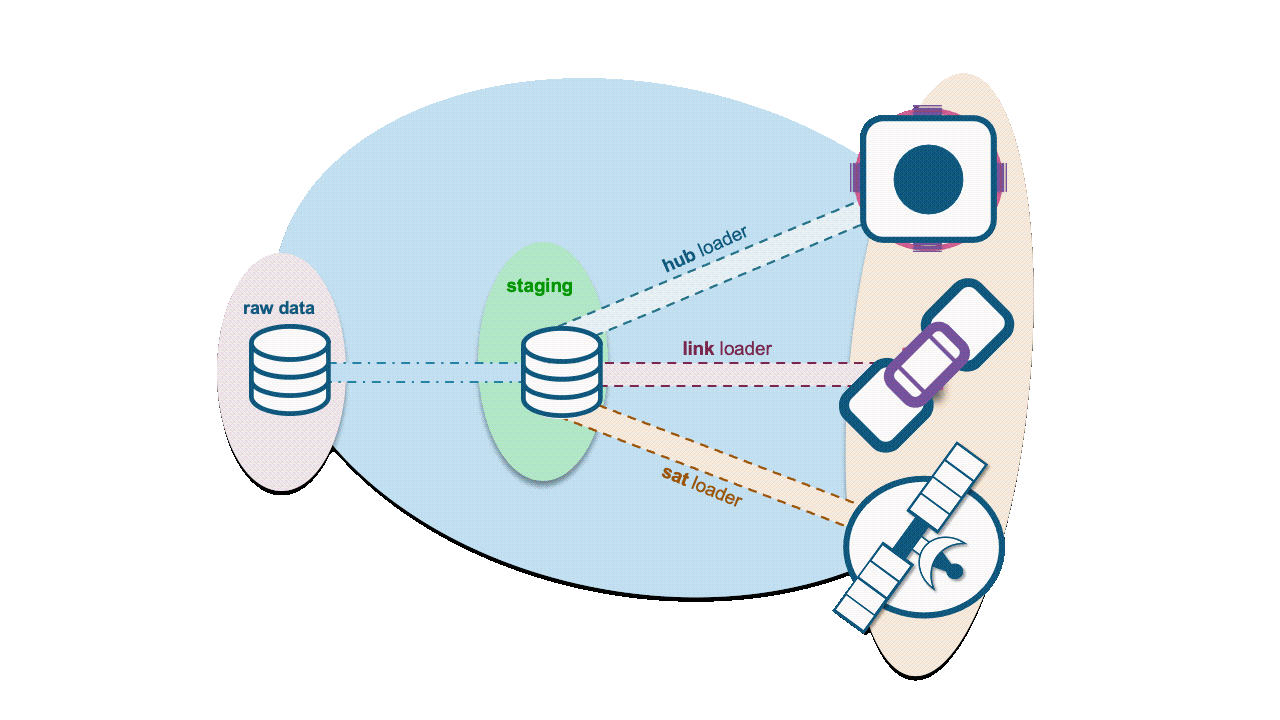
Additional references
- Snowflake micro-partitions and clustering: https://docs.snowflake.com/en/user-guide/tables-clustering-micropartitions.html
- Consideration for High Churn tables https://docs.snowflake.com/en/user-guide/tables-storage-considerations.html#managing-costs-for-large-high-churn-tables
- Snowflake Time Travel https://docs.snowflake.com/en/user-guide/data-time-travel.html
- Snowflake cloning https://docs.snowflake.com/en/user-guide/object-clone.html
Authors
