Snowflakeを使用したデータの取り込みのベストプラクティス:第1部

注:本記事は(2022年6月22日)に公開された(Best Practices for Data Ingestion with Snowflake: Part 1)を翻訳して公開したものです。
企業は今、データエステートの爆発的な増加を経験しており、事業の成長に向けたデータインサイトの収集にSnowflakeを活用しています。このようなデータには構造化、半構造化、非構造化形式のバッチデータやストリーミングデータが含まれます。当社のETLおよびデータ取り込みパートナーで構成されたエコシステムは、データクラウドへのデータ移動をサポートしています。Snowflakeはこの広範囲にわたるエコシステムと協力し、バッチ取り込みから連続取り込みまで、さまざまなパイプラインニーズに対応する幅広いファーストパーティによる手段を提供しており、これにはINSERT、COPY INTO、Snowpipe、Kafkaコネクタなどが含まれます。データがSnowflake上に取り込まれると、Snowpark、セキュアなデータシェアリングなどの強力なSnowflakeの機能を活用してデータの価値を引き出し、レポーティングツールやパートナー、顧客に送信することができます。Snowflake Summit 2022では他にも、Snowpipeストリーミング(現在プライベートプレビュー中)に関する最新情報や、行セットの低遅延ストリーミング向けのストリーミングフレームワークに基づいて構築された新しいKafkaコネクタ(現在プライベートプレビュー中)についての発表もありました。

本ブログシリーズでは、取り込みオプションについて取り上げ、それぞれのベストプラクティスを紹介します。まず、データ取り込みの最もシンプルな方法であるINSERTコマンドから説明しましょう。この方法は、小ボリュームのデータ取り込みに最適なアプローチであり、10 MB以上になるような大規模なデータセットの場合は、特に使いやすさ、拡張性、エラー処理において限界があります。大規模なデータセットの場合、データエンジニアは通常、さまざまなETL/ELTツールを使用してデータを取り込むか、COPY INTOやSnowpipeと併せて、中継ステップとしてオブジェクトストレージを使用する人もいます。データをストリーミングし、人気の高いKafkaベースのアプリケーションを使用する必要のあるお客様は、Snowflake Kafkaコネクタを使用し、Snowpipeを介してKafkaトピックをSnowflakeテーブルに取り込むことができます。さらにSnowflakeでは、外部テーブルオプションを使用してデータエンジニアが外部ステージに保存されたデータをクエリすることもできます。利用可能なすべての取り込みオプションの詳細や、対応する幅広いユースケースについては今後のブログ記事で取り上げていきます。
本記事では、最も幅広く使用されており、推奨される2つのファイルベースのデータ取り込みアプローチ、COPY INTOとSnowpipeについて取り上げます。これらの2つのアプローチの類似点と相違点、さらにSnowflakeデータクラウドへのデータ取り込みを行っている5,000社を超えるお客様の経験から得られたお薦めのベストプラクティスをご紹介します。
COPY INTOとSnowpipeの比較
COPYコマンドは、外部クラウドストレージやSnowflakeの内部ステージにあるバッチデータの読み込みを可能にします。このコマンドは、事前定義された、顧客が管理する仮想ウェアハウスを使用してリモートストレージからデータを読み込み、オプションとして構造を変換し、ネイティブのSnowflakeテーブルに書き込みます。
これらのオンザフライ変換には以下が含まれます。
- 列の並べ替え
- 列の省略
- キャスト
- テキストの省略
COPYは、SELECTクエリやデータトランスフォーメーションといったさまざまなワークロードのパフォーマンスに対しピーク価格を達成するために、規模や中断/再開に合わせて1つ以上のウェアハウスが管理されている既存のインフラストラクチャに最適です。
COPYでは、ファイルの部分データは初期設定のON_ERRORオプションにより読み込まれないため、ファイルレベルのトランザクション粒度が得られます。Snowpipeでは、データの遅延性や可用性向上のためにマイクロバッチチャンクでファイルをコミットできるためこのような保証は行われません。連続してデータを読み込む際、ファイルは単なるひとかたまりの因子にすぎず、トランザクションを制限する要因とはなりません。
Snowpipeは連続取り込み用に設計されており、COPYを基に構築されていますが、ドキュメンテーションに一覧を記したように、詳細なセマンティックにはいくつかの相違点があります。COPYとは対照的に、Snowpipeはサーバーレスサービスを実行します。つまり、管理が必要な仮想ウェアハウスが存在しないということです。ここでは、Snowflakeによって管理されているリソースがワークロードに合わせて自動的にスケーリングされます。そのため、ウェアハウスの管理、変化する処理量に合わせたスケーリング、コストパフォーマンスのベストバランス達成に向けた最適化、といったタスクを実行する必要がなくなります。また、ファイル読み込みの監視もSnowflakeが行うため、お客様側が実施する必要がありません。
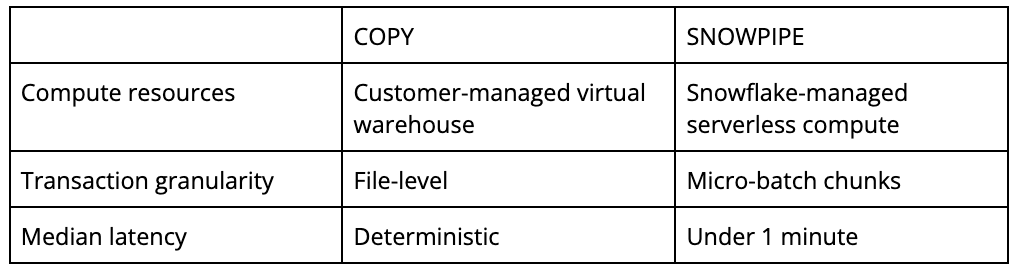
COPYに関する考慮事項
COPYコマンドは顧客が管理するウェアハウスに依存しているため、適切なウェアハウスサイズを選択する際に考慮すべき事項があります。各スレッドが一度に単一のファイルを取り込むため、並列処理のレベルは非常に重要な点となります。XSサイズのウェアハウスは8つのスレッドを提供し、サイズが1つ大きくなるごとに利用可能なスレッドの数が倍増します。最も簡潔な結論としては、膨大な数のファイルに対しては、それぞれのウェアハウスサイズにおいて最適な並列処理が行われるため、サイズを1段階上げるごとに大量のファイル取り込みにかかる時間は半分になるということです。しかし、このような時間の短縮はネットワークの状態や実際の状況におけるI/O遅延などにより制限される場合があります。大容量の取り込みを実施する際には、こういった要素も考慮すべきであり、計画段階で個別のベンチマーキングが必要となるかもしれません。
ウェアハウスの分離、個別サイジング、秒単位の請求といったSnowflakeの独自機能により、個別のテーブルの並列読み込みが迅速かつ効率的に、フォールトトレラントに実行できます。ファイル数、サイズ、フォーマットが異なるテーブルソース間でも、複数テーブルの読み込みが可能です。この場合、それぞれのデータ特性に見合った適切なウェアハウスサイズを選択することをお勧めします。
Snowpipe APIと自動取り込み型Snowpipeの比較
Snowflakeが提供するサーバーレスリソースは、バッチ、マイクロバッチ、連続といったあらゆる処理タイプを実行できます。
ほとんどのユースケース、特にSnowflake内のデータのインクリメンタル更新には、自動取り込み型Snowpipeがお薦めです。このアプローチではソースバケット内に新たに作成されたファイルに反応し、新たなデータを継続的にターゲットテーブルに読み込みます。
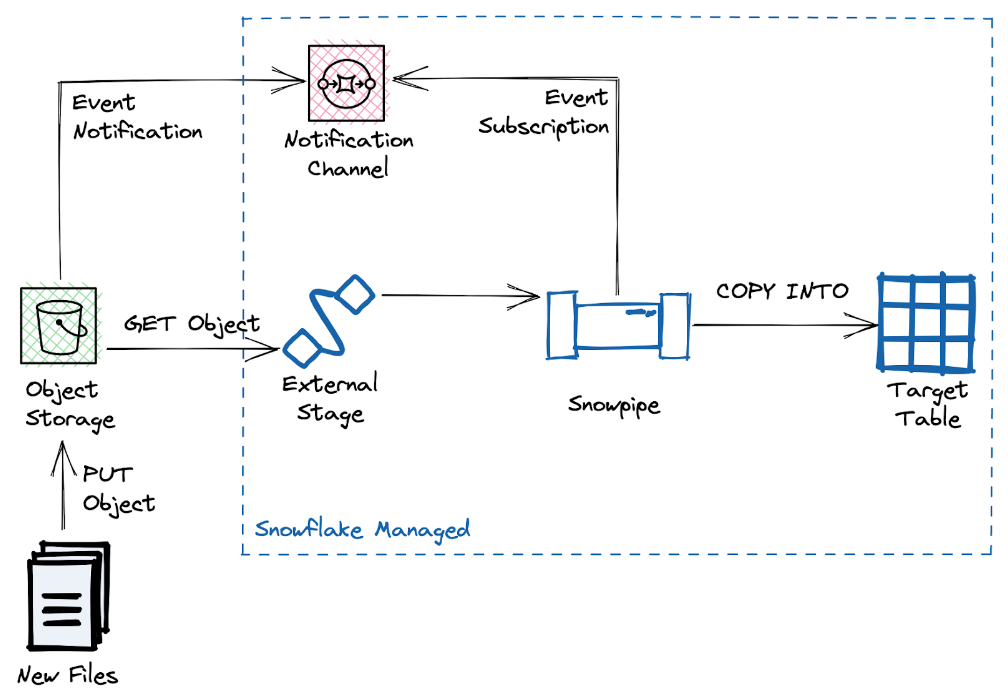
Snowpipeは、WS SQSやSNS、Azure Event Grid、またはGCP Pub/Subといったイベント分散においてクラウドベンダー固有のシステムに依存しています。この設定では、ソースバケットからSnowpipeへのイベント通知を実行するために、クラウドアカウントに対応する権限が付与されている必要があります。
イベントサービスが設定できない場合、また既存のデータパイプラインインフラストラクチャが存在する場合はいつでも、REST APIで起動するSnowpipeで代替できます。未加工ファイルの保存用に内部ステージを使用している場合、いまのところ、この方法が唯一の代替手段となっています。通常、REST APIアプローチは、エンドユーザー側にオブジェクトストレージ作成の負荷がかかることを避け、代わりにSnowflakeが管理する内部ステージを使用するETL/ELTツールで使用されます。
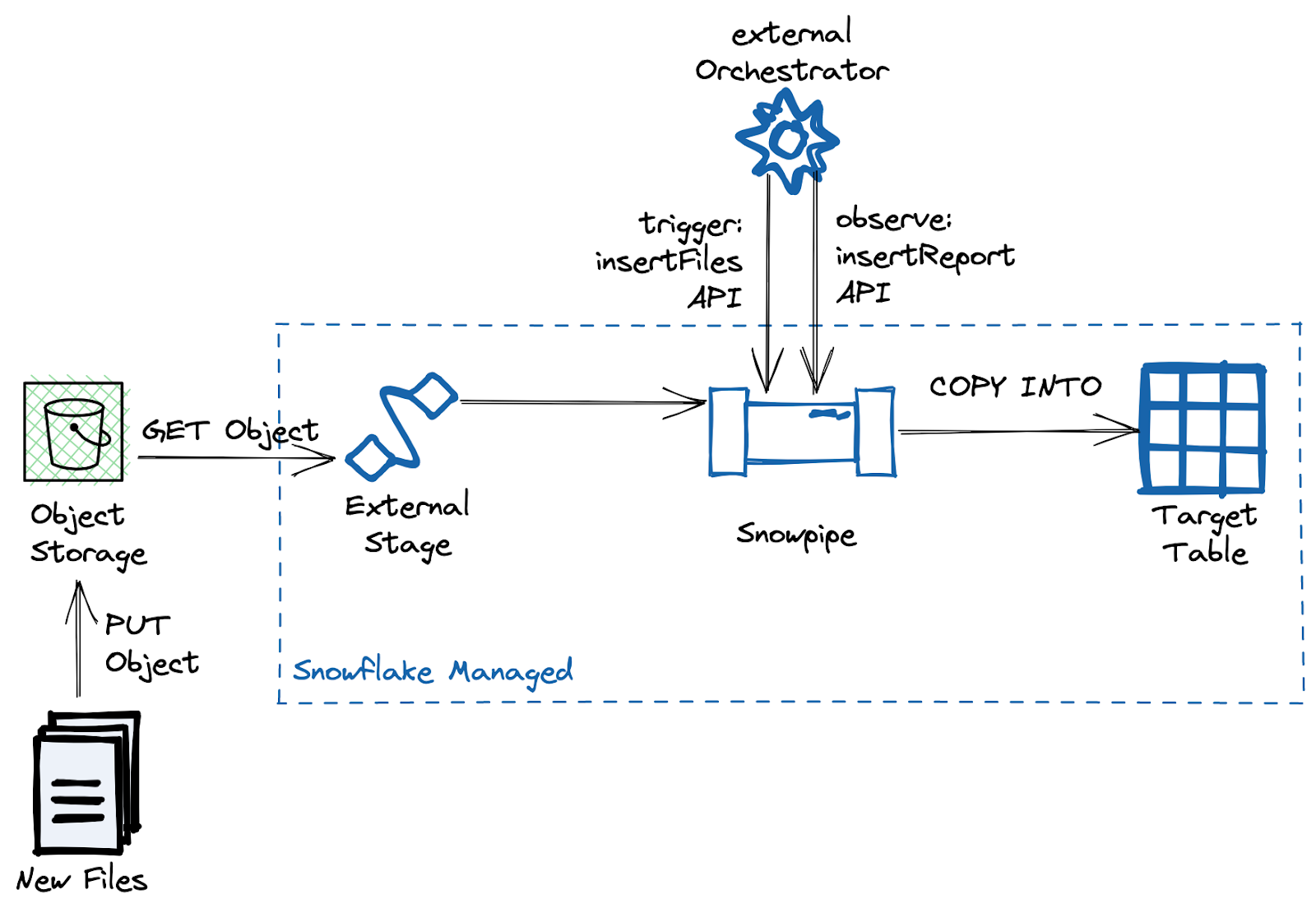
データ取り込みのためにSnowpipe APIをトリガーする例はこちらをご覧ください。https://medium.com/snowflake/invoking-the-snowpipe-rest-api-from-postman-141070a55337
取り込み状況の確認
COPY INTOはアウトプットとしてロードステータスを返す同期処理です。けれどもSnowpipeでは、ファイルの取り込みの実行は非同期的に行われるため処理のステータスを明示的に監視する必要があります。
すべてのSnowpipesおよびCOPY INTOについて、COPY_HISTORYビューまたはより低い遅延のCOPY_HISTORY関数が利用できます。一般的に、ロードに失敗したファイルは誰かが確認する必要があるため、COPY_HISTORYを確認する頻度は、通常のファイル到着率よりも低くした方が良い場合が多くなります。すべてのSnowpipeにおいて、選択したイベントハンドラーへのイベント発行にエラー通知が利用できます(AWS SNS、Azure Event Grid、GCP Pub/Sub)。
さらにAPIトリガー型Snowpipeでは、insertReportやloadHistoryScan APIエンドポイントを使用して取り込みを追跡することができます。insertReportエンドポイントは直近10分間のみのイベントを返しますが、この制約はloadHistoryScanエンドポイントで設定可能です。いずれにしても、 loadHistoryを過剰に使用するとAPIスロットリングを引き起こしがちなため、insertReportの方を使用することをお勧めします。
初期データロード
本シリーズで紹介した3つのオプションは、初期データロードでも使用可能です。他のユースケース同様、それぞれのオプションにメリットとデメリットがあります。まずは、そのシンプルさと拡張性から、自動取り込みの評価から始めることをお勧めします。
Snowpipeの自動取り込みは、新たなファイル通知に依存します。お客様がよく陥る状況としては、必要な通知を取得できないことです。これは、通知チャネルが構成される前にすべてのファイルがバケット内に存在するケースです。これを解決するいくつかのアプローチがあります。最近の例としては、初期データロードとして数百TBのデータをロードする大手顧客をサポートしました。このケースでは、利用可能なファイルを指す通知チャネルへのフェイク通知の作成が有効でした。
このアプローチが実行不可能な場合や、小規模なバケットまたはバケットリスティングが妥当な場合、REFRESH機能を使用して取り込みをトリガーできます。
alter pipe
これにより、バケットリスティングを行い、最大7日間の、最近変更されたファイル取り込みを開始します。
初期データロードは期限が定まっている場合が多いため、COPYを実行して、手作業でモニタリングを行うことも可能です。どのアプローチを選択するかは、コントロールと自動化の兼ね合いによります。また、次のセクションで取り上げるコストに関する考慮事項も影響するかもしれません。それ以外の点では、COPYの方がウェアハウスやジョブの期間の管理責任を伴うより多くのコントロールが可能です。以下に、初期データロードにCOPYを使用する際に考慮すべき、重要な2つの点を記します。
- データスキューの場合、充分なファイルを持たないCOPYジョブは、効率的にウェアハウスを使用することができません。例えば、ロードしているファイル数が8ファイルに満たない場合、XSサイズのウェアハウスも2XLサイズのウェアハウスも処理速度は変わりません。そのため、前述のCOPYを実行する並列処理の程度を考慮することが重要です。
- 数百万のファイルをロードする単一のCOPYジョブは、実行時間が長くなる可能性がありますが、初期設定のジョブタイムアウトは24時間です。この上限に達するのを防ぐために、ジョブ全体をより小さなCOPYジョブに分割する必要があります。COPYの場合、データが存在する明示的パスからリストやロードする方がバケット全体をトラバースするより明らかに効率的なため、可能であればデータパスパーティショニングを活用することもできます。
Snowpipeで推奨されるファイルサイズおよびコストに関する考慮事項
Snowpipeでは、コンピューティングの処理コストに加え、ファイルごとに固定オーバーヘッドコストがかかります。推奨されるファイルサイズは平均10MB以上で、100~250MBのファイルが最高のコストパフォーマンス比を得ることができます。
平均ファイルサイズが1桁台のMBであったり、小容量のファイルの場合、Snowpipeが最もコスト効率の高い(クレジット/TB換算で)選択肢とは言えない場合が多いでしょう。ファイル到着率、使用するウェアハウスサイズ、クラウドサービスレイヤでのCOPYの不使用次第では、COPYの方が良いコストパフォーマンスを提供するかもしれません。そのため、10MBを下回るファイルについては唯一の正解は存在せず、さらなる分析が必要です。原則として、100MBを超える大容量のファイルサイズの場合あきらかにより効率的なため、ファイルサイズが大きくなってもクレジット/TBにはそれほど変化がありません。また、並列処理やエラー処理機能の利点を生かすためには、5GBを超えないファイルサイズを推奨しています。ファイルサイズが大きいと最後にエラーレコードが検出される可能性が高くなり、取り込みジョブが失敗する場合があります。その場合、選択したON_ERRORオプションに従って、後で再開する必要が生じます。Snowflakeははるかに大容量のファイルを処理できるため、TB規模のファイルのロードが可能です。
これらのファイルサイズに関する推奨事項に合わせ、ファイルあたりのコストは全体的なコストのほんの一部である点にも注意しておいてください。
ファイル形式
すべての取り込み方式は、一般的なファイル形式に追加設定なしで対応しています。
- CSV
- JSON
- PARQUET
- AVRO
- ORC
- XML(現在パブリックプレビュー中)
さらに、これらのファイルは圧縮ファイルとしても提供可能で、Snowflakeはこれらを取り込み処理中に解凍します。GZIP、BZ2、BROTLI、ZSTD、SNAPPY、DEFLATE、RAW_DEFLATEなどの対応している圧縮形式は、明示的な設定やSnowflakeによる自動検出が可能です。一般的に、ネットワークの外部アセットの動きも制限する要因となる可能性が高いため、非圧縮ファイルより圧縮ファイルの取り込みを推奨します。
さまざまな要素が組み合わされるため、ファイルサイズがわかっていても、特定のファイル形式の取り込みパフォーマンスを予測することは不可能です。データロードのパフォーマンスに関して、最も顕著な影響を与えたのはファイル構造(シングルレコードの列数やネストされた属性)であり、トータルのファイルサイズではありません。
とは言え、私たちの測定ではGZIPで圧縮されたCSVファイル(.csv.gz)が、最も幅広く使用されているだけでなく、通常、最も効率の良い取り込み設定であることを示唆しています。さらに、上記にリストアップしたファイル形式によるパフォーマンスは、取り込み速度が速い順であることも確認されています。
ほとんどの場合、利用可能なファイル形式やサイズはソースシステムにより事前定義されているかオブジェクトストレージデータで既に利用可能となっています。その場合、労力をかけてまで既存のファイルを異なる形式やサイズに分割、統合、再エンコードするメリットはありません。注意すべき唯一の例外がクラウドリージョンやクラウドベンダーにまたがるデータロードで、Snowflakeによる透過圧縮で出力コストを大幅に抑えることができます。
取り込みにかかる時間やコストは?
取り込みにかかる時間やコストは、以下のようなさまざまな要因に基づいて決まります。
- ファイルサイズ:コアな取り込み時間はコンテンツに関連するため、コストはレコード数やファイルサイズに比例する場合が多いですが、具体的な相関はありません。
- COPYステートメントで必要となる処理数:取り込みジョブの中には複雑なUDFを呼び出すため1行当たりの処理時間が膨大なものもあり、データサイズを正しく想定できていなければメモリ不足に陥る場合もあります。
- ファイル形式、圧縮、ネスト構造など、これらすべてが解凍やデータロードの効率性に影響を与えます。膨大な列数を持つ非圧縮ファイルが、高度にネストされたデータ構造の、少ない列数の圧縮ファイルと同じ処理時間の場合もあります。
そのため、具体的な事例を測定せずに、上記の質問に正しく答えることができません。現時点で、私たちは取り込みサービスに特化したサービス品質保証をしていないという点にご留意ください。しかし、上記要素における展開、顧客、値の範囲で、平均P95のレイテンシが約1分であることを確認しています。もちろんこの点については統計的測定であり、顧客ごと、単位時間ごとにより具体的な性能は大きく異なります。
10のベストプラクティス
- 連続ロードには自動取り込み型Snowpipeを検討してください。COPYやREST APIの方が推奨される事例については上記を参照してください。
- 初期データロードについても自動取り込み型Snowpipeを検討してください。初期データの取り込みにはCOPYとSnowpipeの組み合わせが最良の場合もあります。
- Snowflakeはあらゆるファイルサイズに対応していますが、10MB以上のファイル、できれば100~250MBのファイルを使用しましょう。ファイルサイズを1桁台のGBに維持するとエラー処理が簡素化され、無駄な作業を防ぐことができます。これはハードリミットではないため、いつでもON_ERROR = CONTINUEのようなエラー処理機能を使用できます。
- 最大フィールドサイズの上限を16MBに設定しましょう。取り込みは、16MBのSnowflake全体のフィールドサイズ制限に拘束されています。
- ファイルの分割、統合、転換を行わず、データをそのままの状態で取り込むネイティブ機能を活用し、取り込み処理をシンプルに保ちましょう。Snowflakeはあらゆるファイルボリュームの、多数のさまざまなデータ形式や圧縮形式の取り込みに対応しています。スキーマ検出やスキーマ展開(現在プライベートプレビュー中)といった機能により構造化テーブルへの直接データロードが簡素化されます。
- 顧客間での平均測定は、遅延やコストの予測にあまり役立ちません。データのサンプルを測定する方が、指標となる数字よりもはるかに信頼できるアプローチです。
- COPY_HISTORYやSnowpipeエラー通知のようなオプションを使用して、Snowpipeでのファイルロードの成功/失敗を確認しましょう。また、適宜SYSTEM$PIPE_STATUSで、Snowpipeの健全性を確認しましょう。
- Snowpipeでは順序通りのロードを想定しないでください。ファイルロードは複数のチャンクで非同期に同時実行されるため、並べ替えが可能です。オーダリングが不可欠の場合、可能であればデータのイベントタイムスタンプを使用するか、COPYを使用してシーケンシャルにロードしましょう。
- COPYでは、可能な限り、既存のオブジェクトパスパーティショニングを活用しましょう。最も明示的なパスを使用することで、COPYは、できるだけ迅速かつ効率的にデータのリストやロードを行います。Snowflakeは、大容量データのスケーラブルなリストやロードが可能ですが、特に以前の日、月、年データをロード済みの場合、パスパーティショニングを使用することで、これらを無視して重複排除し、無駄なコンピュートやAPIコールを防止できます。
- クラウドプロバイダーのイベントフィルタリングを使用して、Snowpipeへの送信前にプレフィックスまたはサフィックスでフィルタリングし、不要な通知による通知ノイズ、取り込み遅延、コストを低減しましょう。Snowpipeのより強力なRegExパターンフィルタリングを使用する前に、ネイティブなクラウドイベントフィルタリングを活用しましょう。
何千人もの顧客やデベロッパーがこれらのベストプラクティスを使用してSnowflakeに膨大な量のデータを取り込み、データからインサイトや価値を創出しています。どの取り込み方法を選択するにしても、Snowflakeは、データパイプラインにおけるビジネス要件に対応するため、常に性能や機能の向上に努める所存です。本記事では、COPYやSnowpipeによるファイルベースのデータ取り込みを取り上げましたが、ブログのパート2では、ストリーミングデータ取り込みを取り上げます。
著者

