Snowflake Arctic, o melhor LLM para IA corporativa: inteligente, eficiente e realmente aberto

Tradicionalmente, a criação de inteligência corporativa de alto nível com o uso de grandes modelos de linguagem (large language models, LLMs) tem sido excessivamente cara, podendo custar de dezenas a centenas de milhões de dólares, e consumido muitos recursos. Como pesquisadores, há anos enfrentamos as restrições de treinar e inferir LLMs de maneira eficiente. Os membros da equipe de pesquisa de inteligência artificial (IA) da Snowflake foram pioneiros em sistemas como ZeRO e DeepSpeed, PagedAttention/vLLM e LLM360, que reduziram em muito o custo de treinamento e inferência de LLMs, e os disponibilizaram em código aberto para tornar os LLMs mais acessíveis e econômicos para a comunidade.
Agora, a equipe de pesquisa de IA da Snowflake tem o prazer de apresentar o Snowflake Arctic, um LLM corporativo de alto nível que amplia as fronteiras de abertura e treinamento econômico. O Arctic é eficientemente inteligente e realmente aberto.
- Eficientemente inteligente: o Arctic se destaca em tarefas corporativas, como geração de SQL, codificação e instrução, seguindo benchmarks do setor, mesmo quando comparado a modelos de código aberto treinados com orçamentos de processamento bem mais altos. Na verdade, ele estabelece um novo parâmetro para um menor custo de treinamento, permitindo que os clientes Snowflake criem modelos personalizados de alta qualidade para suas necessidades corporativas a um baixo custo.
- Realmente aberto: a licença Apache 2.0 dá acesso ilimitado a pesos e códigos. Além disso, também estamos disponibilizando em código aberto todas as nossas receitas de dados e insights de pesquisa.
Atualmente, o Snowflake Arctic está disponível no Hugging Face, catálogo de API NVIDIA e Replicate. Futuramente, ele estará disponível em seu model garden ou catálogo de preferência, incluindo Snowflake Cortex, Amazon Web Services (AWS), Microsoft Azure, Lamini, Perplexity e Together AI.
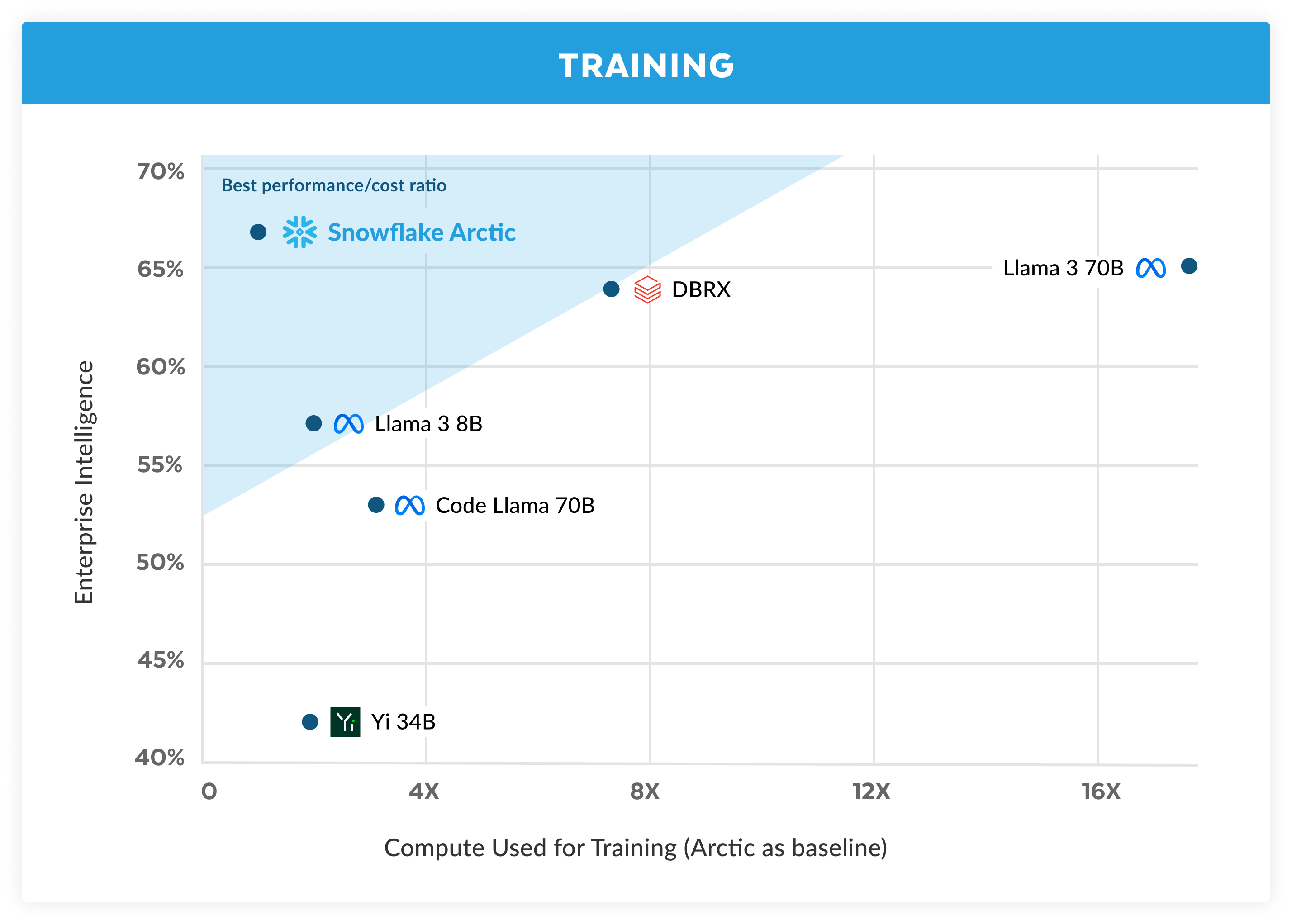
Inteligência corporativa de alto nível a um custo de treinamento incrivelmente baixo
Na Snowflake, observamos um padrão consistente nas necessidades de IA e nos casos de uso de nossos clientes corporativos. As empresas querem usar LLMs para criar copilotos de dados SQL conversacionais, copilotos de código e chatbots de geração aumentada de recuperação (retrieval augmented generation, RAG). Do ponto de vista das métricas, isso se traduz em LLMs que se destacam em SQL, código, capacidade de seguir instruções complexas e de produzir respostas fundamentadas. Capturamos essas habilidades em uma única métrica que chamamos de inteligência corporativa, obtendo uma média de codificação (HumanEval+ e MBPP+), geração de SQL (Spider) e capacidade de seguir instruções (IFEval).
Entre os LLMs de código aberto, o Arctic oferece inteligência corporativa de alto nível e faz isso usando um orçamento de processamento para seu treinamento de menos de US$ 2 milhões, o que representa menos de 3.000 semanas de unidades de processamento gráfico (graphics processing units, GPUs). Isso significa que o Arctic tem mais capacidade do que outros modelos de código aberto treinados com um orçamento de processamento semelhante. Sem contar que ele se destaca em inteligência corporativa, mesmo quando comparado a modelos treinados com um orçamento de processamento bem maior. A alta eficiência de treinamento do Arctic também significa que os clientes Snowflake e a comunidade de IA em geral podem treinar modelos personalizados de forma muito mais econômica.
Em termos de métricas corporativas, conforme exposto na figura 1, o Arctic está no mesmo nível ou supera o LLAMA 3 8B e o LLAMA 2 70B, ao passo que consome menos da metade do orçamento de processamento de treinamento. Da mesma forma, apesar de usar 17 vezes menos orçamento de processamento, o Arctic está no mesmo nível do Llama3 70B em métricas corporativas como codificação (HumanEval+ e MBPP+), SQL (Spider) e capacidade de seguir instruções (IFEval). Ele faz isso ao mesmo tempo em que se mantém competitivo em termos de desempenho geral. Por exemplo, apesar de usar sete vezes menos capacidade de processamento do que o DBRX, o Arctic continua competitivo em termos de compreensão e raciocínio linguístico (um conjunto de 11 métricas), enquanto é melhor em matemática (GSM8K). Para obter uma análise detalhada dos resultados para cada benchmark, consulte a seção Métricas.
Eficiência de treinamento
Para atingir esse nível de eficiência de treinamento, o Arctic usa uma arquitetura exclusiva de transformers híbridos Dense-MoE. Ele combina um modelo de dense transformer com 10 bilhões de parâmetros, com uma rede perceptron multicamadas (multilayer perceptron, MLP) residual de 128 x 3,66 bilhões de MoE, resultando em um total de 480 bilhões de parâmetros e 17 bilhões de parâmetros ativos escolhidos usando um gating top-2. O Arctic foi desenvolvido e treinado usando os três principais insights e inovações a seguir:
1) Muitos especialistas, porém concentrados, com mais opções de escolha: no final de 2021, a equipe do DeepSpeed demonstrou que o modelo de mistura de especialistas (mixture of experts, MoE) pode ser aplicado a LLMs autorregressivos para melhorar significativamente a qualidade do modelo sem aumentar o custo de processamento.
Ao desenvolver o Arctic, percebemos, com base no exposto acima, que a melhoria da qualidade do modelo dependia principalmente do número de especialistas e do número total de parâmetros no modelo MoE, além do número de combinações possíveis com esses especialistas.
Com base nesse insight, o Arctic foi desenvolvido para ter 480 bilhões de parâmetros distribuídos entre 128 especialistas altamente selecionados e usa um gating top-2 para escolher 17 bilhões de parâmetros ativos. Em contrapartida, modelos MoE recentes são criados com um número significativamente menor de especialistas, conforme mostrado na tabela 2. Intuitivamente, o Arctic utiliza um grande número de parâmetros totais e muitos especialistas para ampliar a capacidade do modelo de obter inteligência de alto nível, enquanto escolhe criteriosamente entre muitos especialistas, porém concentrados, e utiliza um número moderado de parâmetros ativos para treinamento e inferência eficientes em termos de recursos.
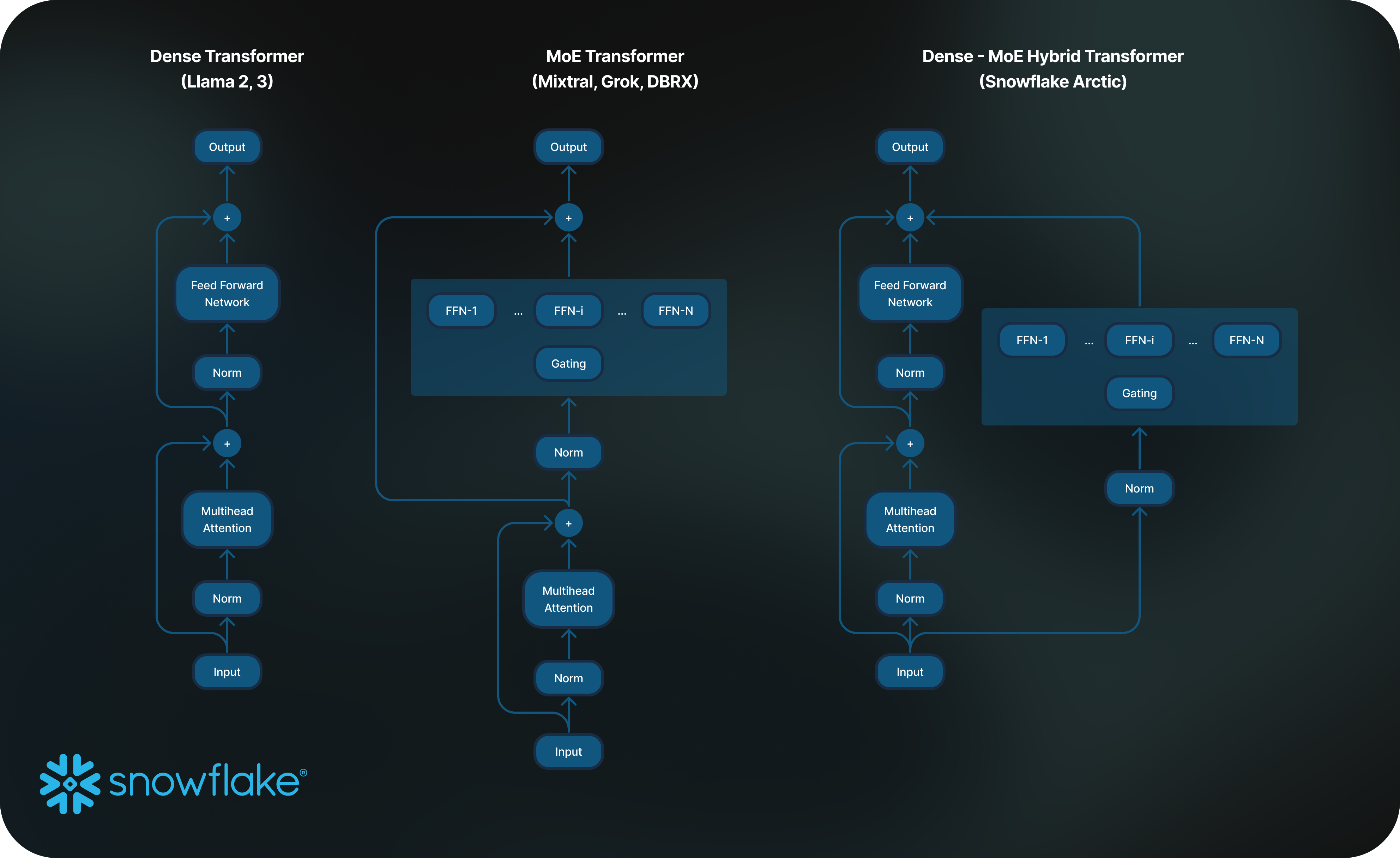
2) Design colaborativo de arquitetura e sistema: o treinamento de uma arquitetura MoE padrão com um grande número de especialistas é muito ineficiente, mesmo nos hardwares de treinamento de IA mais avançados, devido à alta sobrecarga de comunicação entre todos os especialistas. No entanto, é possível ocultar essa sobrecarga se a comunicação puder ser sobreposta ao processamento.
Nosso segundo insight indica que a combinação de um dense transformer com um componente MoE residual (figura 2) na arquitetura do Arctic permite que nosso sistema de treinamento obtenha uma boa eficiência de treinamento por meio da sobreposição de processamento de comunicação, ocultando uma grande parte da sobrecarga de comunicação.
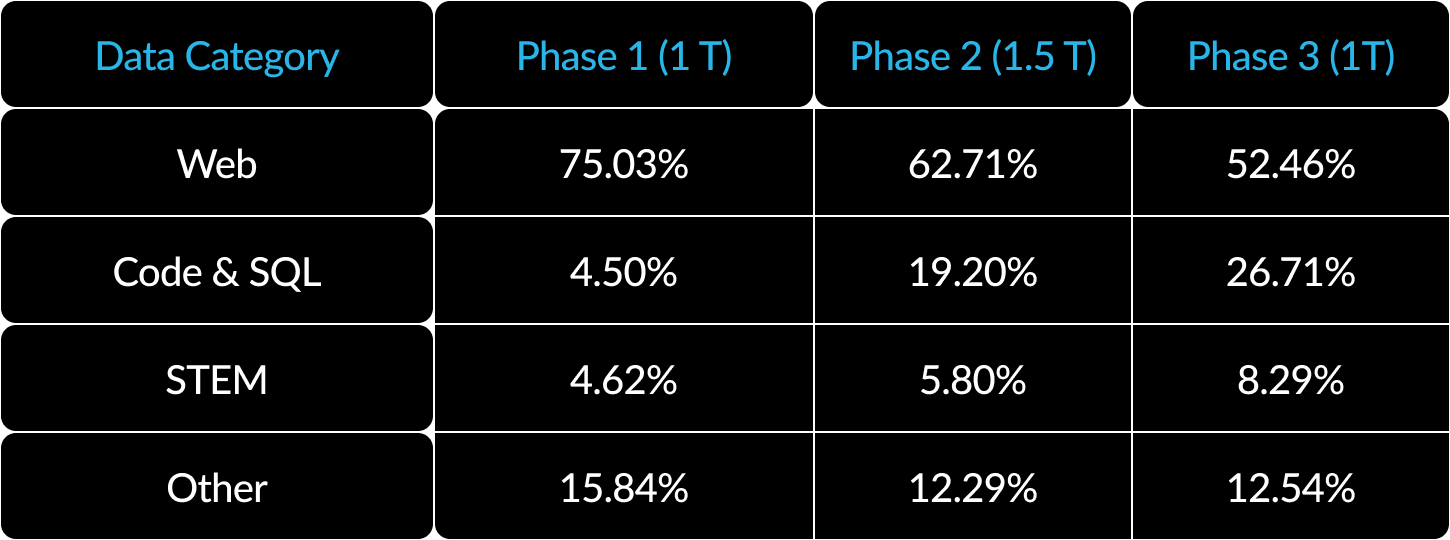
3) Currículo de dados com foco corporativo: a excelência em métricas corporativas, como geração de código e SQL, requer um currículo de dados muito diferente dos modelos de treinamento para métricas genéricas. Ao longo de centenas de ablações em pequena escala, aprendemos que habilidades genéricas, como raciocínio de senso comum, podem ser aprendidas no início, enquanto métricas mais complexas, como codificação, matemática e SQL, podem ser aprendidas de forma eficaz na última parte do treinamento. Os seres humanos são apresentados aos recursos educacionais da mesma maneira, ou seja, adquirindo habilidades simples antes das mais complexas. Dessa forma, o Arctic foi treinado com um currículo de três estágios, cada um com uma composição de dados diferente, concentrando-se em habilidades genéricas na primeira fase (tokens de 1T) e em habilidades voltadas para empresas nas duas últimas fases (tokens de 1.5T e 1T). Confira aqui um resumo de alto nível do nosso currículo dinâmico.
Eficiência de inferência
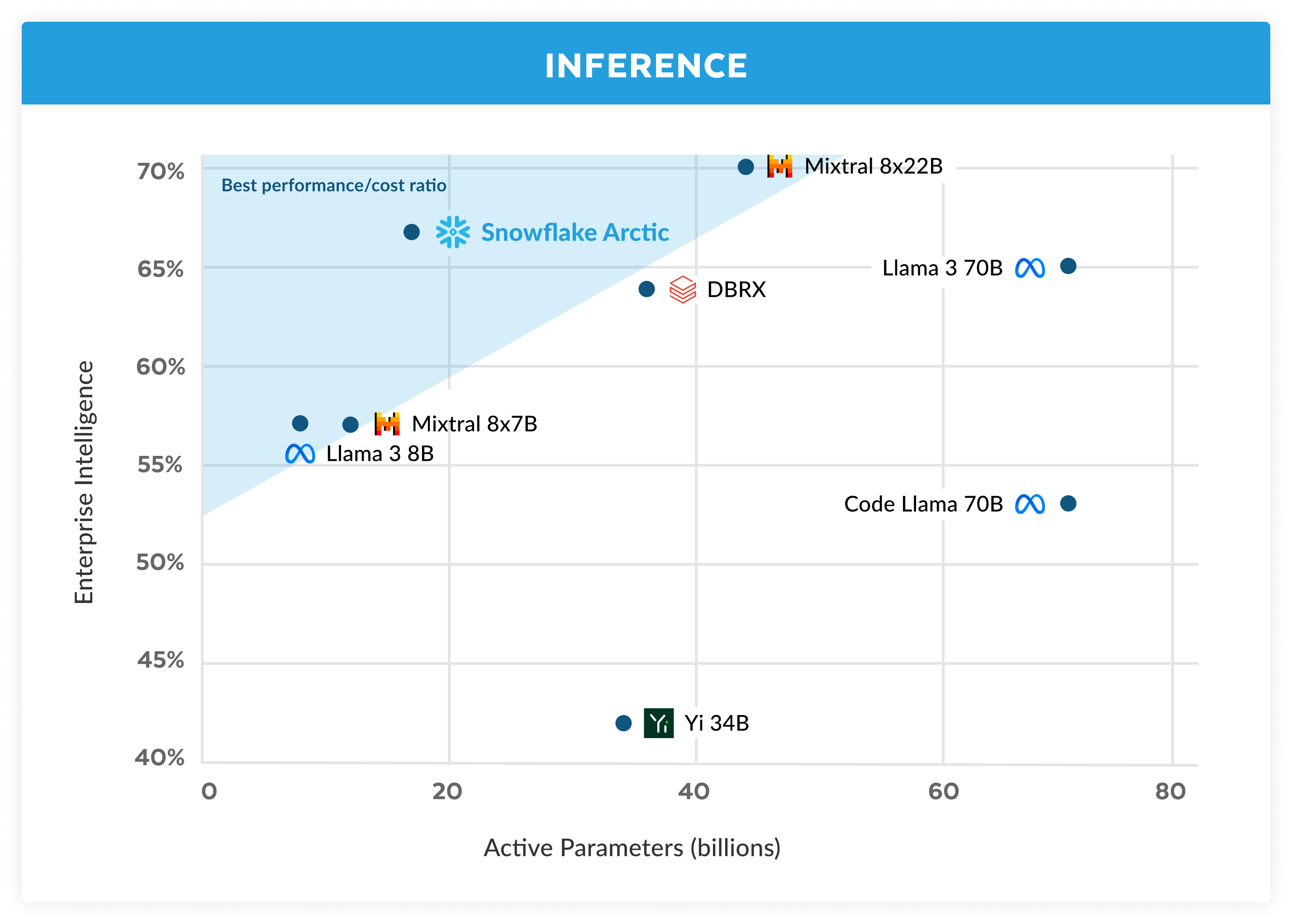
A eficiência do treinamento representa apenas um lado da inteligência eficiente do Arctic. Da mesma forma, a eficiência da inferência é essencial para permitir a implementação prática do modelo a um custo baixo. O Arctic representa um salto na escala do modelo MoE, usando mais especialistas e parâmetros totais do que qualquer outro modelo MoE autorregressivo de código aberto. Sendo assim, são necessários vários insights e inovações do sistema para executar a inferência no Arctic de forma eficiente:
a) Na inferência interativa de um tamanho de lote pequeno, por exemplo, tamanho de lote de 1, a latência de inferência de um modelo MoE é prejudicada pelo tempo necessário para ler todos os parâmetros ativos, onde a inferência é limitada pela largura de banda da memória. Nesse tamanho de lote, o Arctic (com 17 bilhões de parâmetros ativos) pode ter até quatro vezes menos leituras de memória do que o Code-Llama com 70 bilhões de parâmetros ativos e até 2,5 vezes menos do que o Mixtral com 8x22 bilhões de parâmetros ativos (totalizando 44 bilhões), o que resulta em um desempenho de inferência mais rápido.
Colaboramos com a NVIDIA e trabalhamos com as equipes da NVIDIA TensorRT-LLM e do vLLM para fornecer uma implementação preliminar do Arctic para inferência interativa. Com a quantização FP8, podemos encaixar o Arctic em um único nó de GPU. Embora esteja longe de ser totalmente otimizado, o Arctic, com um tamanho de lote de 1, tem uma taxa de transferência de mais de 70 tokens/segundo para fornecer um serviço interativo eficaz.
b) À medida que o tamanho do lote aumenta significativamente, por exemplo, milhares de tokens por passagem, o Arctic deixa de ser limitado pela largura de banda da memória e passa a ser limitado pelo processamento, onde a inferência é limitada pelos parâmetros ativos por token. Nesse ponto, o Arctic suporta quatro vezes menos processamento do que o CodeLlama 70B e o Llama 3 70B.
Para ativar a inferência limitada por processamento e uma alta taxa de transferência relativa que corresponda ao pequeno número de parâmetros ativos no Arctic (como mostrado na figura 3), é necessário um tamanho de lote grande. Para isso, é necessário ter memória cache KV suficiente para suportar o tamanho grande do lote e, ao mesmo tempo, ter memória suficiente para armazenar quase 500 bilhões de parâmetros para o modelo. Embora desafiador, isso pode ser alcançado com a inferência de dois nós usando uma combinação de otimizações de sistema, como pesos FP8, divisão-fusão e processamento contínuo, paralelismo de tensor dentro de um nó e paralelismo de pipeline entre nós.
Trabalhamos em estreita colaboração com a NVIDIA para otimizar a inferência para os microsserviços NVIDIA NIM com tecnologia do TensorRT-LLM. Em paralelo, estamos trabalhando com a comunidade vLLM, e nossa equipe de desenvolvimento interna também está habilitando a inferência eficiente do Arctic para casos de uso corporativos nas próximas semanas.
Realmente aberto
O Arctic foi construído com base nas experiências coletivas de nossa equipe, que é bem diversa, bem como nos principais insights e aprendizados da comunidade. A colaboração aberta é fundamental para a inovação, e o desenvolvimento do Arctic não teria sido possível sem o código aberto e os insights de pesquisa aberta da comunidade. Somos gratos à comunidade e estamos ansiosos para poder retribuir com nossos próprios aprendizados a fim de enriquecer o conhecimento coletivo e capacitar outros usuários para o sucesso.
Nosso compromisso com um ecossistema realmente aberto vai além de pesos e códigos abertos, mas refere-se também a ter insights de pesquisa aberta e receitas de código aberto.
Insights de pesquisa aberta
A construção do Arctic ocorreu em duas trajetórias distintas: o caminho aberto, pelo qual navegamos rapidamente graças à riqueza de insights da comunidade, e o caminho difícil, representado pelos segmentos de pesquisa que não tinham insights prévios da comunidade, e que exigiram depuração intensiva e numerosas ablações.
Com o lançamento atual, não apenas revelamos o modelo, mas também compartilhamos nossos insights de pesquisa por meio de um guia abrangente que mostra as descobertas a que chegamos ao percorrer o caminho mais difícil. O guia foi projetado para acelerar o processo de aprendizagem de qualquer usuário que esteja procurando construir modelos MoE de primeira classe. Ele oferece uma combinação de insights de alto nível e detalhes técnicos específicos na elaboração de um LLM semelhante ao Arctic para que os interessados possam desenvolver a inteligência desejada de forma eficiente e econômica, guiada pelo caminho aberto e não pelo difícil.
O guia traz uma grande variedade de tópicos, incluindo pré-treinamento, ajuste fino, inferência e avaliação, e também se aprofunda em modelagem, dados, sistemas e infraestrutura. É possível ver o índice, que inclui mais de 20 assuntos. No próximo mês, vamos lançar, diariamente, as publicações correspondentes no blog Medium.com. Por exemplo, vamos divulgar nossas estratégias para obtenção e refinamento de dados da web em um artigo sobre "que dados utilizar?" Vamos discutir nossa composição de dados e currículo em um artigo mostrando "como compor dados". Nossa pesquisa das variações da arquitetura do MoE será detalhada em uma publicação sobre "arquitetura avançada do modelo MoE", que vai falar sobre o design colaborativo da arquitetura do modelo e o desempenho do sistema. E, para os curiosos sobre a avaliação de LLM, nosso artigo sobre "como avaliar e comparar a qualidade do modelo (é menos simples do que você pensa)" vai esclarecer as complexidades inesperadas que encontramos.
Nosso objetivo com essa iniciativa é contribuir para uma comunidade aberta onde o aprendizado coletivo e o avanço sejam as normas para ampliar as fronteiras desse campo.
Serviço de código aberto
- Estamos lançando pontos de verificação do modelo para as versões básica e instruída do Arctic sob uma licença Apache 2.0. Isso significa que você pode usá-los livremente em suas próprias pesquisas, protótipos e produtos.
- Nosso pipeline de ajuste fino baseado na adaptação de baixo risco (low rank adaptation, LoRA), completo com uma receita, permite o ajuste eficiente do modelo em um único nó.
- Em colaboração com NVIDIA TensorRT-LLM e vLLM, estamos desenvolvendo implementações iniciais de inferência para o Arctic, otimizadas para uso interativo com um tamanho de lote de 1. Estamos animados de trabalhar com a comunidade para lidar com as complexidades da inferência de tamanho de lote grande de modelos MoE realmente grandes.
- O Arctic é treinado usando uma janela de contexto de atenção de 4 mil. Estamos desenvolvendo uma implementação de janela deslizante baseada em dissipadores de atenção para oferecer suporte à capacidade ilimitada de geração de sequências nas próximas semanas. Esperamos trabalhar com a comunidade para estender para uma janela de atenção de 32 mil em um futuro próximo.
Métricas
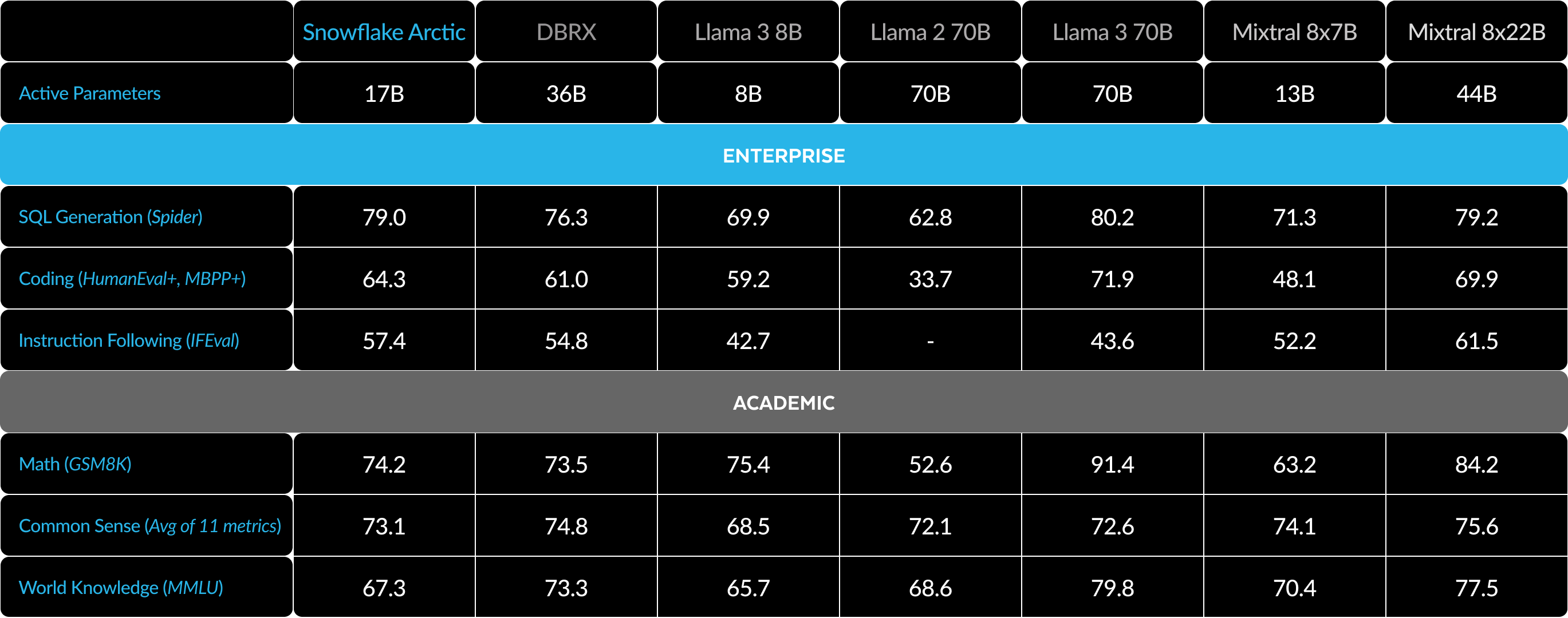
Sob o ponto de vista das métricas, nosso foco tem sido principalmente no que chamamos de métricas de inteligência corporativa, um conjunto de habilidades que são essenciais para os clientes corporativos, incluindo codificação (HumanEval+ e MBPP+), geração de SQL (Spider) e capacidade de seguir instruções (IFEval).
Ao mesmo tempo, também é importante analisar os LLMs com base nas métricas que a comunidade de pesquisa utiliza para avaliá-los. Isso inclui conhecimentos gerais, raciocínio de senso comum e capacidades matemáticas. Chamamos essas métricas de benchmarks acadêmicos.
Veja, a seguir, uma comparação do Arctic com vários modelos de código aberto nas métricas enterprise (corporativas) e academic (acadêmicas):
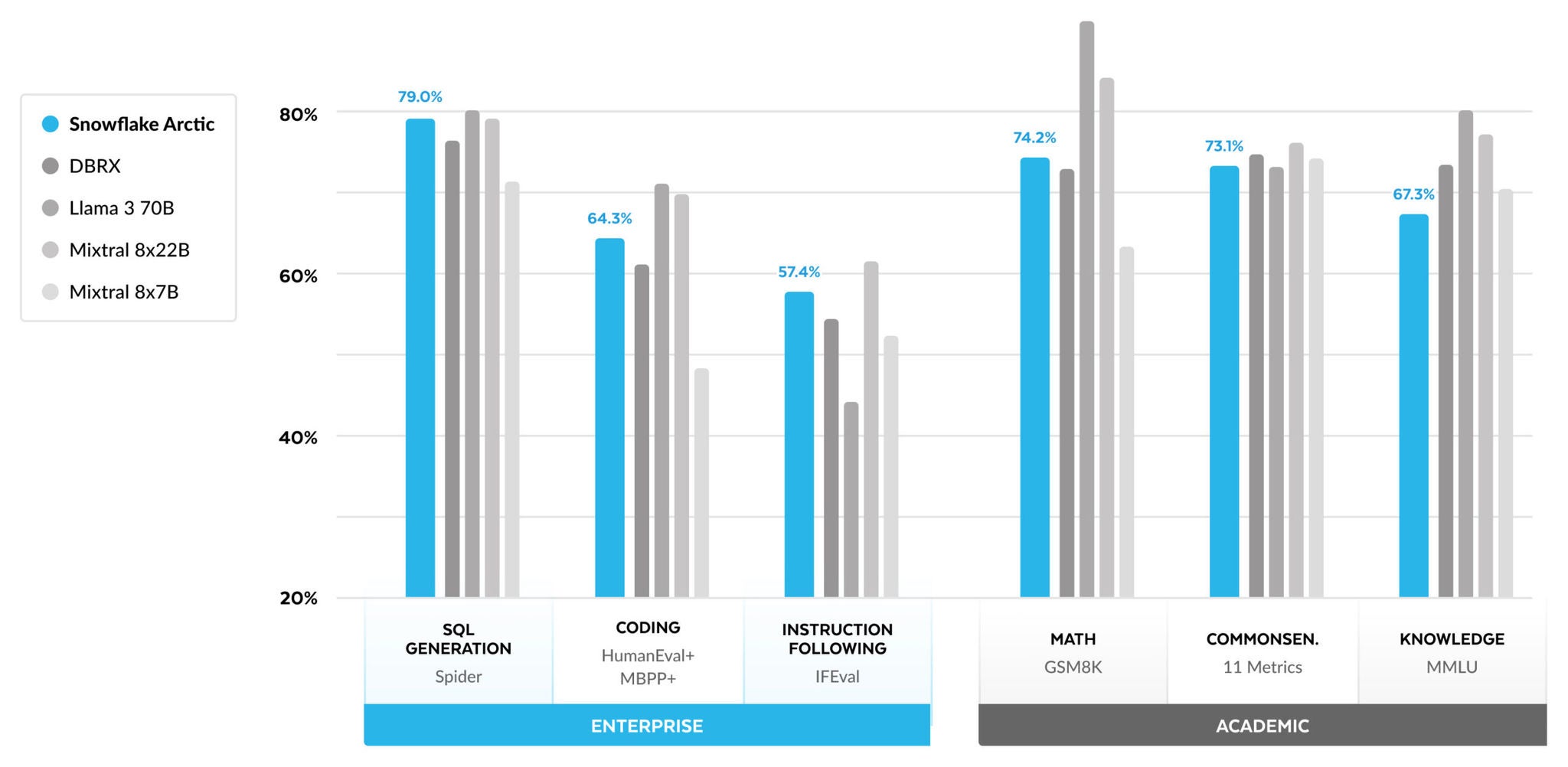
Para métricas Enterprise, o Arctic demonstra desempenho de alto nível em comparação com todos os outros modelos de código aberto, independentemente da classe de processamento. Em relação a outras métricas, ele atinge um desempenho de alto nível em sua classe de processamento e permanece competitivo até mesmo em relação a modelos treinados com orçamentos de processamento mais altos. O Snowflake Arctic é o melhor modelo de código aberto para casos de uso corporativo prontos para uso. E caso você esteja buscando treinar seu próprio modelo do zero com o menor custo total de propriedade (total cost of ownership, TCO), as descrições da infraestrutura de treinamento e da otimização de sistemas em nosso guia serão muito úteis.
Para benchmarks acadêmicos, tem havido um foco em métricas de conhecimentos gerais, como a compreensão massiva de linguagem multitarefa (massive multitask language understanding, MMLU), para representar o desempenho do modelo. Com dados de alta qualidade de ciência, tecnologia, engenharia e matemática (science, technology, engineering and mathematics, STEM) e da web, a MMLU aumenta monotonicamente em função das operações de ponto flutuante por segundo (floating-point operations per second, FLOPS) de treinamento. Como um dos objetivos iniciais do Arctic era otimizar a eficiência do treinamento e, ao mesmo tempo, manter o seu orçamento baixo, uma consequência natural disso é o desempenho inferior de MMLU, quando comparado aos modelos recentes de alto nível. Seguindo esse insight, esperamos poder realizar nosso treinamento contínuo com um orçamento de processamento de treinamento maior do que o do Arctic para exceder o desempenho de MMLU dele. No entanto, o desempenho de conhecimento geral da MMLU não tem relação necessariamente com nosso foco em inteligência corporativa.
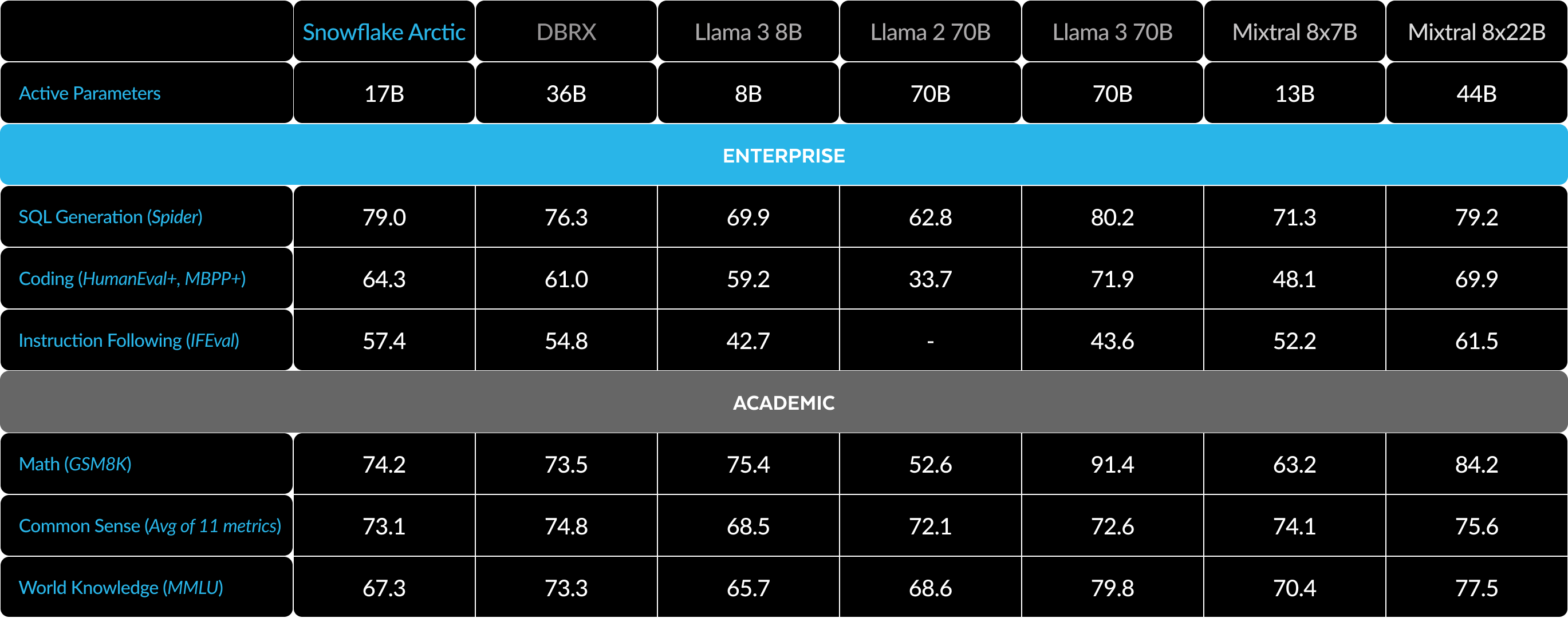
Tabela 3. Tabela completa de métricas. Comparação do Snowflake Arctic com o DBRX, LLAMA-3 8B, LLAMA-3 70B, Mixtral 8x7B, Mixtral 8x22B (variantes com ajuste por instrução ou chat, se disponíveis).1 2 3
Primeiros passos com o Arctic
Recentemente, a equipe de pesquisa de IA da Snowflake também anunciou e disponibilizou em código aberto a família de modelos Arctic Embed, que atinge o nível mais avançado (state of the art, SoTA) em recuperação de benchmark de integração massiva de texto (massive text embedding benchmark, MTEB). Queremos muito trabalhar com a comunidade para desenvolver a próxima geração da família de modelos Arctic. Para saber mais, compareça ao evento Data Cloud Summit, que acontecerá de 3 a 6 de junho de 2024.
Aqui estão algumas ideias de como podemos, hoje mesmo, começar a colaborar com o desenvolvimento do Arctic:
- Acesse Hugging Face para fazer download direto do Arctic e use nosso repositório do Github para obter informações sobre inferência e ajuste fino.
- Para uma experiência sem servidor no Snowflake Cortex, os clientes Snowflake com uma forma de pagamento registrada poderão acessar o Snowflake Arctic gratuitamente até 3 de junho. Sujeito a limites diários.
- Acesse o Arctic por meio do seu model garden ou do catálogo de sua preferência, incluindo Amazon Web Services (AWS), Lamini, Microsoft Azure, catálogo de API NVIDIA, Perplexity, Replicate e Together AI nos próximos dias.
- Converse com o Arctic! Assista a uma demonstração ao vivo agora mesmo no Streamlit Community Cloud ou no Hugging Face Streamlit Spaces, com uma API com tecnologia de nossos amigos da Replicate.
- Obtenha mentoria e créditos que ajudarão você a construir suas próprias aplicações com tecnologia do Arctic durante nosso Hackathon da comunidade com tema Arctic.
E, por fim, não se esqueça de ler a primeira edição de artigos do nosso guia para saber mais sobre como criar seus próprios modelos personalizados de MoE da maneira mais econômica possível.
Agradecimentos
Expressamos nosso agradecimento à AWS por sua colaboração e parceria na criação do cluster e da infraestrutura de treinamento do Arctic, e à NVIDIA por sua colaboração ao habilitar o suporte ao Arctic no NVIDIA NIM com TensorRT-LLM. Agradecemos também à comunidade de software de código aberto por produzir os modelos, conjuntos de dados e insights de receitas de conjuntos de dados que pudemos usar como base para tornar este lançamento possível. Também gostaríamos de agradecer aos nossos parceiros da AWS, Microsoft Azure, Lamini, Perplexity, Replicate e Together AI e do catálogo de API NVIDIA por sua colaboração na disponibilização do Arctic.
1. As 11 métricas para compreensão e raciocínio de linguagem incluem ARC-Easy, ARC-Challenge, BoolQ, CommonsenseQA, COPA, HellaSwag, LAMBADA, OpenBookQA, PIQA, RACE e WinoGrande.
2. Os pontos de avaliação HumanEval+/MBPP+ v0.1.0 foram obtidos assumindo: (1) bigcode-evaluation-harness usando modelos de bate-papo específicos do modelo, pós-processamento alinhado e (2) decodificação greedy. Para garantir consistência, avaliamos todos os modelos com o nosso pipeline. Verificamos se os resultados de nossas avaliações são consistentes com o EvalPlus leaderboard. Na verdade, nosso pipeline gera números um pouco acima do EvalPlus para todos os modelos. Isso nos garante que estamos avaliando cada modelo da melhor forma possível.
3. As pontuações IFEval relatadas são a média entre prompt_level_strict_acc e inst_level_strict_acc.
Authors
