Snowflake Arctic:エンタープライズAIに最適なLLM — 効率的にインテリジェントで真にオープン

これまで、LLMを使用してトップクラスのエンタープライズグレードのインテリジェンスを構築するには、膨大なコストとリソースが必要であり、多くの場合、数千万ドルから数億ドルのコストがかかっていました。私たちは研究者として、LLMを効率的にトレーニングし推論するという制約に長年取り組んできました。Snowflake AIリサーチチームのメンバーは、LLMのトレーニングと推論のコストを大幅に削減するZeROとDeepSpeed、PagedAttention/vLLM、LLM360などのシステムを開発し、オープンソース化して、LLMをコミュニティにとってより利用しやすく、コスト効率の高いものにしました。
本日、Snowflake AI研究チームは、Snowflake Arcticをご紹介します。Snowflake Arcticは、コスト効率の高いトレーニングとオープン性の最先端を行く、エンタープライズ向けのトップクラスのLLMです。Arcticは、効率的にインテリジェントで、真にオープンです。
- 効率的なインテリジェント:Arcticは、大幅に高いコンピューティング予算でトレーニングされたオープンソースモデルと比較しても、ベンチマークに従ってSQLの生成、コーディング、命令などのエンタープライズタスクを得意としています。Snowflakeは、Snowflakeのお客様が企業のニーズに合った高品質のカスタムモデルを低コストで作成できるように、コスト効率の高いトレーニングの新たなベースラインを確立しました。
- 真にオープン:Apache 2.0ライセンスは、重み付けとコードへの無制限のアクセスを提供します。また、すべてのデータレシピと調査インサイトをオープンソース化しています。
Snowflake Arcticは、Hugging Face、NVIDIA APIカタログ、Replicateから入手できます。また、Snowflake Cortex、Amazon Web Services(AWS)、Microsoft Azure、Lamini、Perplexity、Togetherなどのモデルガーデンやカタログから入手することもできます。
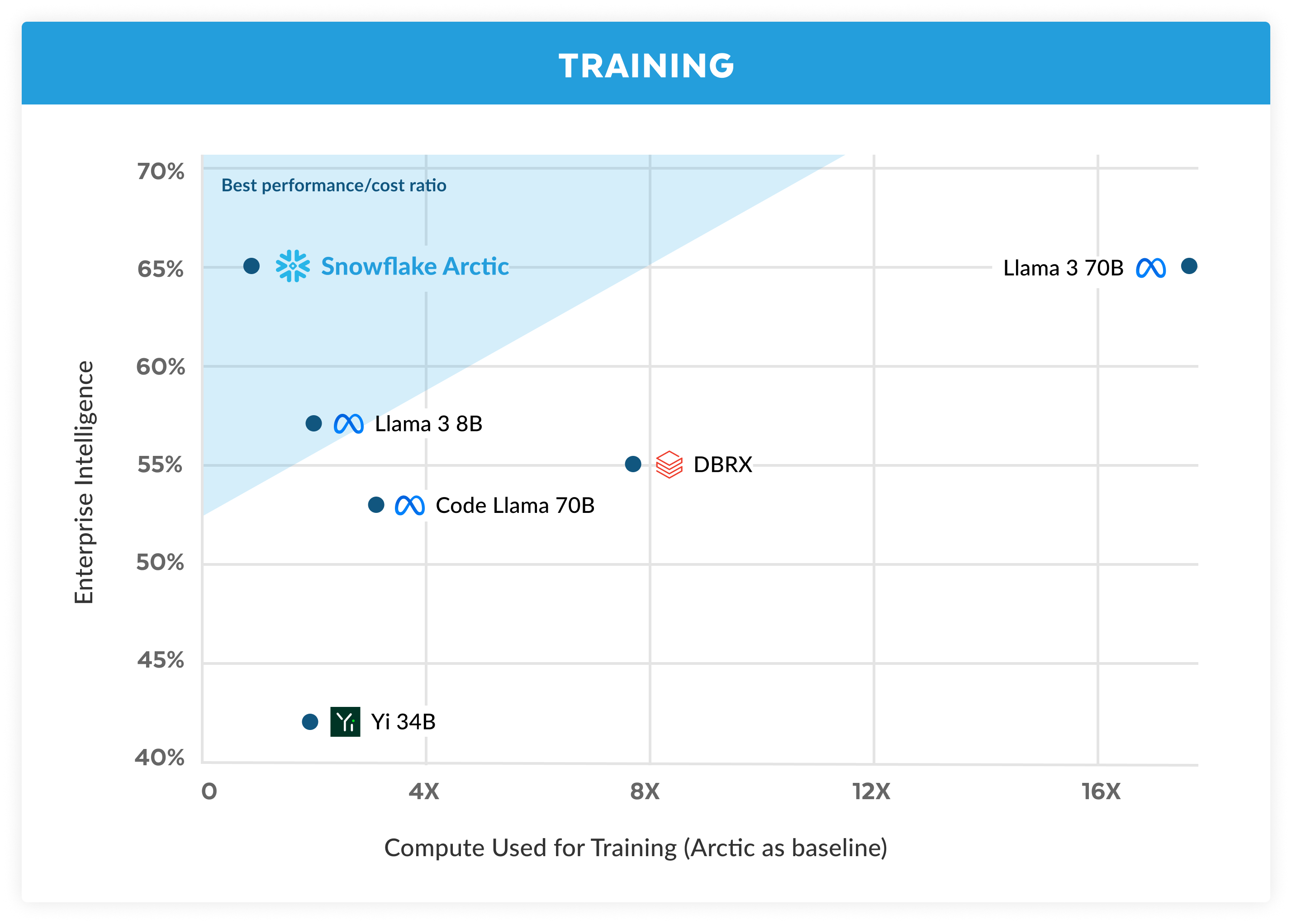
トップクラスのエンタープライズインテリジェンスを驚異的な低コストで提供
Snowflakeでは、法人顧客からのAIニーズとユースケースの一貫したパターンを目にしています。企業は、LLMを使用して会話型SQLデータコパイロット、コードコパイロット、RAGチャットボットを構築したいと考えています。メトリクスの観点からは、SQL、コード、複雑な命令フォロー、根拠のある回答を生成する能力に長けたLLMということになります。私たちは、コーディング(HumanEval+とMBPP+)、SQL生成(Spider)、命令後続(IFEval)の平均を取ることで、これらの能力をエンタープライズインテリジェンスと呼ばれる単一のメトリックに取り込みます。
Arcticは、オープンソースLLMの中でトップクラスのエンタープライズインテリジェンスを提供しており、約200万ドル(3K GPU週未満)のトレーニングコンピュート予算でこれを実現しています。これは、Snowflakeが同様のコンピューティング予算でトレーニングされた他のオープンソースモデルよりも優れていることを意味します。さらに重要なのは、エンタープライズインテリジェンスに優れていることです。これは、かなりのコンピュート予算をかけてトレーニングされたエンタープライズインテリジェンスと比較しても同様です。また、アークティックのトレーニング効率が高いため、Snowflakeのお客様やAIコミュニティ全体が、はるかに手頃な価格でカスタムモデルをトレーニングできます。
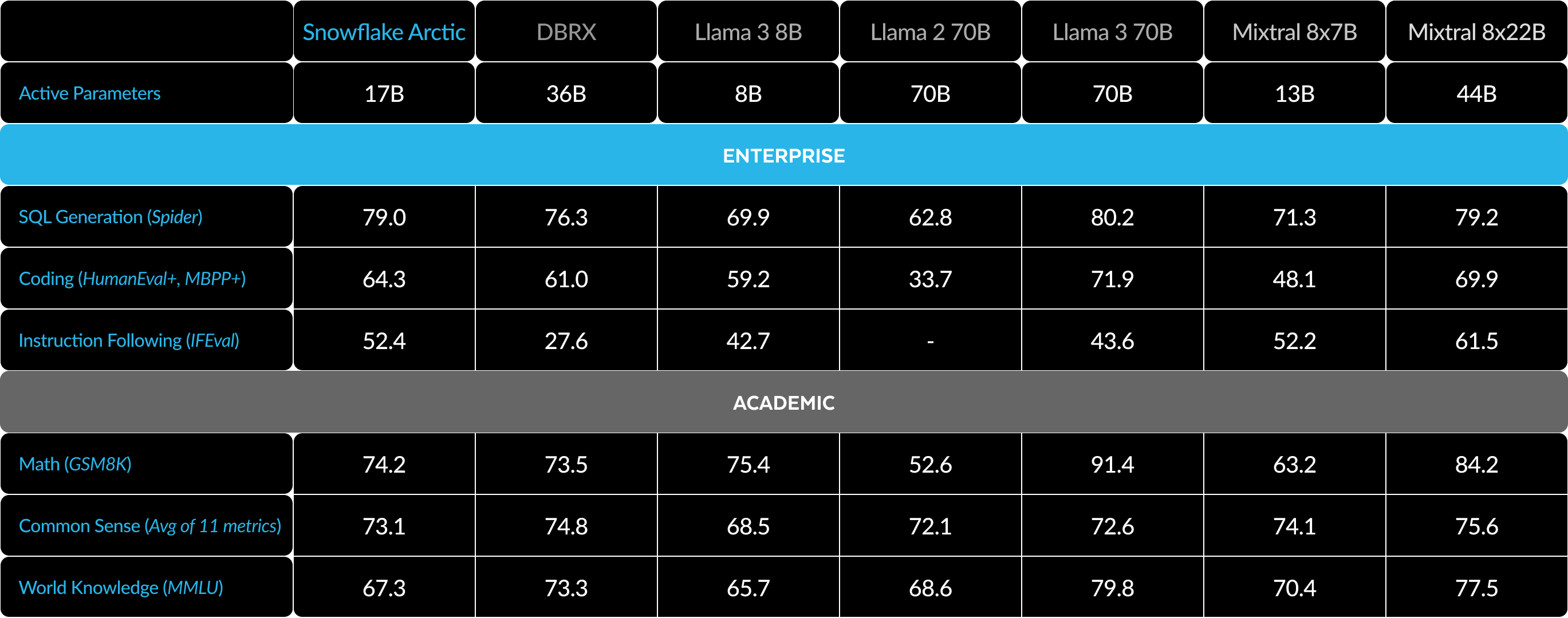
図1に示されているように、SnowflakeはエンタープライズメトリクスにおいてLLAMA 3 8BおよびLLAMA 2 70Bと同等かそれ以上であり、トレーニング用コンピュート予算の1/2以下しか使用していません。同様に、Arcticは、使用するコンピュート予算が17分の1であるにもかかわらず、コーディング(HumanEval+およびMBPP+)、SQL(Spider)、命令フォロー(IFEval)などのエンタープライズ指標においてLlama3 70Bと同等です。これにより、全体的なパフォーマンスの競争力が維持されます。たとえば、DBRXよりコンピュート使用量が7倍少ないにもかかわらず、言語理解と推論(11個のメトリクスの集合)では競争力を維持しながら、数学(GSM8K)では優れています。個々のベンチマークの結果の詳細な内訳については、「メトリクス」セクションを参照してください。
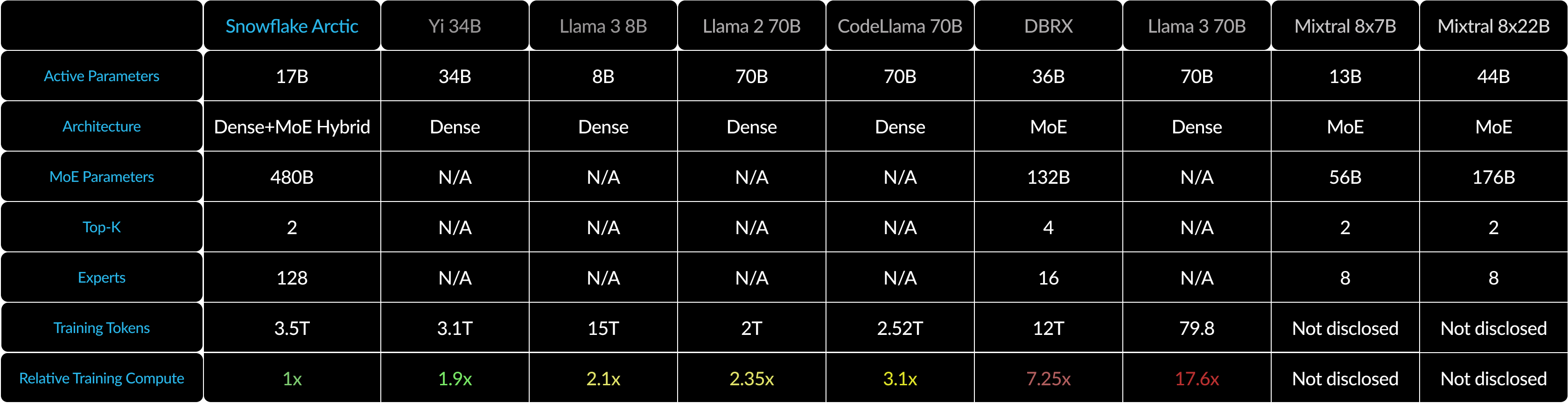
トレーニング効率
このレベルのトレーニング効率を達成するため、Arcticは独自の高密度MoEハイブリッドトランスアーキテクチャを使用しています。10Bの高密度トランスモデルと128x3.66BのMoE MLPを組み合わせ、トップ2ゲーティングで合計480B、アクティブパラメータ17Bを選定します。以下の3つの重要なインサイトとイノベーションを使用して設計およびトレーニングされています。
1)多数のエキスパートが凝縮されており、エキスパートの選択肢が多い:2021年後半、DeepSpeedチームは、MoEを自己回帰LLMに適用して、コンピューティングコストを増やすことなくモデル品質を大幅に改善できることを実証しました。
以上を踏まえ、Arcticを設計するにあたり、モデル品質の向上は、主に専門家の人数とMoEモデルのパラメータの総数、およびこれらの専門家を組み合わせる方法の数にかかっていると考えました。
このインサイトに基づいて、Arcticは128人のきめ細かいエキスパートに480Bのパラメータを分散するよう設計されており、トップ2ゲーティングを使用して17Bのアクティブパラメータを選択します。一方、最近のMoEモデルは、表2に示すように、専門家が大幅に少ない人数で構築されています。 直感的に、Arcticは多数の合計パラメータと多数のエキスパートを活用してトップティアインテリジェンスのモデルキャパシティを拡大しつつ、多数のエキスパートの中から厳選して凝縮された適切な数のアクティブパラメータをエンゲージし、リソース効率の高いトレーニングと推論を行います。

2)アーキテクチャとシステムの共同設計:非常に強力なAIトレーニングハードウェアであっても、エキスパート間ですべてのやり取りに高いオーバーヘッドが生じるため、大勢のエキスパートによるMoEアーキテクチャのトレーニングは非常に非効率的です。しかし、通信を計算と重ねることができれば、このオーバーヘッドを隠すことができます。
2つ目のインサイトは、高密度トランスフォーマーとArcticアーキテクチャ内の残留MoEコンポーネント(図2)を組み合わせることで、通信オーバーヘッドの大部分を隠して、トレーニングシステムが通信コンピュテーションの重複によって優れたトレーニング効率を達成できることです。
3)エンタープライズ重視データカリキュラム:コード生成やSQLなどのエンタープライズメトリクスに秀でている場合、一般的なメトリクスのトレーニングモデルとは大きく異なるデータカリキュラムが必要となります。何百もの小規模なアブレーションで、常識的な推論などの汎用的なスキルは冒頭で学習でき、コーディング、数学、SQLなどのより複雑なメトリックは後半で効果的に学習できることがわかりました。人は、シンプルなものから難しいものまで、能力を身につけていく人間の生活や教育にたとえることができます。そのため、Arcticは、最初のフェーズ(1Tトークン)は汎用スキルに、後半のフェーズ(1.5Tおよび1Tトークン)はエンタープライズに焦点を当てたスキルに焦点を当てた、それぞれ異なるデータ構成の3つのステージのカリキュラムでトレーニングしました。動的カリキュラムの概要はこちらです。

推論効率
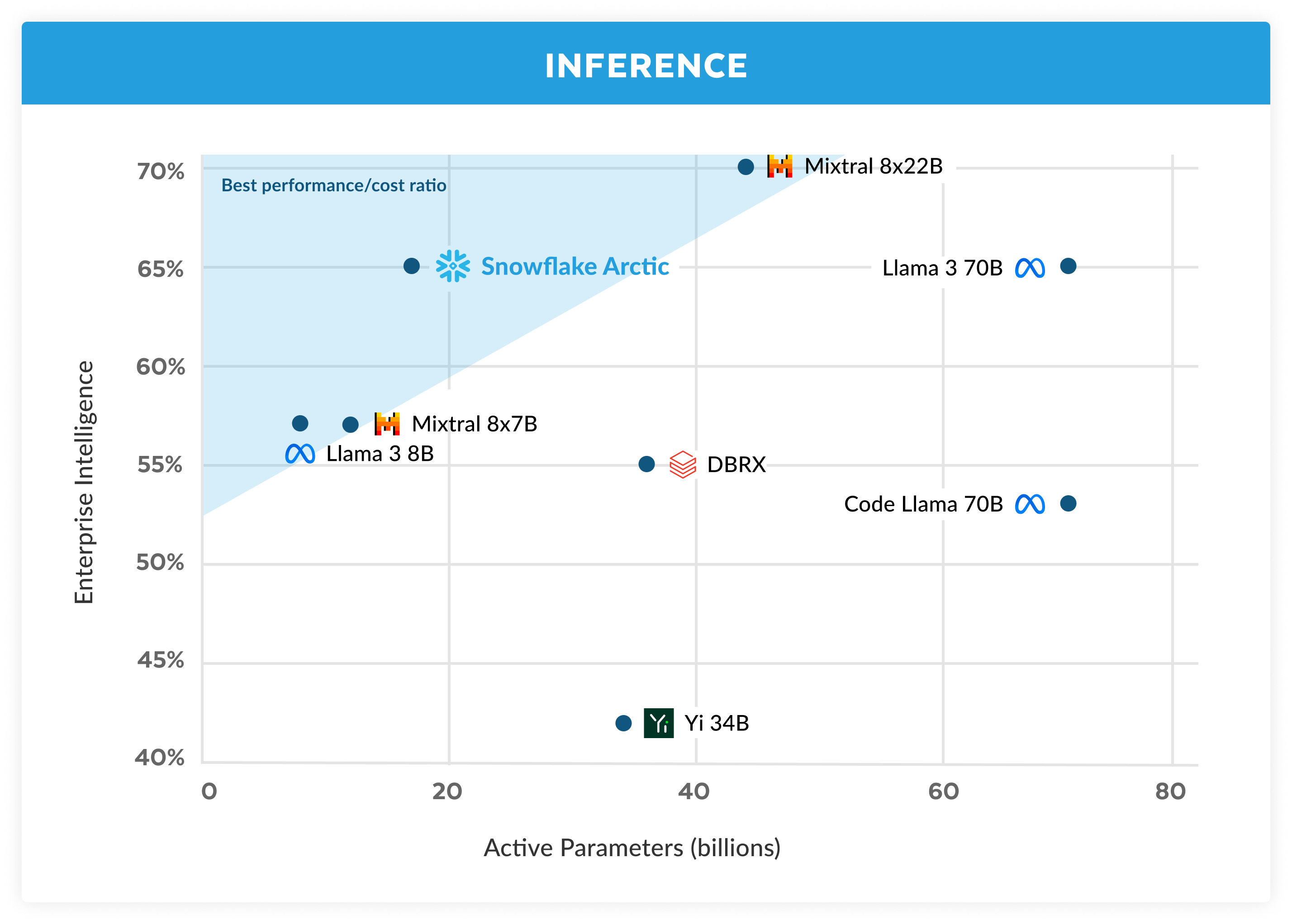
トレーニング効率は、Arcticの効率的なインテリジェンスの一面にすぎません。低コストでモデルを実際に展開できるようにするには、推論効率も同様に重要です。Arcticは、他のオープンソースの自己回帰MoEモデルよりも多くのエキスパートと合計パラメータを使用し、MoEモデルの規模を飛躍的に拡大しました。そのため、Arcticで推論を効率的に実行するには、いくつかのシステムインサイトとイノベーションが必要です。
a) バッチサイズが1などの小さなサイズのインタラクティブな推論では、メモリ帯域幅が制限されているアクティブなパラメータをすべて読み取るのにかかる時間によってMoEモデルの推論レイテンシがボトルネックになります。このバッチサイズでは、Arctic(アクティブパラメータ17B)のメモリリードはCode-Llama 70Bの最大4倍、Mixtral 8x22B(アクティブパラメータ44B)の最大2.5倍になり、推論性能が高速化します。
私たちはNVIDIAと協力し、NVIDIA TensorRT-LLMおよびvLLMチームと協力して、インタラクティブな推論のためのArcticの暫定実装を提供しました。FP8量子化では、単一のGPUノード内にArcticを収めることができます。完全に最適化されたわけではありませんが、バッチサイズが1のArcticのスループットは70トークン/秒を超えており、効果的なインタラクティブなサービスを提供できます。
b) フォワードパスごとに数千のトークンが発生するなど、バッチサイズが大幅に増加すると、Arcticはメモリ帯域幅バインドからコンピュートバインドに切り替え、トークンごとのアクティブパラメータによって推論がボトルネックになります。この時点で、Arcticのコンピューティング能力はCodeLlama 70BやLlama 3 70Bの4分の1です。
Arcticの少数のアクティブパラメータ(図3参照)に対応するコンピュートバウンド推論と高い相対スループットを実現するには、大きなバッチサイズが必要です。これを実現するには、大量のバッチサイズに対応できる十分なKVキャッシュメモリと、モデルの約5,000億のパラメータを保存できる十分なメモリが必要です。難しいのは、FP8の重み付け、スプリットヒューズと連続バッチ、ノード内のテンソル並列化、ノード間のパイプライン並列化などのシステム最適化の組み合わせを使用した2ノード推論です。
私たちはNVIDIAと密接に協力し、TensorRT-LLMを利用した NVIDIA NIMマイクロサービスの推論を最適化しました。並行して、私たちはvLLMコミュニティと協力しており、社内開発チームも今後数週間で、エンタープライズユースケース向けにArcticを効率的に推論できるようにしていきます。
真にオープン
Arcticは、Snowflakeの多様なチームの経験と、コミュニティから得られた大きなインサイトと教訓を基に構築されています。オープンなコラボレーションはイノベーションの鍵であり、アークティックはオープンソースとコミュニティからのオープンな研究インサイトなしには成し遂げられなかったでしょう。私たちはコミュニティに感謝し、集合知を豊かにし、他の人たちを成功に導くために、自分たちの学びを還元したいと考えています。
真にオープンなエコシステムに対するSnowflakeのコミットメントは、オープンウェイトやコードにとどまらず、オープンリサーチのインサイトやオープンソースレシピも提供します。
オープンリサーチのインサイト
Arcticの構築は、コミュニティの豊富なインサイトのおかげで迅速に進められたオープンパスと、コミュニティの事前のインサイトが不足している調査セグメントが特徴のハードパスという、2つの異なる軌道で進められました。
今回のリリースでは、単にモデルを発表するだけでなく、これまでのハードパスから得られた知見を公開する包括的な「クックブック」を通じてリサーチインサイトを共有します。本書は、ワールドクラスのMoEモデルの構築を目指すすべての人の学習プロセスを促進するよう設計されています。Snowflakeは、Arcticに似たLLMを構築する際に、高度なインサイトときめ細かい技術詳細を融合させることで、難しいアプローチではなくオープンなアプローチで、効率的かつ経済的に望ましいインテリジェンスを構築できます。
本書は、事前トレーニング、微調整、推論、評価など幅広いトピックをカバーしており、モデリング、データ、システム、インフラストラクチャーについても掘り下げています。20以上のトピックを概説した目次をプレビューできます。対応するMedium.comのブログ記事は 来月中に毎日公開予定ですたとえば、ウェブデータの調達と改良に関する当社の戦略は、「どのようなデータを使用するか」で開示します。 データ構成とカリキュラムについては、「データの構成方法」で説明します。 「高度なMoEアーキテクチャ」では、モデルアーキテクチャとシステム性能の共同設計について説明します。LLM評価に興味がある方のために、私たちの「モデル品質の評価と比較方法 - 皆さんが思っているより簡単」は、私たちが直面した予想外の複雑さを明らかにするでしょう。
この取り組みを通じて、この分野の限界を押し広げるために集団で学び、前進することが当たり前のオープンなコミュニティに貢献したいと思っています。
オープンソースのサービスコード
- ベースバージョンとインストラクションチューニングバージョンの両方のモデルチェックポイントをApache 2.0ライセンスでリリースします。つまり、自分の研究、プロトタイプ、製品で自由に使用できます。
- レシピを完備したLoRAベースのファインチューニングパイプラインにより、単一のノードで効率的にモデルをチューニングできます。
- NVIDIA TensorRT-LLMおよびvLLMと共同で、バッチサイズが1のインタラクティブな使用に最適化されたArcticの初期推論実装を開発しています。コミュニティと協力し、非常に大規模なMoEモデルの高バッチサイズ推論の複雑さに対処できることを楽しみにしています。
- Arcticは、4Kアテンションコンテキストウィンドウを使用してトレーニングされます。今後数週間で、無制限のシーケンス生成機能をサポートするために、アテンションシンクベースのスライドウィンドウ実装を開発中です。近い将来、コミュニティと協力して32Kのアテンションウィンドウに拡大できることを楽しみにしています。
メトリクス
メトリクスの観点から、私たちは主に、いわゆるエンタープライズインテリジェンスメトリクスに焦点を当てています。これは、コーディング(HumanEval+およびMBPP+)、SQL生成(Spider)、命令フォロー(IFEval)など、企業のお客様にとって重要なスキルの集まりです。
同時に、研究者コミュニティが評価するメトリクスに基づいてLLMを評価することも重要です。これには、世界の知識、常識的な推論、数学の機能が含まれます。私たちはこれらの指標を学術ベンチマークと呼んでいます。
以下は、企業メトリクスと学術メトリクスにまたがる複数のオープンソースモデルによるArcticの比較です。
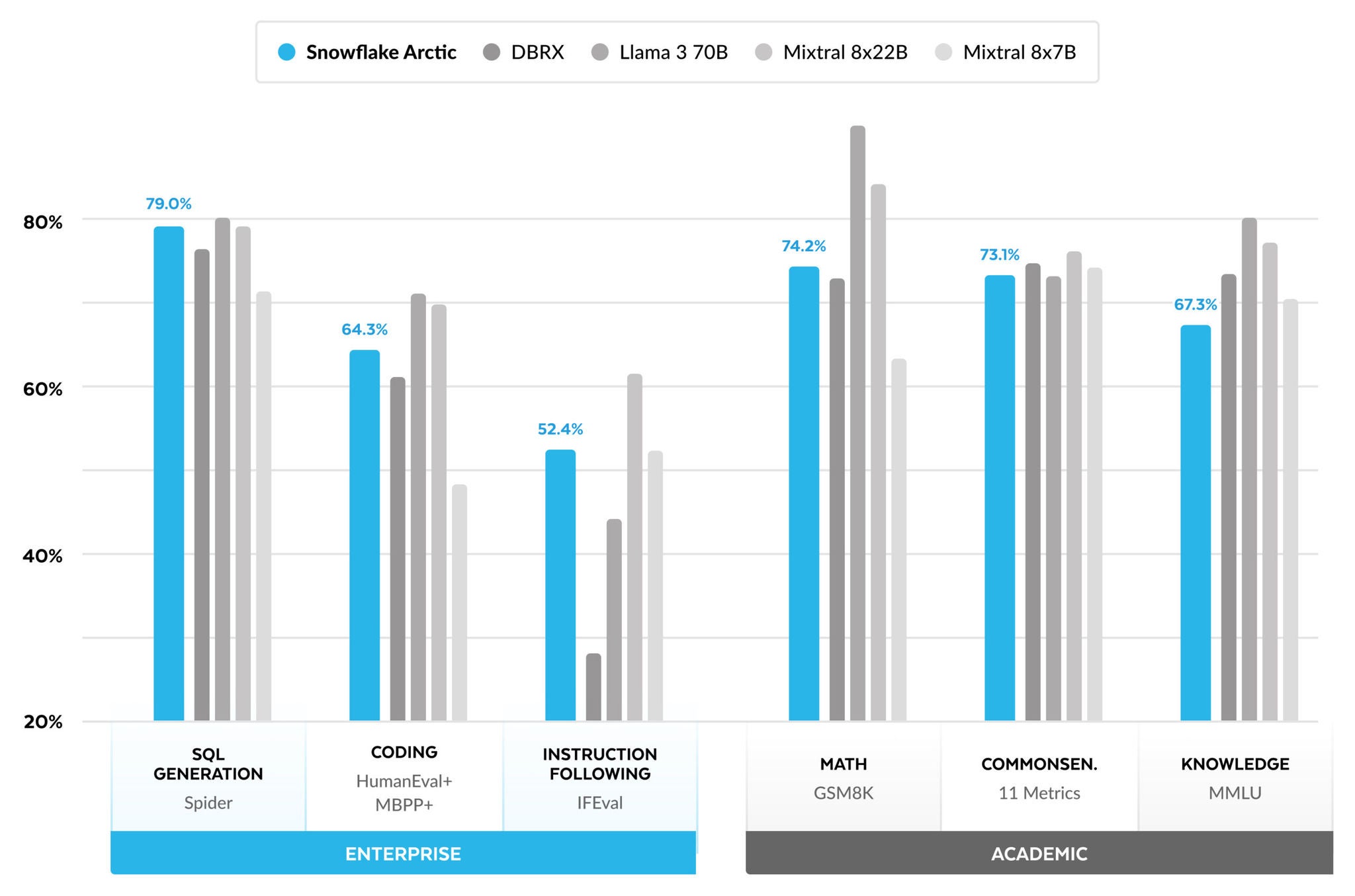
エンタープライズメトリクスについては、コンピュートクラスに関係なく、他のすべてのオープンソースモデルと比較してトップクラスのパフォーマンスを示します。その他の指標では、コンピュートクラスでトップクラスのパフォーマンスを達成し、より高いコンピュート予算でトレーニングされたモデルとの競争力も維持しています。Snowflake Arcticは、市販のエンタープライズユースケースに最適なオープンソースモデルです。また、最小の総保有コスト(TCO)で独自のモデルを一からトレーニングしたい場合は、クックブックのトレーニングインフラストラクチャーとシステム最適化の説明が非常に興味深いです。
学術的ベンチマークでは、モデル性能を表すためにMMLUなどの世界の知識指標が重視されてきました。高品質のウェブデータとSTEMデータにより、MMLUはFLOPSのトレーニングの関数として単調に上昇します。Arcticは、トレーニング予算を小さく抑えながらトレーニング効率を最適化することを1つの目的としていたため、結果として、最近のトップティアモデルと比較してMMLUのパフォーマンスが低下しました。このインサイトに基づき、現在進行中のトレーニングは、Arcticよりも高いトレーニングコンピュート予算で実行され、ArcticのMMLUパフォーマンスを超えると予想されます。MMLUワールドナレッジの実績は、私たちがエンタープライズインテリジェンスに注力していることとは必ずしも相関しないことに注意してください。
Arcticの利用を始めるにあたり
Snowflake AI Researchは最近、MTEB検索でSoTAを実現するモデルのArctic Embedファミリーを発表、オープンソース化しました。Snowflakeは、Arcticのモデルファミリーの次世代を育てるために、コミュニティと協力したいと考えています。6月3日~6日に開催されるData Cloud Summitにご参加ください。
今日からArcticでコラボレーションする方法をご紹介します。
- Hugging Faceで直接Arcticをダウンロードし、Githubレポジトリを使用して推論とレシピの微調整を行います。
- Snowflake Cortexでサーバーレス体験を提供するため、Snowflakeのお客様は6月3日までSnowflake Arcticに無料でアクセスできます。1日制限
- 今後数日かけて、Amazon Web Services(AWS)、Lamini、Microsoft Azure、NVIDIA APIカタログ、Perplexity、Replicate、Together AIなどのお好きなモデルガーデンまたはカタログでArcticにアクセスしましょう。
- ArcticとチャットStreamlit Community CloudまたはHugging Face Streamlit Spacesで、Replicateの仲間のAPIを利用してライブデモを今すぐお試しください。
- Arcticをテーマとしたコミュニティハッカソンで、Arcticを活用した独自のアプリケーションの構築に役立つメンターシップとクレジットを獲得しましょう。
最後に、料理本のレシピ第1版をお忘れなく。最もコスト効率の良い方法で独自のカスタムMoEモデルを構築する方法について学びましょう。
確認応答
Snowflakeのトレーニングクラスターとインフラストラクチャーの構築におけるAWSとNVIDIAのコラボレーションとパートナーシップと、NVIDIA NIMとTensorRT-LLMによるSnowflakeサポートの実現におけるNVIDIAのコラボレーションに感謝します。 また、このリリースを実現するために構築できるモデル、データセット、データセットレシピインサイトを生み出してくれたオープンソースコミュニティに感謝します。また、AWS、Microsoft Azure、NVIDIA APIカタログ、Lamini、Perplexity、Replicate、Together AIのパートナーの皆様には、Arcticを利用できるようにするためのコラボレーションに感謝申し上げます。
1.言語理解と推論の11個の指標には、ARC-Easy、ARC-Challenge、BoolQ、CommonsenseQA、COPA、HellaSwag、LAMBADA、OpenBookQA、PIQA、RACE、WinoGrandeが含まれます。
2.HumanEval+/MBPP+ v0.1.0の評価スコアは 、 ( 1)モデル固有のチャットテンプレートと整合後処理を使用したビッグコード評価ハーネス 、 ( 2)貪欲なデコードを仮定して得られた。一貫性を確保するために、すべてのモデルをパイプラインで評価しました。評価結果がEvalPlusリーダーボードと一致していることを検証しました。実際、私たちのパイプラインでは、すべてのモデルのEvalPlusの数値を数ポイント上回る数値が得られ、各モデルを最良の方法で評価しているという自信があります。
3. IFEval スコアはscores reported are the average of prompt_level_strict_acc と inst_level_strict_accの平均と報告されています。
著者
