Snowflake Arctic: Das beste LLM für Unternehmens-KI – mit effizienter Intelligenz und echter Offenheit

Der Aufbau erstklassiger, unternehmensfähiger Intelligenz durch den Einsatz von LLMs ist in der Regel unheimlich teuer und ressourcenintensiv. Oft kostet das Ganze bis zu hunderte Millionen Euro. Als Forschende befassen wir uns schon seit Jahren mit den Herausforderungen rund um effiziente Inferenz und effizientes Training von LLMs. Mitglieder des Teams für Snowflake AI Research haben Systeme wie ZeRO und DeepSpeed, PagedAttention/vLLM und LLM360 herausgebracht, die die Kosten für LLM-Training und -Inferenz erheblich verringert haben. Und sie haben sie auf Open Source umgestellt, um der Community besseren und kostengünstigeren Zugang zu LLMs zu bieten.
Das Snowflake AI Research Team freut sich, Ihnen Snowflake Arctic vorstellen zu dürfen, ein erstklassiges LLM speziell für Unternehmen, das in Sachen kosteneffizientes Training und Offenheit völlig neue Maßstäbe setzt. Arctic bietet effiziente Intelligenz und echte Offenheit.
- Effiziente Intelligenz: Arctic glänzt bei Unternehmensaufgaben wie SQL-Erstellung, Coding und Anweisungsbefolgung und kann selbst mit Open-Source-Modellen mithalten, die mit deutlich mehr Rechenressourcen trainiert wurden. Tatsächlich setzt die Lösung neue Maßstäbe in Sachen kosteneffizientes Training, sodass Snowflake-Kunden zu geringen Kosten hochwertige Modelle für ihre Unternehmensanforderungen erstellen können.
- Echte Offenheit: Die Apache-2.0-Lizenz bietet ungehinderten Zugang zu Gewichtungen und Code. Darüber hinaus bieten wir Open-Source-Zugang zu all unseren Datenrezepten und Forschungserkenntnissen.
Sie können Snowflake Arctic schon heute über Hugging Face, den NVIDIA API-Katalog und Replicate abrufen. Demnächst wird die Lösung dann auch über den Model Garden oder Modellkatalog Ihrer Wahl verfügbar sein, darunter Snowflake Cortex, Amazon Web Services (AWS), Microsoft Azure, Lamini, Perplexity und Together.
Erstklassige Enterprise Intelligence zu unglaublich geringen Trainingskosten
Bei Snowflake erleben wir einen beständigen Trend, was die KI-Anforderungen und -Anwendungsfälle unserer Unternehmenskunden angeht: Unternehmen wollen LLMs einsetzen, um dialogorientierte Assistenten für SQL-Daten und Code oder RAG-Chatbots (Retrieval Augmented Generation) zu entwickeln. So entstehen LLMs, die nicht nur ausgezeichnete Performance bei SQL, Coding und der Befolgung komplexer Anweisungen erreichen, sondern auch hervorragend in der Lage sind, fundierte Antworten zu geben. Wir haben all diese Fähigkeiten in einer einzigen Metrik zusammengefasst, die wir als Enterprise Intelligence bezeichnen. Sie entspricht dem Durchschnitt aus Coding (HumanEval+ und MBPP+), SQL-Erstellung (Spider) und Anweisungsbefolgung (IFEval).
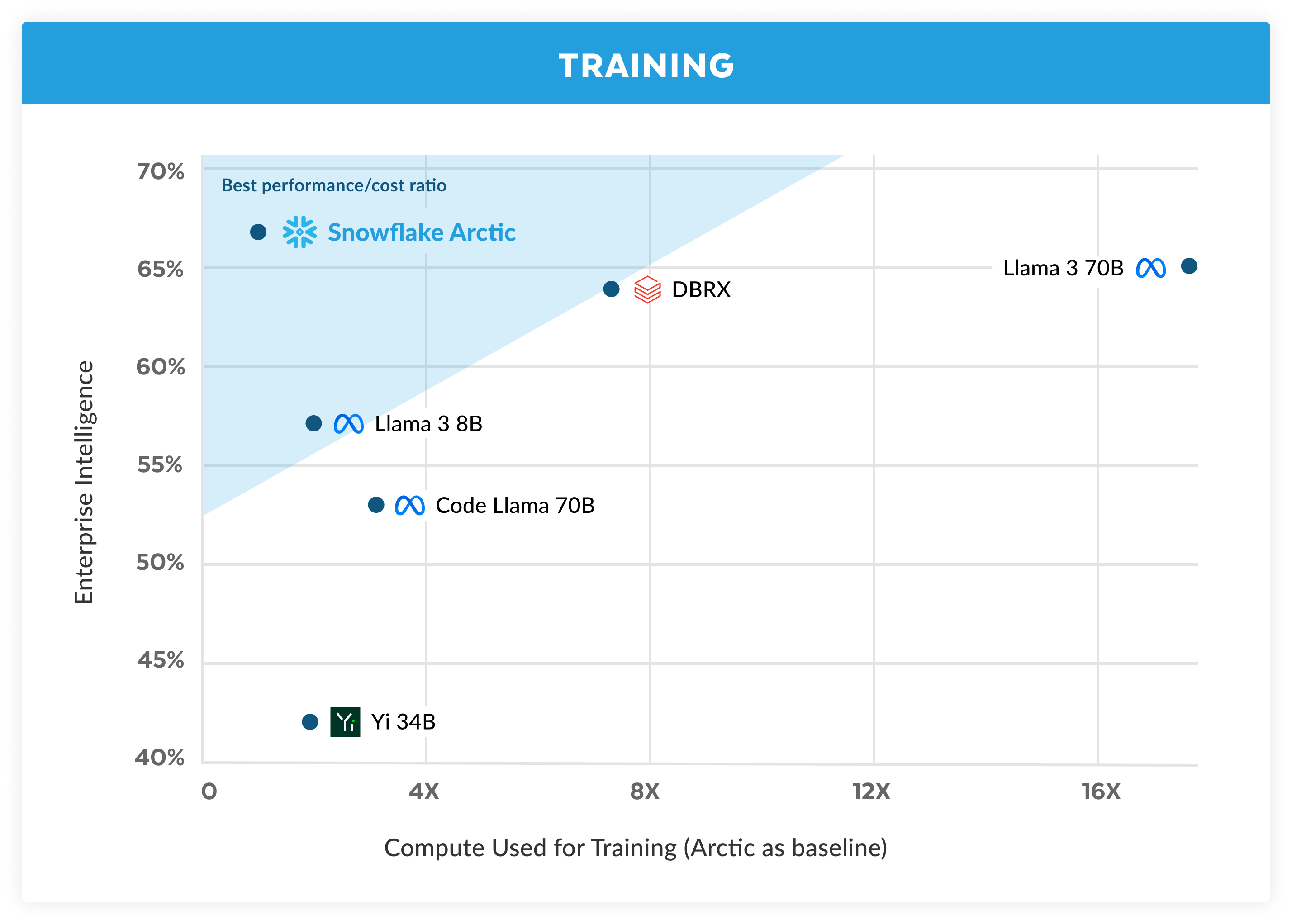
Arctic bietet erstklassige Enterprise Intelligence unter Open-Source-LLMs – und das mit einem Rechenressourcen-Budget von weniger als zwei Millionen US-Dollar (weniger als 3.000 GPU-Wochen). Das heißt, dass Arctic fähiger ist als andere Open-Source-Modelle, die mit ähnlichen Rechenressourcen-Budgets trainiert wurden. Und noch wichtiger: Die Lösung kann hinsichtlich Enterprise Intelligence selbst mit Modellen mithalten, die mit deutlich höheren Budgets trainiert wurden. Dank der hohen Trainingseffizienz von Arctic können Snowflake-Kunden und die KI-Community individuelle Modelle zu deutlich geringeren Kosten trainieren.
Wie Sie in Abbildung 1 sehen, erreicht oder übertrifft Arctic die Metriken im Enterprise-Bereich von Llama-3 8B und Llama-2 70B, obwohl unser Modell nur ein halb so großes Trainingsbudget braucht. Selbst mit Llama-3 70B, das ein 17 Mal größeres Budget für Rechenressourcen benötigt, liegt Arctic noch gleichauf, wenn es um Enterprise-Metriken wie Coding (HumanEval+ und MBPP+), SQL (Spider) und Anweisungsbefolgung (IFEval) geht. Und auch bei der allgemeinen Performance kann sich die Lösung mit der Konkurrenz messen: So kann Arctic beispielsweise trotz einem Siebtel der Rechenressourcen mit DBRX mithalten, wenn es um Sprachverständnis und logisches Denken geht (eine Sammlung von elf Metriken) – und in Mathematik (GSM8K) schneidet es sogar besser ab. Eine detaillierte Aufschlüsselung der Ergebnisse für die individuellen Benchmarks finden Sie im Abschnitt „Metriken“.
Trainingseffizienz
Um dieses Maß an Trainingseffizienz zu erreichen, nutzt Arctic eine einzigartige Dense-MoE-Transformer-Hybridarchitektur (MoE, Mixture of Experts). Sie kombiniert ein dichtes Transformer-Modell, das zehn Milliarden Parameter umfasst, mit einem Residual-MoE-MLP von 128 x 3,66 Milliarden Parametern. Das sind insgesamt 480 Milliarden Parameter (17 Milliarden davon aktiv), die mittels Top-2-Gating ausgewählt werden. Das Modell wurde auf Basis der drei folgenden wichtigen Erkenntnisse und Innovationen entwickelt und trainiert:
1) Viele, aber komprimierte Experten mit mehr Expertenoptionen: Ende 2021 demonstrierte das Team von DeepSpeed, dass MoE auf auto-regressive LLMs angewendet werden kann, um die Modellqualität deutlich zu steigern, ohne hierfür mehr Rechenressourcen zu benötigen.
Bei der Entwicklung von Arctic haben wir festgestellt, dass die Verbesserung der Modellqualität in erster Linie von der Anzahl der Experten und der Gesamtzahl der Parameter im MoE-Modell abhängig war – und von den verschiedenen Arten, wie sich diese Experten kombinieren ließen.
Basierend auf dieser Erkenntnis wurde Arctic mit 480 Milliarden Parametern entwickelt, die sich über 128 fein abgestufte Experten erstrecken. Hierbei nutzt die Lösung Top-2-Gating, um 17 Milliarden aktive Parameter auszuwählen. Im Gegensatz dazu werden MoE-Modelle mit deutlich weniger Experten entwickelt, wie Sie in Tabelle 2 sehen. Dementsprechend nutzt Arctic eine große Anzahl von Parametern sowie viele Experten, um die Modellkapazität zu erweitern und so erstklassige Intelligenz zu unterstützen. Hierbei wählt die Lösung mit Bedacht aus vielen, aber komprimierten Experten und legt eine moderate Anzahl aktiver Parameter fest, um Training und Inferenz ressourceneffizient zu gestalten.
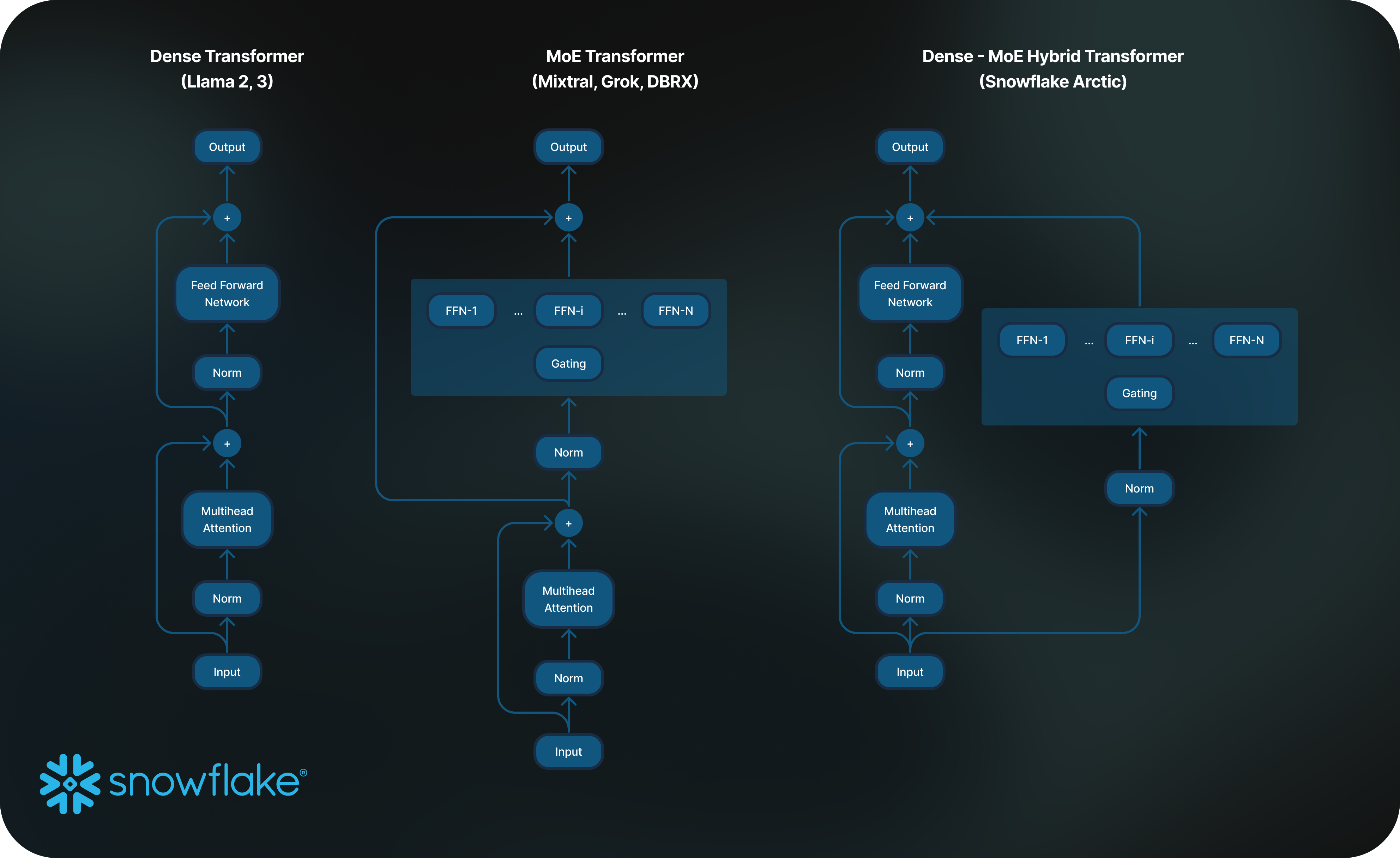
2) Architektur- und System-Co-Design: Die standardmäßige MoE-Architektur mit einer großen Anzahl von Experten zu trainieren, ist alles andere als effizient – selbst mit der leistungsstärksten KI-Trainingshardware. Grund hierfür ist die aufwendige Kommunikation zwischen den Experten. Doch dieser Aufwand spielt keine Rolle, wenn sich die Kommunikation mit der Berechnung überlappt.
Unsere zweite Erkenntnis ist also: Indem wir einen dichten Transformer mit einer zusätzlichen MoE-Komponente (Abbildung 2) in der Arctic-Architektur kombinieren, erreicht unser Trainingssystem eine gute Trainingseffizienz – dank der Überlappung von Kommunikation und Berechnung, wodurch ein großer Teil des Kommunikationsaufwands nichtig wird.
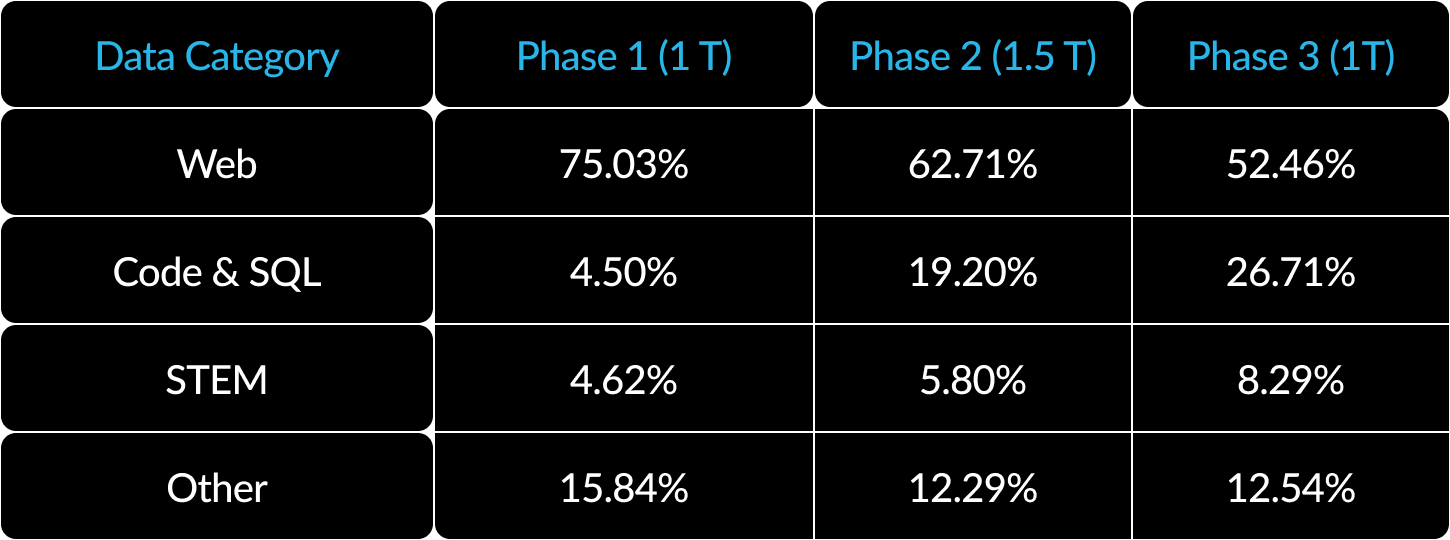
3) Auf Unternehmen ausgerichteter Trainingsplan: Um in Enterprise-Metriken wie Codegenerierung und SQL zu glänzen, braucht es gänzlich andere Trainingspläne, als wenn Sie Modelle für allgemeine Metriken trainieren. In Hunderten kleiner „Ablations“ – in denen Komponenten entfernt werden, um herauszufinden, wie wichtig sie waren – haben wir gelernt, dass allgemeine Fähigkeiten wie logisches Denken am Anfang erlernt werden können, während sich komplexere Metriken wie Coding, Mathematik und SQL effektiv gegen Ende des Trainings vermitteln lassen. Es ist im Grunde wie bei unserer eigenen Bildung: Wir fangen mit einfachen Fähigkeiten an und steigern uns dann. Deshalb wurde Arctic mit einem 3-Phasen-Trainingsplan entwickelt – jeweils mit einer anderen Datenzusammenstellung, die sich in der ersten Phase (1.000 Token) auf allgemeine Kompetenzen konzentrierte und in den zweiten beiden Phasen (1.500 bzw. 1.000 Token) auf Enterprise-Fähigkeiten. Eine Zusammenfassung unseres dynamischen Trainingsplans sehen Sie hier.
Inferenzeffizienz
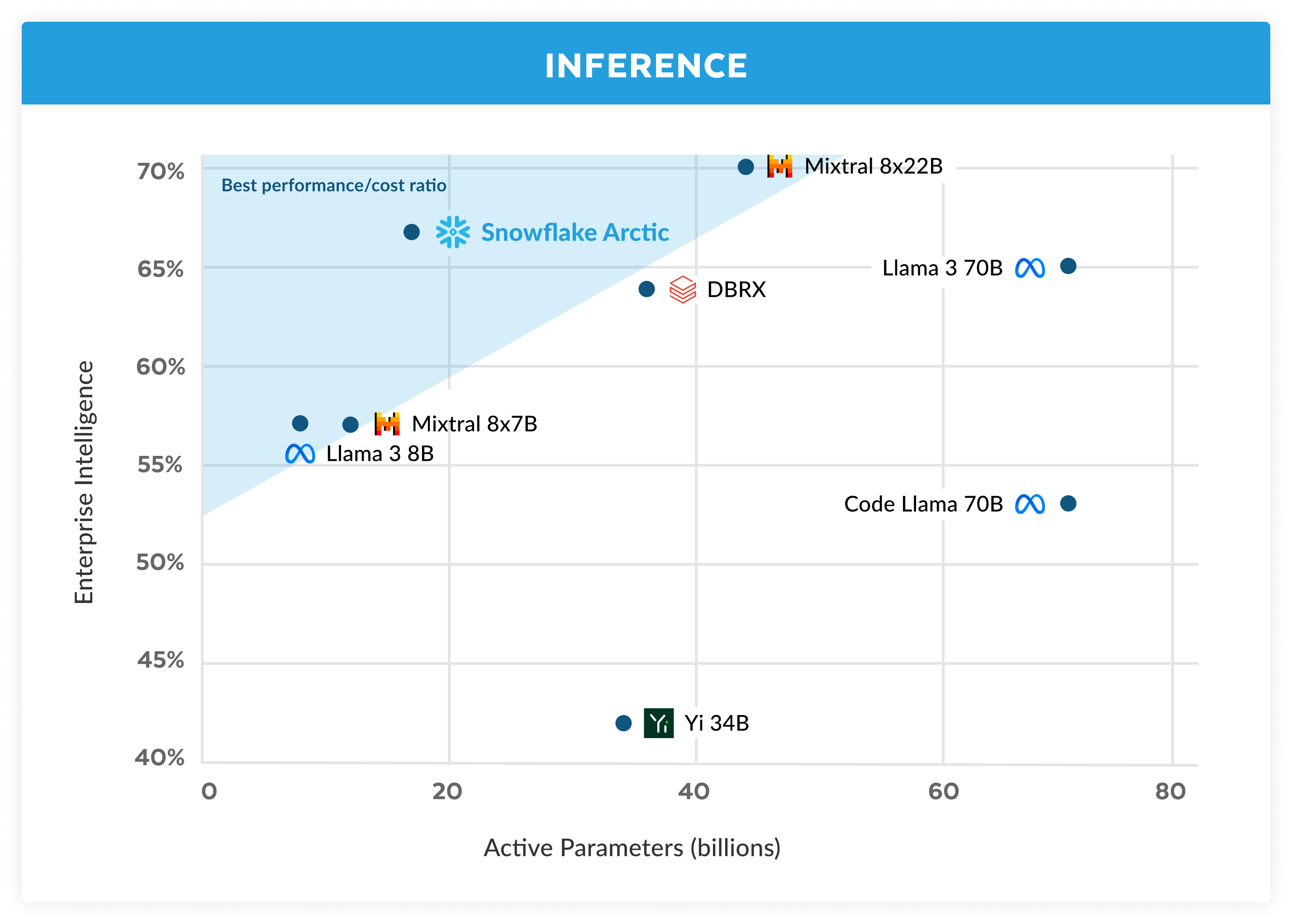
Die Trainingseffizienz ist nur eine Seite der effizienten Intelligenz von Arctic. Auch effiziente Inferenz ist entscheidend für die praktische und kostengünstige Bereitstellung des Modells. Arctic setzt neue Maßstäbe, was die Skalierung von MoE-Modellen angeht – mit mehr Experten und Gesamtparametern als jedes andere auto-regressive Open-Source-MoE-Modell. Deshalb sind zahlreiche Systemeinblicke und -innovationen erforderlich, um in Arctic eine effiziente Inferenz zu erreichen:
a) Bei der interaktiven Inferenz kleiner Batch-Größen (beispielsweise bei einer Größe von 1) wird die Inferenzlatenz des MoE-Modells durch die Zeit bestimmt, die es dauert, bis alle aktiven Parameter gelesen wurden. Die Inferenz ist hierbei an die Bandbreite des Arbeitsspeichers gebunden. Bei dieser Batch-Größe erfordert Arctic (mit 17 Milliarden aktiven Parametern) bis zu vier Mal weniger Arbeitsspeicher-Lesevorgänge als Code-Llama 70B und bis zu 2,5 Mal weniger als Mixtral 8x22B (mit 44 Milliarden aktiven Parametern). Und das verbessert natürlich die Performance der Modellinferenz.
Wir haben mit NVIDIA zusammengearbeitet, insbesondere mit den Teams von NVIDIA TensorRT-LLM und vLLM, um eine vorläufige Arctic-Implementierung für interaktive Inferenz bereitzustellen. Mit FP8-Quantisierung können wir Arctic mit einem einzigen GPU-Knoten ausstatten. Und auch wenn wir weit von einer vollständigen Optimierung entfernt sind, erreicht Arctic bei einer Batch-Größe von 1 einen Durchsatz von über 70 Token pro Sekunde und ermöglicht damit eine effektive interaktive Datenbereitstellung.
b) Bei deutlich größeren Batches, beispielsweise mit Tausenden von Token pro erfolgreichem Forward-Pass, verlässt sich Arctic nicht mehr auf die Bandbreite des Arbeitsspeichers, sondern auf die der Rechenressourcen. Hier wird die Inferenz nur durch die aktiven Parameter pro Token begrenzt. Hierdurch braucht Arctic vier Mal weniger Rechenressourcen als Code-Llama 70B and Llama-3 70B.
Damit die Inferenz auf Rechenressourcen basiert und der hohe relative Durchsatz erreicht wird, der die kleinere Anzahl aktiver Parameter in Arctic unterstützt (siehe Abbildung 3), benötigen wir große Batches. Doch hierfür braucht es ausreichend KV-Cache-Speicher, um die großen Batches zu unterstützen. Und gleichzeitig muss genug Arbeitsspeicher zur Verfügung stehen, damit die fast 500 Milliarden Parameter für das Modell gespeichert werden können. Das ist zwar herausfordernd, lässt sich aber mit 2-Knoten-Inferenz und einer Kombination verschiedener Systemoptimierungen erreichen, darunter FP8-Gewichtungen, Split-Fuse und kontinuierliches Batching, Tensor-Parallelität innerhalb eines Knotens sowie Pipeline-Parallelität über Knoten hinweg.
Wir haben eng mit NVIDIA zusammengearbeitet, um die Inferenz für TensorRT-LLM-basierte NVIDIA-NIM-Microservices zu verbessern. Gleichzeitig arbeiten wir mit der vLLM-Community und unserem internen Entwicklungsteam zusammen, um in den nächsten Wochen eine effiziente Arctic-Inferenz für Enterprise-Anwendungsfälle zu ermöglichen.
Echte Offenheit
Arctic wurde nicht nur auf Basis der kollektiven Erfahrung unseres vielfältigen Teams, sondern auch mithilfe wichtiger Einblicke und Erkenntnisse aus der Community entwickelt. Offene Zusammenarbeit ist entscheidend für Innovation, und Arctic wäre ohne den Open-Source-Code und die offene Forschung der Community nicht möglich gewesen. Wir sind der Community sehr dankbar und freuen uns, mit unseren Erkenntnissen etwas zurückzugeben, um das kollektive Wissen zu erweitern und andere bei ihrem Erfolg zu unterstützen.
Unser Engagement für ein wahrhaft offenes Ökosystem geht weit über Gewichtungen und Code hinaus und umfasst auch offene Forschungseinblicke und Open-Source-Rezepte.
Offene Forschungseinblicke
Die Entwicklung von Arctic verlief auf zwei unterschiedlichen Pfaden: dem offenen Pfad, auf dem wir dank der umfassenden Einblicke aus der Community schnell navigieren konnten, und dem schweren Pfad, der durch die Forschungssegmente geprägt ist, für die es noch keine Daten aus der Community gab, wodurch intensives Debugging und zahlreiche Ablations erforderlich waren.
Mit diesem Release enthüllen wir nicht nur unser neues Modell, sondern teilen auch unsere Forschungsergebnisse in Form unseres umfassenden Snowflake Arctic Cookbook, das unsere Erkenntnisse vom schweren Pfad enthält. Das Cookbook soll den Lernprozess für interessierte Personen beschleunigen, die erstklassige MoE-Modelle aufbauen wollen. Es bietet eine Mischung aus allgemeinen Erkenntnissen und tiefgehenden technischen Details zur Entwicklung eines Arctic-ähnlichen LLM, damit Sie auf effiziente und wirtschaftliche Weise Ihre gewünschte Enterprise Intelligence aufbauen können – und zwar auf dem offenen Pfad, nicht auf dem schweren.
Das Cookbook deckt verschiedenste Themen ab, darunter Vorabtraining, Anpassung, Inferenz und Bewertung, und behandelt außerdem Modellierung, Daten, Systeme und Infrastruktur. Sie können sich eine Vorschau des Inhaltsverzeichnisses anzeigen lassen, das über 20 Themen umfasst. Wir werden im nächsten Monat täglich zugehörige Blogbeiträge auf Medium.com veröffentlichen. Beispielsweise werden wir in „What data to use?“ unsere Strategien für die Beschaffung und Optimierung von Webdaten vorstellen. Wir werden in „How to compose data“ unsere Datenzusammenstellung und unseren Trainingsplan besprechen. In „Advanced MoE architecture“ sprechen wir darüber, wie wir verschiedene MoE-Architekturvarianten erkundet haben, und diskutieren dabei auch das gemeinsame Design aus Modellarchitektur und Systemperformance. Und falls Sie mehr über LLM-Bewertung wissen wollen, untersuchen wir in „How to evaluate and compare model quality — less straightforward than you think“ die unerwartete Komplexität, auf die wir hierbei gestoßen sind.
Mit dieser Initiative wollen wir zu einer offenen Community beitragen, wo gemeinsames Lernen und Weiterkommen an der Tagesordnung ist, um die Grenzen in diesem Bereich weiter zu verschieben.
Open-Source-Bereitstellungscode
- Wir veröffentlichen Modell-Checkpoints sowohl für die Basis- als auch für die per Anweisung angepassten Versionen von Arctic – alles im Rahmen einer Apache-2.0-Lizenz. Sie können sie also frei verwenden – in Ihrer eigenen Forschung, für Prototypen oder sogar für Produkte.
- Unsere LoRA-basierte Anpassungs-Pipeline, mitsamt Rezept, ermöglicht effiziente Modellanpassung auf einem einzigen Knoten.
- In Zusammenarbeit mit NVIDIA TensorRT-LLM und vLLM entwickeln wir derzeit erste Inferenzimplementierungen für Arctic, die für die interaktive Nutzung mit einer Batch-Größe von 1 optimiert wurden. Wir freuen uns, mit der Community zusammenzuarbeiten, um die Herausforderungen bei der Inferenz riesiger MoE-Modelle in großen Batches zu meistern.
- Arctic wurde mit einem Attention Context Window von 4.000 trainiert. Wir entwickeln derzeit eine „Sliding Attention Window“-Implementierung, die auf einem sogenannten „Attention Sink“ basiert, um in den kommenden Wochen unbegrenzte Sequenzgenerierung zu ermöglichen. Wir freuen uns, auch hier mit der Community zusammenzuarbeiten, um in naher Zukunft auf ein 32.000er Attention Window umzustellen.
Metriken
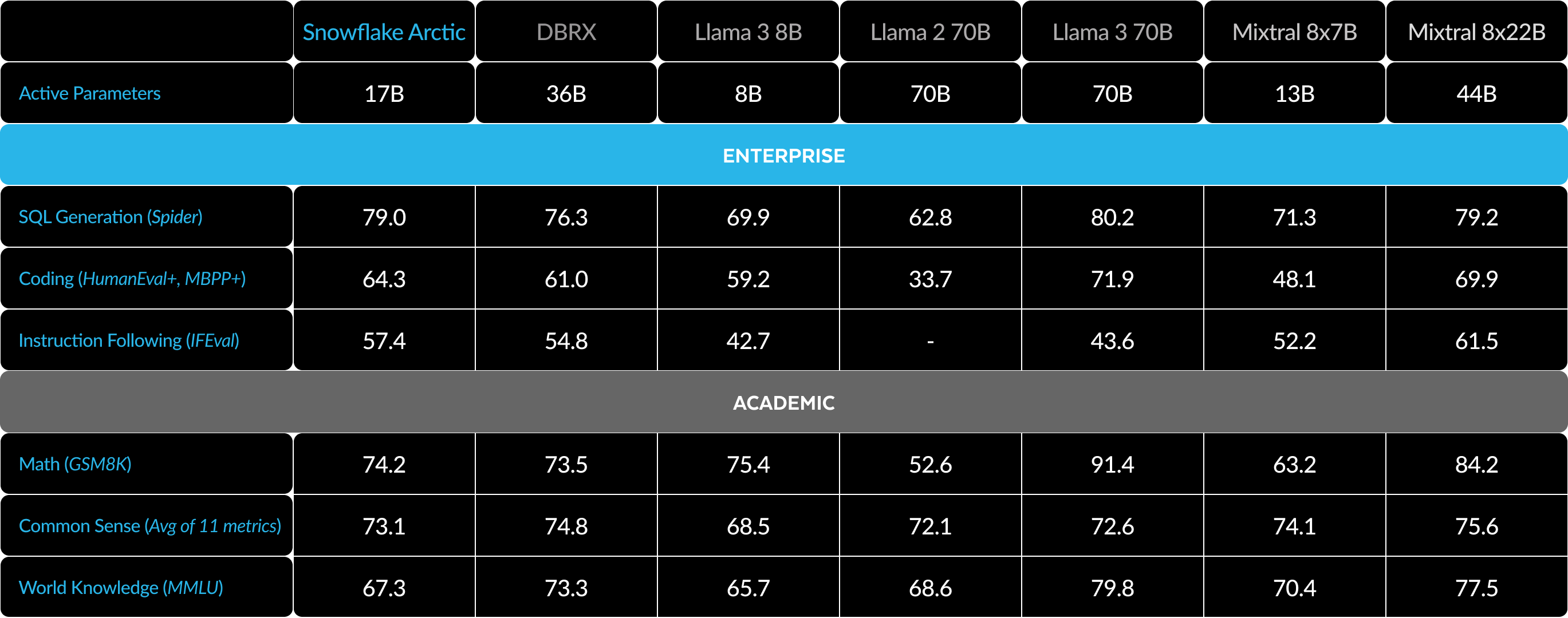
Unser Fokus in Sachen Metriken liegt primär auf Enterprise Intelligence-Metriken, einer Sammlung von Fähigkeiten, die für Unternehmenskunden entscheidend sind, darunter Coding (HumanEval+ und MBPP+), SQL-Erstellung (Spider) und Anweisungsbefolgung (IFEval).
Gleichzeitig ist es ebenso wichtig, LLMs anhand von Metriken zu bewerten, die auch die Forschungsgemeinschaft verwendet. Dazu gehören Weltwissen, logisches Denken und mathematische Fähigkeiten. Wir bezeichnen diese Metriken als akademische Benchmarks.
Hier ein Vergleich zwischen Arctic und mehreren anderen Open-Source-Modellen anhand verschiedener Enterprise- und akademischer Metriken:
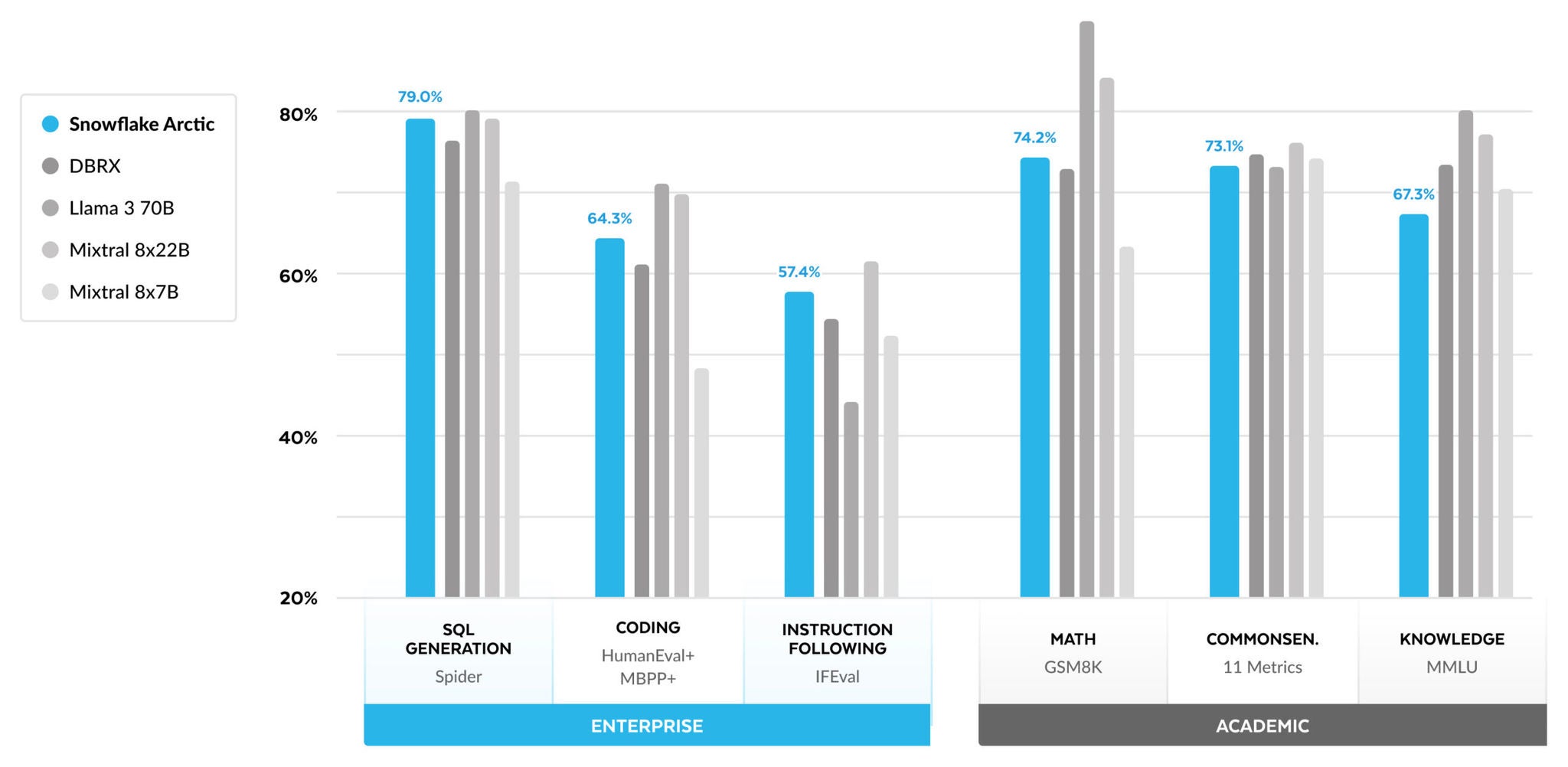
Bei den Enterprise-Metriken erreicht Arctic eine Top-Performance im Vergleich zu allen anderen Open-Source-Modellen – und zwar unabhängig von den eingesetzten Rechenressourcen. Bei den anderen Metriken erreicht die Lösung in ihrer Rechenressourcen-Klasse beste Leistungen und kann sogar mit Modellen mithalten, die mit deutlich größeren Budgets trainiert wurden. Snowflake Arctic ist das beste Open-Source-Modell für standardmäßige Anwendungsfälle in Unternehmen. Und wenn Sie von Grund auf Ihr eigenes Modell trainieren wollen – und zwar zu den niedrigsten Gesamtbetriebskosten (Total Cost of Ownership, TCO) –, dann könnte Sie die Beschreibung der Trainingsinfrastruktur und der Systemoptimierungen in unserem Snowflaker Arctic Cookbook interessieren.
Bei akademischen Benchmarks liegt der Fokus auf Metriken im Bereich Weltwissen, darunter auch MMLU, um die Modellperformance widerzuspiegeln. Mit hochwertigen Web- und MINT-Daten steigt MMLU monoton als Funktion von Trainings-FLOPS. Ein Ziel für Arctic bestand darin, die Trainingseffizienz zu optimieren, aber gleichzeitig das Trainingsbudget klein zu halten. Und das führte unausweichlich zu einer niedrigeren MMLU-Performance im Vergleich zu aktuellen Top-Modellen. Anhand dieser Erkenntnis erwarten wir, dass unser aktueller Trainingslauf mehr Rechenressourcen erfordern wird als Arctic, um dessen MMLU-Performance zu übertreffen. Wir weisen darauf hin, dass gute Performance im MMLU-Weltwissen nicht unbedingt unserem Fokus auf Enterprise Intelligence entspricht.
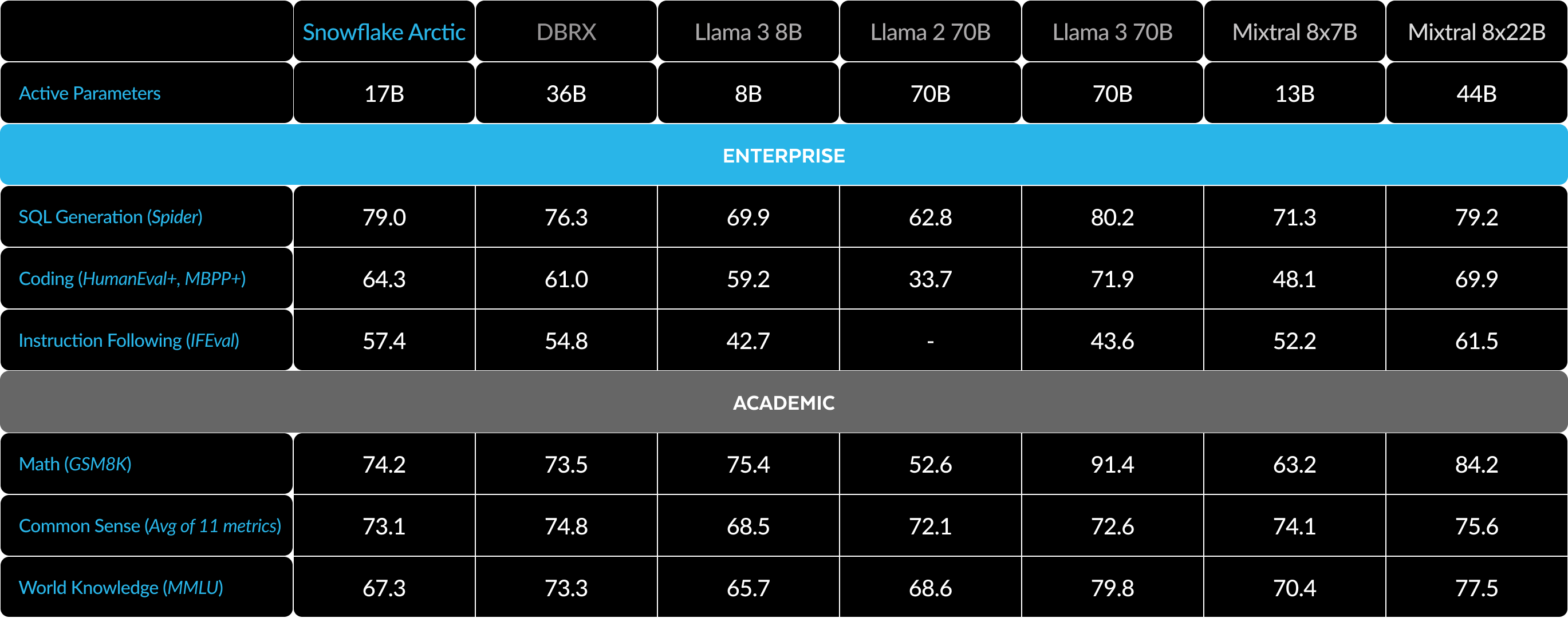
Tabelle 3: Übersicht aller Metriken, Vergleich zwischen Snowflake Arctic und DBRX, Llama-3 8B, Llama-3 70B, Mixtral 8x7B, Mixtral 8x22B (per Anweisung angepasste oder Chatvarianten, sofern verfügbar).1 2 3
Erste Schritte mit Arctic
Das Snowflake AI Research Team hat kürzlich die „Arctic Embed“-Modellfamilie bekannt gegeben und auf Open Source umgestellt – sie erreicht beim MTEB-Abruf aktuelle Benchmarks. Wir freuen uns darauf, mit der Community zusammenzuarbeiten, während wir die nächste Generation in der Arctic-Modellfamilie entwickeln. Besuchen Sie uns vom 3. bis 6. Juni beim Data Cloud Summit, um mehr zu erfahren.
So können Sie noch heute in Arctic einsteigen:
- Besuchen Sie Hugging Face, um Arctic direkt herunterzuladen, und nutzen Sie unser Github-Repository, um Rezepte für Inferenz und Anpassung abzurufen.
- Für eine serverlose Erfahrung in Snowflake Cortex können Snowflake-Kunden, die eine Zahlungsmethode hinterlegt haben, noch bis zum 3. Juni kostenlos auf Snowflake Arctic zugreifen. Es gelten tägliche Limits.
- Demnächst können Sie auch über einen beliebigen Model Garden oder Modellkatalog auf Arctic zugreifen, darunter Amazon Web Services (AWS), Lamini, Microsoft Azure, der NVIDIA API-Katalog, Perplexity, Replicate und Together AI.
- Chatten Sie mit Arctic! Testen Sie jetzt eine Live-Demo in der Streamlit Community Cloud oder in Hugging Face Streamlit Spaces – mit einer API, die von unseren Freund:innen bei Replicate entwickelt wurde.
- Erhalten Sie beim ersten Community-Hackathon zum Thema Arctic Mentorings und gewinnen Sie Credits, um Ihre eigenen Arctic-basierten Anwendungen zu entwickeln.
Und vergessen Sie auch nicht die erste Ausgabe unseres Cookbook mit unseren zahlreichen Rezepten. Hier erfahren Sie mehr darüber, wie Sie auf kosteneffizienteste Weise eigene MoE-Modelle erstellen können.
Danksagungen
Wir möchten AWS für seine Zusammenarbeit und Partnerschaft beim Aufbau des Arctic-Trainingsclusters und der -infrastruktur danken. Und wir bedanken uns bei NVIDIA dafür, dass uns das Team bei der Arctic-Unterstützung im NVIDIA NIM TensorRT-LLM geholfen hat. Wir möchten außerdem der Open-Source-Community ganz herzlich dafür danken, dass sie die Modelle, Datasets und Dataset-Rezepteinblicke erstellt haben, mit denen dieser Release überhaupt erst möglich war. Und wir bedanken uns bei unseren Partnern bei AWS, Microsoft Azure, dem NVIDIA API-Katalog, Lamini, Perplexity, Replicate und Together AI für ihre Unterstützung bei der Bereitstellung von Arctic.
1. Die elf Metriken für Sprachverständnis und logisches Denken umfassen ARC-Easy, ARC-Challenge, BoolQ, CommonsenseQA, COPA, HellaSwag, LAMBADA, OpenBookQA, PIQA, RACE und WinoGrande.
2. Die Bewertungsergebnisse für HumanEval+/MBPP+ v0.1.0 wurden mithilfe von (1) Bigcode-Evaluation-Harness unter Verwendung modellspezifischer Chat-Vorlagen und ausgerichteter Nachbearbeitung sowie (2) Greedy Decoding ermittelt. Um Konsistenz zu gewährleisten, haben wir alle Modelle mit unserer Pipeline bewertet. Anschließend haben wir überprüft, ob unsere Bewertungsergebnisse mit dem EvalPlus Leaderboard übereinstimmen. Tatsächlich liefert unsere Pipeline für alle Modelle Zahlen, die einige Punkte über den Zahlen in EvalPlus liegen. Dadurch können wir zuversichtlich sagen, dass wir jedes Modell auf die bestmögliche Weise bewerten.
3. Die IFEval-Werte sind der Durchschnitt von prompt_level_strict_acc und inst_level_strict_acc
Autor:innen
