
Snowpark MLでSnowflakeの機械学習ワークフローを加速する

注:本記事は(2024年1月23日)に公開された(Accelerate Your Machine Learning Workflows in Snowflake with Snowpark ML )を機械翻訳により公開したものです。
機械学習(ML)を活用してデータからインサイトを引き出すこと目指す開発者や企業の多くが、運用の複雑さを前に立ち往生しています。SnowflakeにおけるエンドツーエンドMLワークフローのためのPythonライブラリおよび基盤インフラであるSnowpark MLを通して、私たちはMLモデルの構築と管理をより簡単かつ高速にしています。Snowpark MLを使用すると、データサイエンティストやMLエンジニアは、慣れ親しんだPythonフレームワークを、前処理や特徴量エンジニアリング、モデルトレーニングに使用し、データ移動やサイロ、ガバナンスのトレードオフを伴うことなく完全にSnowflake内で管理し実行できます。Fidelity、Spark New Zealand、Swire Coca Cola, USAなど、多くのお客様がSnowpark MLのパフォーマンスのメリットをすでに体験しています。
Snowflakeのお客様のMLユースケースをさらに加速させることを目指して、モデル開発のためのSnowpark MLモデリングを一般提供に、モデル管理のためのSnowparkモデルレジストリをパブリックプレビューに移行したことを発表いたします。
Snowpark MLモデリング特徴量エンジニアリング、前処理、モデルトレーニング
Snowpark MLモデリングAPIにより、データをSnowflakeの外部に移動することなく、特徴量エンジニアリングやモデルトレーニングにscikit-learnやXGBoostなどの一般的なPython MLフレームワークを使用できるようになります。
Snowpark MLモデリングのメリット:
- 特徴量エンジニアリングと前処理:一般的なscikit-learn前処理関数を分散実行することで、パフォーマンスとスケーラビリティを改善できます。
- モデルトレーニング:ストアドプロシージャやユーザー定義関数(UDF)の手動作成を必要とせずに、scikit-learn、XGBoost、LightGBMのモデルのトレーニングを加速し、分散ハイパーパラメーターの最適化(現在パブリックプレビュー中)を活用できます。
Snowpark MLは、バックグラウンドでSnowflakeのスケーラブルなコンピューティングプラットフォームを利用して、データ処理オペレーションを並列処理します。
Snowpark MLモデリングAPIを使用すると、一般的な前処理関数の多くを分散実装して、高いパフォーマンスとスケーラビリティを実現できます。大規模データセットを対象とする社内ベンチマークにおいて、StandardScalerやOneHotEncoderなどのデータ変換関数の実行、およびペアワイズ相関などのコンピュートを大量に消費するデータ処理で、大幅な高速化を実現しました。
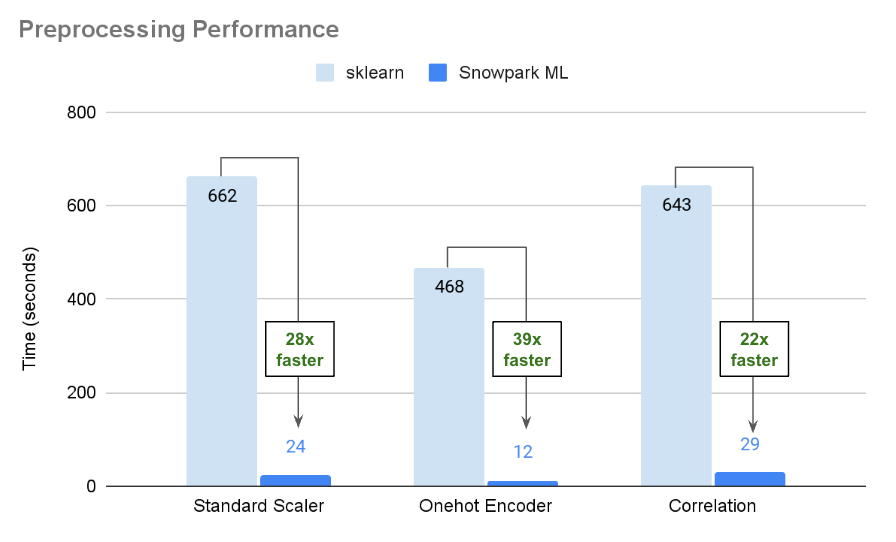
Snowpark MLは、scikit-learnのGridSearchCVとRandomSearchCVを使用するハイパーパラメーターの分散実行の最適化も実現し、シングルノードとマルチノードの両方のウェアハウスでモデル開発を加速させます。
これらのカスタム実装に加えて、Snowpark MLはscikit-learn、XGBoost、LightGBMのアルゴリズムの大半を、Snowflakeで実行されるこれらのクラスのビルトインラッパーを提供することで網羅しています。その結果、このようなPythonライブラリをSnowflakeに持ち込む際にストアドプロシージャやUDFの手動作成が不要になり、モデル開発ワークフローが簡素化されます。
Snowpark MLオペレーション:モデル管理
モデル開発から実稼働に至る経路の起点であるモデル管理とは、バージョン管理されたモデルアーティファクトとメタデータをガバナンスの利いたスケーラブルな方法で追跡する機能のことです。Snowpark MLオペレーションでは、お客様はSnowparkモデルレジストリを使用し、起源に関係なくモデルをSnowflake内で安全に管理し実行できます。
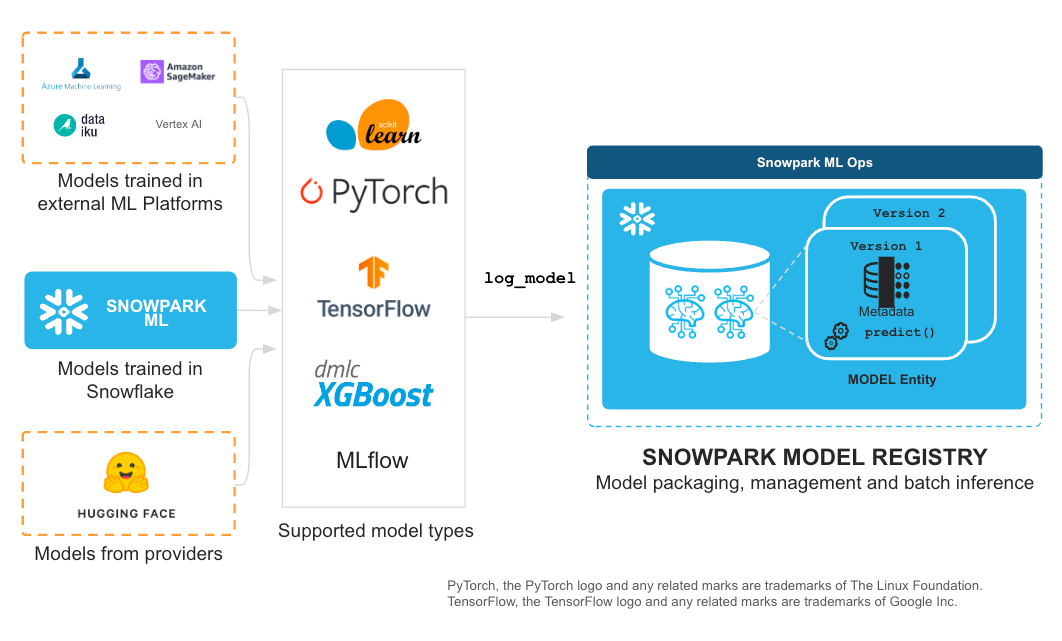
SnowparkモデルレジストリとMODELオブジェクト
Snowparkモデルレジストリの基盤となる新規MODELエンティティを使用して、ユーザーはSnowflakeの内外で作成された数種類のMLモデルを登録、管理し、使用できます。これはファーストクラスのスキーマレベルのSnowflakeオブジェクトであり、ロールベースのアクセス制御(RBAC)がフルサポートされる、バージョン管理されたMLモデルアーティファクト用コンテナと、PythonおよびSQLのAPIを提供します。
統一されたシンプルな log_model インターフェイス経由で、以下を含む数種類のモデルタイプを登録し、Snowflakeで管理できます。
- Scikit-Learn:
- Snowpark MLモデリング
- XGBoost
- Pytorch
- Tensorflow
- MLFlow(pyfuncインターフェイスをサポートするあらゆるMLFlowのモデルフレーバー)
- HuggingFaceパイプライン
上記のサポート対象モデルタイプのすべてで、log_model は実際的なデフォルト値を提供しますが、モデル登録時にフレームワーク特有のパラメーターで構成することもできます。
scikit-learnモデルの登録方法を以下に示します。
Snowparkモデルレジストリでは、Pythonに加えてSQLをMLモデルの基本的なカタログオペレーションに使用できます。
Snowparkモデルレジストリを使用することで、1つのモデルの異なるバージョンを表す複数のモデルアーティファクトを、構造化メタデータおよびトレーニングのモデルメトリクスと共に、単一の論理ユニット(つまり、単一のMODELインスタンス)としてSnowflake内で管理できるようになりました。SnowparkモデルレジストリAPIは、モデルのシンプルなカタログおよび検索のオペレーションを提供します。
モデル管理オペレーション
新しいMODELエンティティ内で、モデルアーティファクトはバージョン管理されたオブジェクトとして格納されます。各バージョンにはメタデータ、メトリクス、バージョン固有の関数(predictやcompleteなど)を格納できます。 その結果、ユーザーはユースケースやプロジェクトに固有のモデルを単一のエンティティ内で論理的に整理できるようになり、推論用途のスタンドアロンUDFの作成も不要となります。
また、ユーザーはモデルとバージョンの両方のレベルで構造化メタデータを指定し管理できます。構造化メタデータの指定は、Snowparkモデルレジストリの log_model API呼び出しの一部として、モデルまたはバージョンの登録時に行うこともできます。
推論
新しいMODELエンティティはネイティブ関数のサポートを通じてバッチ推論のユースケースを可能とし、推論専用のUDFの作成や管理も不要となります。
モデルのバージョンは、ユーザーが直接操作可能な複数の予測関数(predict()やpredict_proba()など)を備えることができます。
テーブルのデータに対して、SQLで同様にモデルを実行することもできます。
さらなる詳細やサポート対象の各モデルタイプのコード例は、Snowparkモデルレジストリドキュメントをご覧ください。
サクセスストーリー
Snowpark MLの機能を活用して、Snowflakeのお客様とパートナーの多くがAI/MLワークフローでSnowpark ML機能の大きな価値をすでに引き出しつつあります。
電気通信デジタルサービス企業のSpark New Zealandは、Snowpark MLを活用して、プリペイド方式モバイル事業Skinny Mobileの顧客のニーズと嗜好についての理解を深めています。
「Spark New Zealandの一部門であるSkinny Mobileは、エンドツーエンドのSnowflake統合アナリティクスプラットフォームを採用し、毎日10億行を超えるデータを取り込んでいます」と、Spark New ZealandのCloud Architect兼Product OwnerであるEric Bonhomme氏は述べています。「このプラットフォームには、Snowflakeのコンピューティングパワーを活用して機械学習モデルをトレーニングし、推論を実行するSnowpark MLが含まれています。Snowpark MLをSnowpark用に最適化されたウェアハウスと併用することで、モデル開発と運用のプロセスが合理化され、長時間クエリの実行や本来不要なデータ転送が排除され、効率、セキュリティ、データガバナンスが向上し、コストと時間の節減につながりました」
お客様だけでなく、Astronomer、Dataiku、Fosfor、Hex、Infostruxなど多くのパートナーが、Snowpark MLのメリットに目を留め、Snowpark MLとの統合機能を構築しています。
SnowflakeパートナーのFosforは、非常に優れたAIフレームワークとテンプレートを組み合わせてMLモデルの準備、構築、トレーニング、展開に供するエンタープライズ対応AIプラットフォームであるRefractをSnowpark MLと統合しています。
「FosforはSnowpark MLの変革を生み出す力を目の当たりにしました」と、FosforのAssociate DirectorであるGireesh Puthumana氏は語っています。「実に際立っているのは、まさしくSnowflake内で膨大なデータセットに対してMLモデルのトレーニングと推論を効率的に拡張できる点です。これは、迅速なトレーニングと展開、感銘的なコンピューティングパフォーマンスの見事な融合です。scikit-learnを彷彿とさせる馴染みのあるエクスペリエンスにより、データサイエンティストの学習の流れが簡素化されます。Fosfor上で利用されるSnowpark MLは、迅速な実験とエンドツーエンドのモデルガバナンスを促進しつつデータプライバシーを保護し、効率的かつ安全な機械学習の未来を約束します」
Snowpark MLの利用を始める
JupyterやVS Codeのようなオープンソースソリューション、Hexのようなマネージドサービスなどお好みのIDEを使用し、開発者向けドキュメントを参照してステップバイステップのクイックスタートでSnowpark MLについて詳しく学ぶことができます。
実際に動いているSnowpark MLにご関心のある方は、Snowpark Dayに参加して製品デモをチェックしてください。また、ウェビナーでは、Snowpark MLを既存のAI/ML対応のノートブックやプラットフォームに簡単に統合する方法をご紹介しています。ぜひご参加ください。
Authors


