Platform
The Snowflake platform is a fully managed service that’s truly easy to use, connected across your entire data estate and trusted by thousands of customers.
Bring agentic AI to all your data
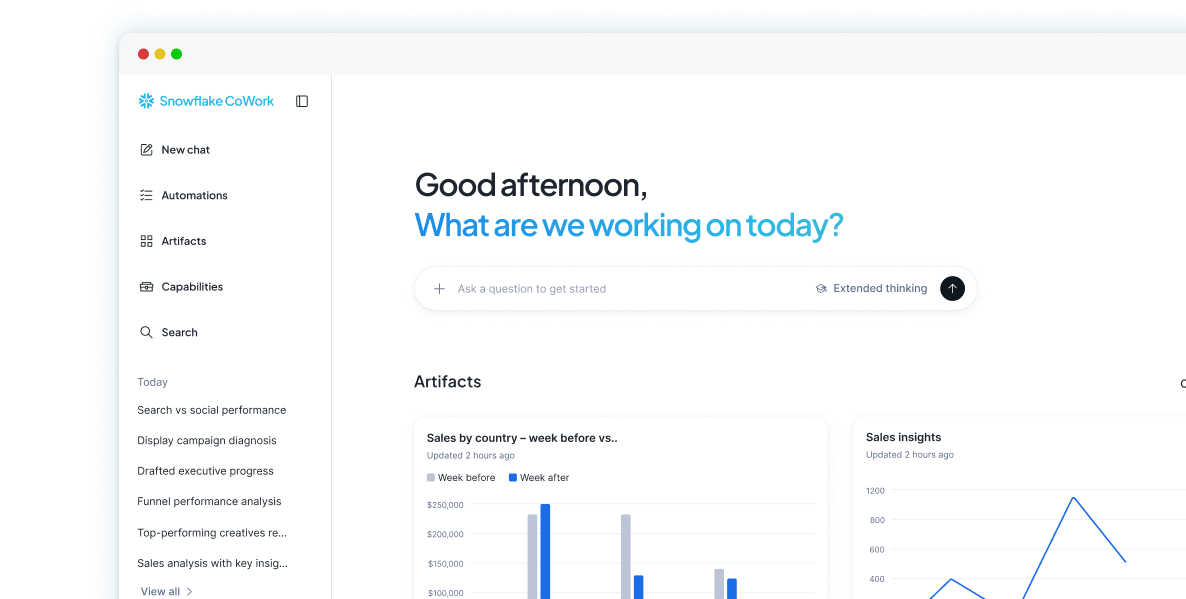
Ask anything with Snowflake CoWork. Build anything with Snowflake CoCo. Welcome to your one-stop shop for everyone in the enterprise.








PLATFORM
From ingesting and processing data to analyzing and modeling it, to building and sharing data and AI applications, Snowflake helps you innovate faster and do more with your data.
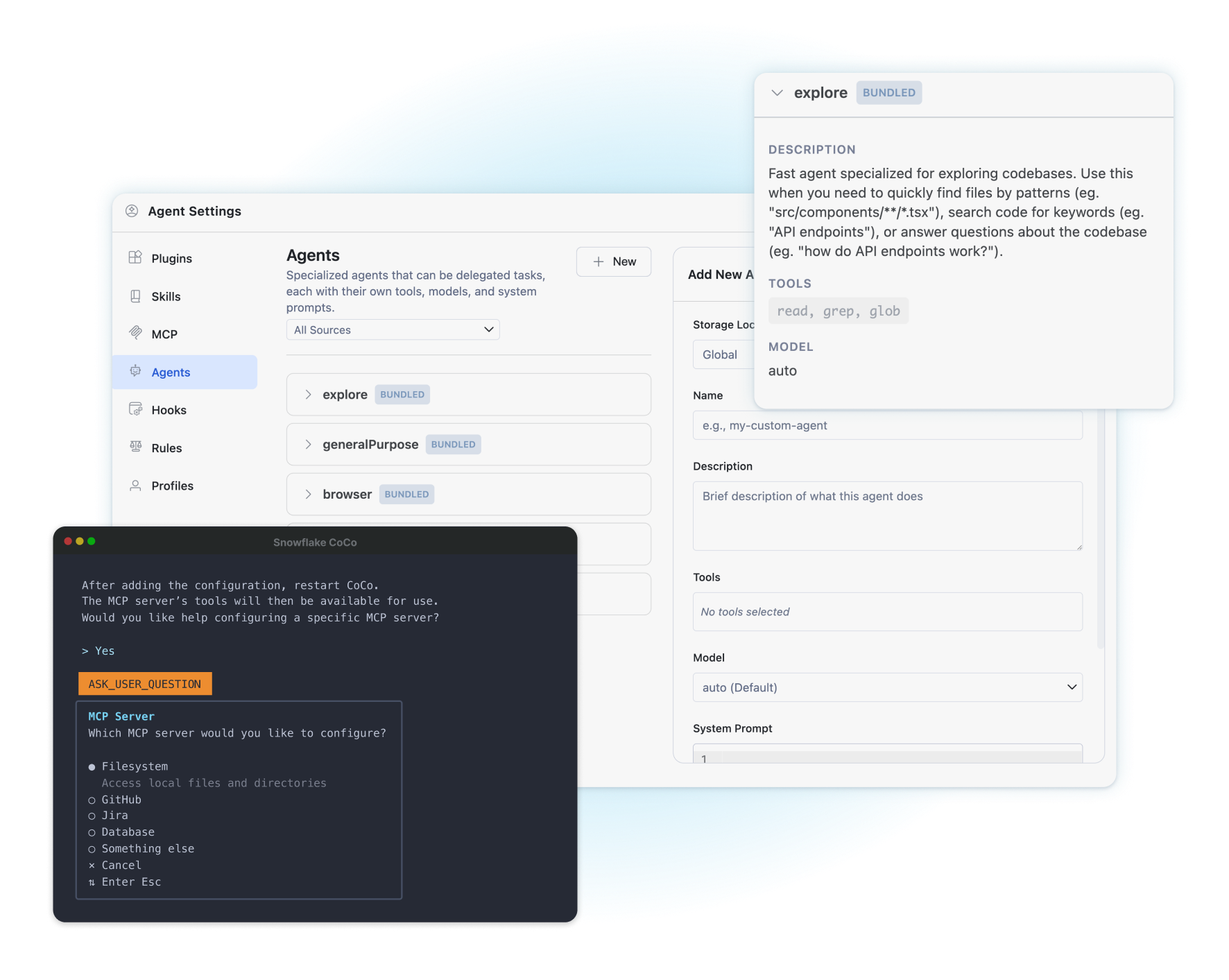
Save time on building, configuring and tuning infrastructure with an easy, fully managed platform that’s integrated across data types and clouds.
Snowflake’s rich ecosystem and interoperability with open table formats means you can maximize value from all your data, apps and models.
Support your most demanding workloads with always-on, unified security, governance, observability and disaster recovery, regardless of cloud or region.
THE AI DATA CLOUD
Accelerate end-to-end development with a governed AI coding agent that works wherever you build.
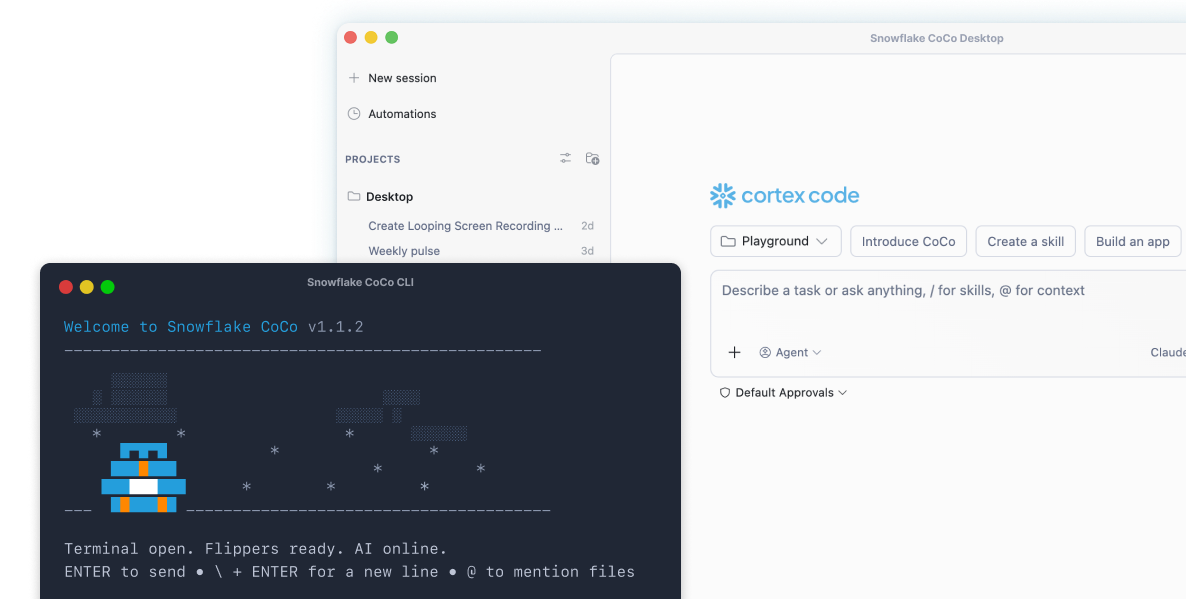
The personal work agent that takes you from context to clarity to action, all within Snowflake's perimeter.



CUSTOMERS
Booking.com Accelerates Travel Innovation with Cortex AI
By migrating away from Hadoop, Booking.com modernizes its data and AI, democratizes insights and connects millions of travelers to their dream trips.

Fanatics Personalizes the Fan Experience with Snowflake CoWork
Fanatics builds enterprise agents with Snowflake CoWork to unify billions of fan data points, democratize data access and enhance experiences for millions of fans.


Advertising, Media & Entertainment
Tampa Bay Rays Accelerate Time to Value by 75% with Snowflake and Coalesce
With Snowflake and Coalesce, the Tampa Bay Rays leverage data to enhance the fan experience, drive revenue and improve stadium operations.


Massachusetts Executive Office of Education Saves $1.5M Per Year and Fuels Data-Driven Policymaking
By migrating to Snowflake, the Executive Office of Education has modernized its data environment, equipping business users with a centralized analytics hub and improving time to insight for Massachusetts’ policymakers.


Landing AI Reduces Processing Time for Visual Data by 89% with Snowflake and AWS
Snowflake and AWS provide Landing AI with a powerful technical foundation that accelerates product development and allows them to deliver AI solutions that address customer concerns about data governance.

Amplify Impact

From integrated technologies to migration experts, maximize your Snowflake deployment with one of our partners.

Find reference architecture, level up your Snowflake skill set or see what open source Snowflake supports.

Explore our knowledge base to learn more about industry trends and best practices directly from experts at Snowflake.
Resources and News

Press Release

Press Release

Press Release












